3.4 Character Encoding *¶
In computers, all data is stored in binary form, and character char is no exception. To represent characters, we need to establish a "character set" that defines a one-to-one correspondence between each character and binary numbers. With a character set, computers can convert binary numbers to characters by looking up the table.
3.4.1 ASCII Character Set¶
ASCII code is the earliest character set, with the full name American Standard Code for Information Interchange. It uses 7 binary bits (the lower 7 bits of one byte) to represent a character, and can represent a maximum of 128 different characters. As shown in Figure 3-6, ASCII code includes uppercase and lowercase English letters, numbers 0 ~ 9, some punctuation marks, and some control characters (such as newline and tab).
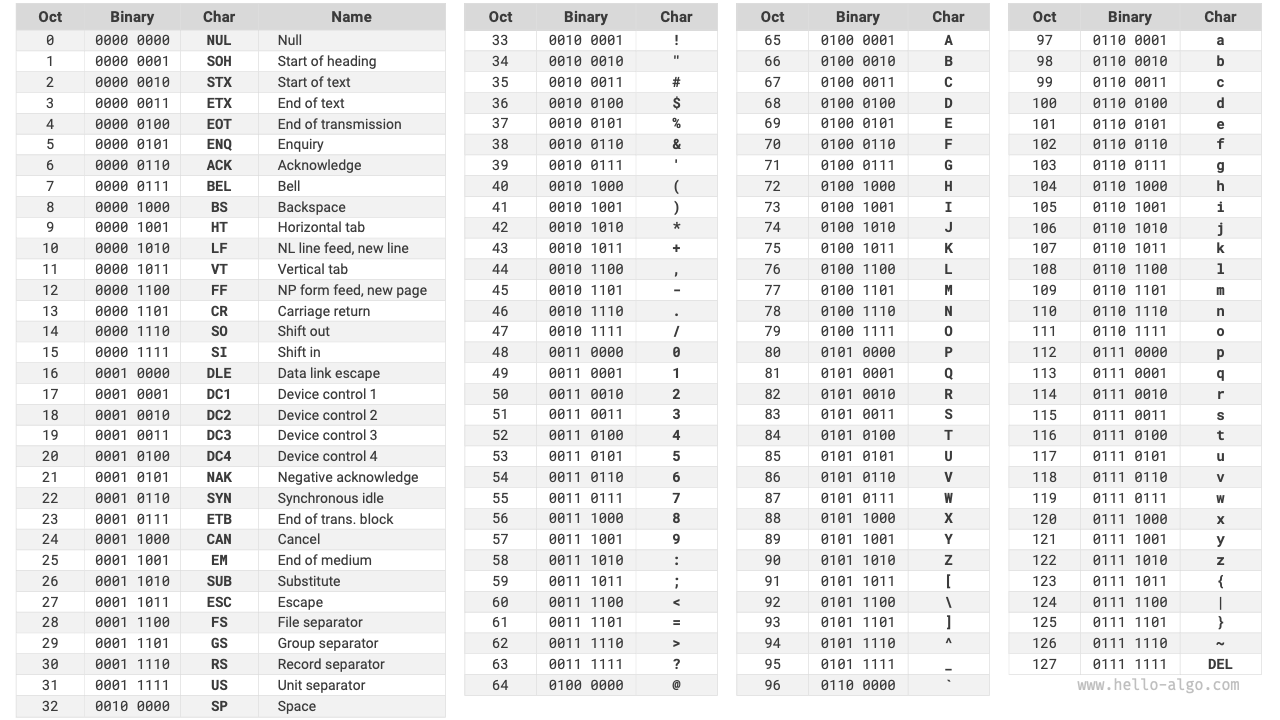
Figure 3-6 ASCII code
However, ASCII code can only represent English. With the globalization of computers, a character set called EASCII that can represent more languages emerged. It expands from the 7-bit basis of ASCII to 8 bits, and can represent 256 different characters.
Worldwide, a batch of EASCII character sets suitable for different regions have appeared successively. The first 128 characters of these character sets are unified as ASCII code, and the last 128 characters are defined differently to adapt to the needs of different languages.
3.4.2 GBK Character Set¶
Later, people found that EASCII still could not provide enough characters for many languages. For example, there are nearly one hundred thousand Chinese characters, and several thousand are used in everyday life. In 1980, the China National Standardization Administration released the GB2312 character set, which included 6,763 Chinese characters, basically meeting the needs of computer processing for Chinese.
However, GB2312 cannot handle some rare characters and traditional Chinese characters. The GBK character set is an extension based on GB2312, which includes a total of 21,886 Chinese characters. In the GBK encoding scheme, ASCII characters are represented using one byte, and Chinese characters are represented using two bytes.
3.4.3 Unicode Character Set¶
With the vigorous development of computer technology, character sets and encoding standards flourished, which brought many problems. On the one hand, these character sets generally only define characters for specific languages and cannot work normally in multilingual environments. On the other hand, multiple character set standards exist for the same language, and if two computers use different encoding standards, garbled characters will appear during information transmission.
Researchers of that era thought: If a sufficiently complete character set were released to include all languages and symbols in the world, wouldn't that solve problems in cross-language environments and eliminate garbled text? Driven by this idea, a large and comprehensive character set, Unicode, was born.
Unicode, or Unified Code, can theoretically accommodate over one million characters. It is committed to including characters from around the world into a unified character set, providing a universal character set to handle and display various language texts, reducing garbled character problems caused by different encoding standards. Since its release in 1991, Unicode has continuously expanded to include new languages and characters. As of September 2022, Unicode has included 149,186 characters, including characters, symbols, and even emojis from various languages.
As a universal character set, Unicode essentially assigns each character a unique "code point" (character identifier), whose range is U+0000 to U+10FFFF, forming a unified character numbering space. However, Unicode does not specify how to store these character code points in computers. We can't help but ask: when Unicode code points of multiple lengths appear simultaneously in a text, how does the system parse the characters? For example, given an encoding with a length of 2 bytes, how does the system determine whether it is one 2-byte character or two 1-byte characters?
For the above problem, a straightforward solution is to store all characters as equal-length encodings. As shown in Figure 3-7, each character in "Hello" occupies 1 byte, and each character in "算法" (algorithm) occupies 2 bytes. We can encode all characters in "Hello 算法" as 2 bytes in length by padding the high bits with 0. In this way, the system can parse one character every 2 bytes and restore the content of this phrase.

Figure 3-7 Unicode encoding example
However, ASCII code has already proven to us that encoding English only requires 1 byte. If the above scheme is adopted, the size of English text will be twice that under ASCII encoding, which is very wasteful of memory space. Therefore, we need a more efficient Unicode encoding method.
3.4.4 UTF-8 Encoding¶
Currently, UTF-8 has become the most widely used Unicode encoding method internationally. It is a variable-length encoding that uses 1 to 4 bytes to represent a character, depending on the complexity of the character. ASCII characters only require 1 byte, Latin and Greek letters require 2 bytes, commonly used Chinese characters require 3 bytes, and some other rare characters require 4 bytes.
The encoding rules of UTF-8 are not complicated and can be divided into the following two cases.
- For 1-byte characters, set the highest bit to \(0\), and set the remaining 7 bits to the Unicode code point. It is worth noting that ASCII characters occupy the first 128 code points in the Unicode character set. That is to say, UTF-8 encoding is backward compatible with ASCII code. This means we can use UTF-8 to parse very old ASCII code text.
- For characters with a length of \(n\) bytes (where \(n > 1\)), set the highest \(n\) bits of the first byte to \(1\), and set the \((n + 1)\)-th bit to \(0\); starting from the second byte, set the highest 2 bits of each byte to \(10\); use all remaining bits to fill in the Unicode code point of the character.
Figure 3-8 shows the UTF-8 encoding corresponding to "Hello 算法". It can be observed that since the highest \(n\) bits are all set to \(1\), the system can determine that the character length is \(n\) by counting the leading \(1\) bits.
But why set the highest 2 bits of all other bytes to \(10\)? In fact, this \(10\) can serve as a check symbol. Assuming the system starts parsing text from an incorrect byte, the \(10\) at the beginning of the byte can help the system quickly determine an anomaly.
The reason for using \(10\) as a check symbol is that under UTF-8 encoding rules, it is impossible for a character's highest two bits to be \(10\). This conclusion can be proven by contradiction: assuming the highest two bits of a character are \(10\), it means the length of the character is \(1\), corresponding to ASCII code. However, the highest bit of ASCII code should be \(0\), which contradicts the assumption.

Figure 3-8 UTF-8 encoding example
In addition to UTF-8, common encoding methods also include the following two.
- UTF-16 encoding: Uses 2 or 4 bytes to represent a character. All ASCII characters and commonly used non-English characters are represented with 2 bytes; a few characters need to use 4 bytes. For 2-byte characters, UTF-16 encoding is equal to the Unicode code point.
- UTF-32 encoding: Every character uses 4 bytes. This means that UTF-32 takes up more space than UTF-8 and UTF-16, especially for text with a high proportion of ASCII characters.
From the perspective of storage space occupation, using UTF-8 to represent English characters is very efficient because it only requires 1 byte; using UTF-16 encoding for some non-English characters (such as Chinese) will be more efficient because it only requires 2 bytes, while UTF-8 may require 3 bytes.
From a compatibility perspective, UTF-8 has the best universality, and many tools and libraries support UTF-8 first.
3.4.5 Character Encoding in Programming Languages¶
For many programming languages in the past, strings during program execution used internal encodings such as UTF-16 or UTF-32. Under these representations, we can often treat strings like arrays during processing, and this approach has the following advantages.
- Random access: UTF-16 encoded strings can be easily accessed randomly. UTF-8 is a variable-length encoding. To find the \(i\)-th character, we need to traverse from the beginning of the string to the \(i\)-th character, which requires \(O(n)\) time.
- Character counting: Similar to random access, calculating the length of a UTF-16 encoded string is also an \(O(1)\) operation. However, calculating the length of a UTF-8 encoded string requires traversing the entire string.
- String operations: Many string operations (such as splitting, joining, inserting, deleting, etc.) on UTF-16 encoded strings are easier to perform. Performing these operations on UTF-8 encoded strings usually requires additional calculations to ensure that invalid UTF-8 encoding is not generated.
In fact, the design of character encoding schemes for programming languages is a very interesting topic involving many factors.
- Java's
Stringtype uses UTF-16 encoding, with each character occupying 2 bytes. This is because at the beginning of Java language design, people believed that 16 bits were sufficient to represent all possible characters. However, this was an incorrect judgment. Later, the Unicode specification expanded beyond 16 bits, so characters in Java may now be represented by a pair of 16-bit values (called "surrogate pairs"). - The strings of JavaScript and TypeScript use UTF-16 encoding for reasons similar to Java. When Netscape first introduced the JavaScript language in 1995, Unicode was still in its early stages of development, and at that time, using 16-bit encoding was sufficient to represent all Unicode characters.
- C# uses UTF-16 encoding mainly because the .NET platform was designed by Microsoft, and many of Microsoft's technologies (including the Windows operating system) extensively use UTF-16 encoding.
Due to the underestimation of character quantities by the above programming languages, they had to adopt the "surrogate pair" method to represent Unicode characters with lengths exceeding 16 bits. This is a reluctant compromise. On the one hand, in strings containing surrogate pairs, one character may occupy 2 bytes or 4 bytes, thus losing the advantage of fixed-length encoding. On the other hand, handling surrogate pairs requires additional code, which increases the complexity and difficulty of debugging in programming.
For the above reasons, some programming languages have proposed different encoding schemes.
- Python's
struses Unicode encoding and adopts a flexible string representation where the stored character length depends on the largest Unicode code point in the string. If all characters in the string are ASCII characters, each character occupies 1 byte; if there are characters exceeding the ASCII range but all within the Basic Multilingual Plane (BMP), each character occupies 2 bytes; if there are characters exceeding the BMP, each character occupies 4 bytes. - Go language's
stringtype uses UTF-8 encoding internally. Go language also provides therunetype, which is used to represent a single Unicode code point. - Rust language's
strandStringtypes use UTF-8 encoding internally. Rust also provides thechartype for representing a single Unicode code point.
It should be noted that the above discussion is about how strings are stored in programming languages, which is different from how strings are stored in files or transmitted over networks. In file storage or network transmission, we usually encode strings into UTF-8 format to achieve optimal compatibility and space efficiency.