3.3 Number Encoding *¶
Tip
In this book, chapters marked with an asterisk * are optional readings. If you are short on time or find them challenging, you may skip these initially and return to them after completing the essential chapters.
3.3.1 Sign-Magnitude, 1's Complement, and 2's Complement¶
In the table from the previous section, we found that all integer types can represent one more negative number than positive numbers. For example, the byte range is \([-128, 127]\). This phenomenon is counterintuitive, and its underlying cause lies in sign-magnitude, 1's complement, and 2's complement representations.
First, it should be noted that numbers are stored in computers in the form of "2's complement". Before analyzing the reasons for this, let's first define these three concepts.
- Sign-magnitude: We treat the highest bit of the binary representation of a number as the sign bit, where \(0\) represents a positive number and \(1\) represents a negative number, and the remaining bits represent the value of the number.
- 1's complement: The 1's complement of a positive number is the same as its sign-magnitude. For a negative number, the 1's complement is obtained by inverting all bits except the sign bit of its sign-magnitude.
- 2's complement: The 2's complement of a positive number is the same as its sign-magnitude. For a negative number, the 2's complement is obtained by adding \(1\) to its 1's complement.
Figure 3-4 shows the conversion methods among sign-magnitude, 1's complement, and 2's complement.

Figure 3-4 Conversions among sign-magnitude, 1's complement, and 2's complement
Sign-magnitude, although the most intuitive, has some limitations. On one hand, the sign-magnitude of negative numbers cannot be directly used in operations. For example, calculating \(1 + (-2)\) in sign-magnitude yields \(-3\), which is clearly incorrect.
To solve this problem, computers introduced 1's complement. If we first convert sign-magnitude to 1's complement and calculate \(1 + (-2)\) in 1's complement, then convert the result back to sign-magnitude, we can obtain the correct result of \(-1\).
On the other hand, the sign-magnitude of the number zero has two representations, \(+0\) and \(-0\). This means that the number zero corresponds to two different binary encodings, which may cause ambiguity. For example, in conditional judgments, if we don't distinguish between positive zero and negative zero, it may lead to incorrect judgment results. If we want to handle the ambiguity of positive and negative zero, we need to introduce additional judgment operations, which may reduce the computational efficiency of the computer.
Like sign-magnitude, 1's complement also has the problem of positive and negative zero ambiguity. Therefore, computers further introduced 2's complement. Let's first observe the conversion process of negative zero from sign-magnitude to 1's complement to 2's complement:
Adding \(1\) to the 1's complement of negative zero produces a carry, but since the byte type has a length of only 8 bits, the \(1\) that overflows to the 9th bit is discarded. That is to say, the 2's complement of negative zero is \(0000 \; 0000\), which is the same as the 2's complement of positive zero. This means that in 2's complement representation, there is only one zero, and the positive and negative zero ambiguity is thus resolved.
One last question remains: the range of the byte type is \([-128, 127]\), so where does the extra negative number \(-128\) come from? We notice that all integers in the interval \([-127, +127]\) have corresponding sign-magnitude, 1's complement, and 2's complement, and sign-magnitude and 2's complement can be converted to each other.
However, the 2's complement \(1000 \; 0000\) is an exception, and it does not have a corresponding sign-magnitude. According to the conversion method, we get that the sign-magnitude of this 2's complement is \(0000 \; 0000\). This is clearly contradictory because this sign-magnitude represents the number \(0\), and its 2's complement should be itself. The computer specifies that this special 2's complement \(1000 \; 0000\) represents \(-128\). In fact, the result of calculating \((-1) + (-127)\) in 2's complement is \(-128\).
You may have noticed that all the above calculations are addition operations. This hints at an important fact: the hardware circuits inside computers are mainly designed based on addition operations. This is because addition operations are simpler to implement in hardware compared to other operations (such as multiplication, division, and subtraction), easier to parallelize, and have faster operation speeds.
Please note that this does not mean that computers can only perform addition. By combining addition with some basic logical operations, computers can implement various other mathematical operations. For example, calculating the subtraction \(a - b\) can be converted to calculating the addition \(a + (-b)\); calculating multiplication and division can be converted to calculating multiple additions or subtractions.
We can now summarize why computers use 2's complement: with 2's complement representation, computers can use the same circuits and operations to handle the addition of positive and negative numbers, without designing special hardware circuits for subtraction or separately handling the ambiguity of positive and negative zero. This greatly simplifies hardware design and improves efficiency.
The design of 2's complement is very ingenious. Due to space limitations, we will stop here. Interested readers are encouraged to explore further.
3.3.2 Floating-Point Number Encoding¶
Careful readers may have noticed: int and float have the same length, both are 4 bytes, but why does float have a much larger range than int? This is very counterintuitive because it stands to reason that float needs to represent decimals, so the range should be smaller.
In fact, this is because floating-point number float uses a different representation method. Let's denote a 32-bit binary number as:
According to the IEEE 754 standard, a 32-bit float consists of the following three parts.
- Sign bit \(\mathrm{S}\): occupies 1 bit, corresponding to \(b_{31}\).
- Exponent bit \(\mathrm{E}\): occupies 8 bits, corresponding to \(b_{30} b_{29} \ldots b_{23}\).
- Fraction bit \(\mathrm{N}\): occupies 23 bits, corresponding to \(b_{22} b_{21} \ldots b_0\).
The calculation method for the value corresponding to the binary float is:
Converted to decimal, the calculation formula is:
The range of each component is:
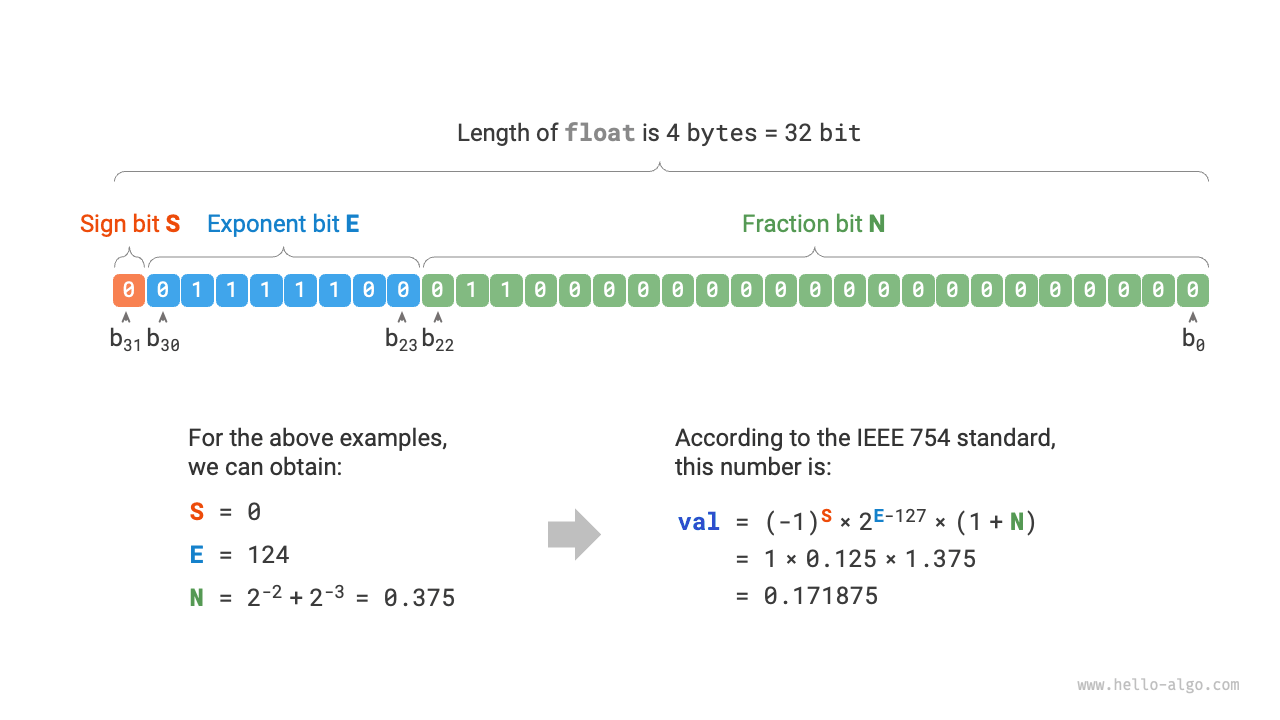
Figure 3-5 Calculation example of float under IEEE 754 standard
Observing Figure 3-5, given example data \(\mathrm{S} = 0\), \(\mathrm{E} = 124\), \(\mathrm{N} = 2^{-2} + 2^{-3} = 0.375\), we have:
Now we can answer the initial question: the representation of float includes an exponent bit, resulting in a range far greater than int. According to the above calculation, the maximum positive number that float can represent is \(2^{254 - 127} \times (2 - 2^{-23}) \approx 3.4 \times 10^{38}\), and the minimum negative number can be obtained by switching the sign bit.
Although floating-point number float expands the range, its side effect is sacrificing precision. The integer type int uses all 32 bits to represent numbers, and the numbers are evenly distributed; however, due to the existence of the exponent bit, the larger the value of floating-point number float, the larger the difference between two adjacent numbers tends to be.
As shown in Table 3-2, exponent bits \(\mathrm{E} = 0\) and \(\mathrm{E} = 255\) have special meanings, used to represent zero, infinity, \(\mathrm{NaN}\), etc.
Table 3-2 Meaning of exponent bits
| Exponent Bit E | Fraction Bit \(\mathrm{N} = 0\) | Fraction Bit \(\mathrm{N} \ne 0\) | Calculation Formula |
|---|---|---|---|
| \(0\) | \(\pm 0\) | Subnormal Number | \((-1)^{\mathrm{S}} \times 2^{-126} \times (0.\mathrm{N})\) |
| \(1, 2, \dots, 254\) | Normal Number | Normal Number | \((-1)^{\mathrm{S}} \times 2^{(\mathrm{E} -127)} \times (1.\mathrm{N})\) |
| \(255\) | \(\pm \infty\) | \(\mathrm{NaN}\) |
It is worth noting that subnormal numbers significantly improve the precision of floating-point numbers. The smallest positive normal number is \(2^{-126}\), and the smallest positive subnormal number is \(2^{-126} \times 2^{-23}\).
Double-precision double also uses a representation method similar to float, which will not be elaborated here.