6.3 Hash Algorithm¶
The previous two sections introduced the working principle of hash tables and the methods to handle hash collisions. However, both open addressing and separate chaining can only ensure that the hash table functions normally when hash collisions occur, but cannot reduce the frequency of hash collisions.
If hash collisions occur too frequently, the performance of the hash table will deteriorate drastically. As shown in Figure 6-8, for a separate chaining hash table, in the ideal case, the key-value pairs are evenly distributed across the buckets, achieving optimal query efficiency; in the worst case, all key-value pairs are stored in the same bucket, degrading the time complexity to \(O(n)\).
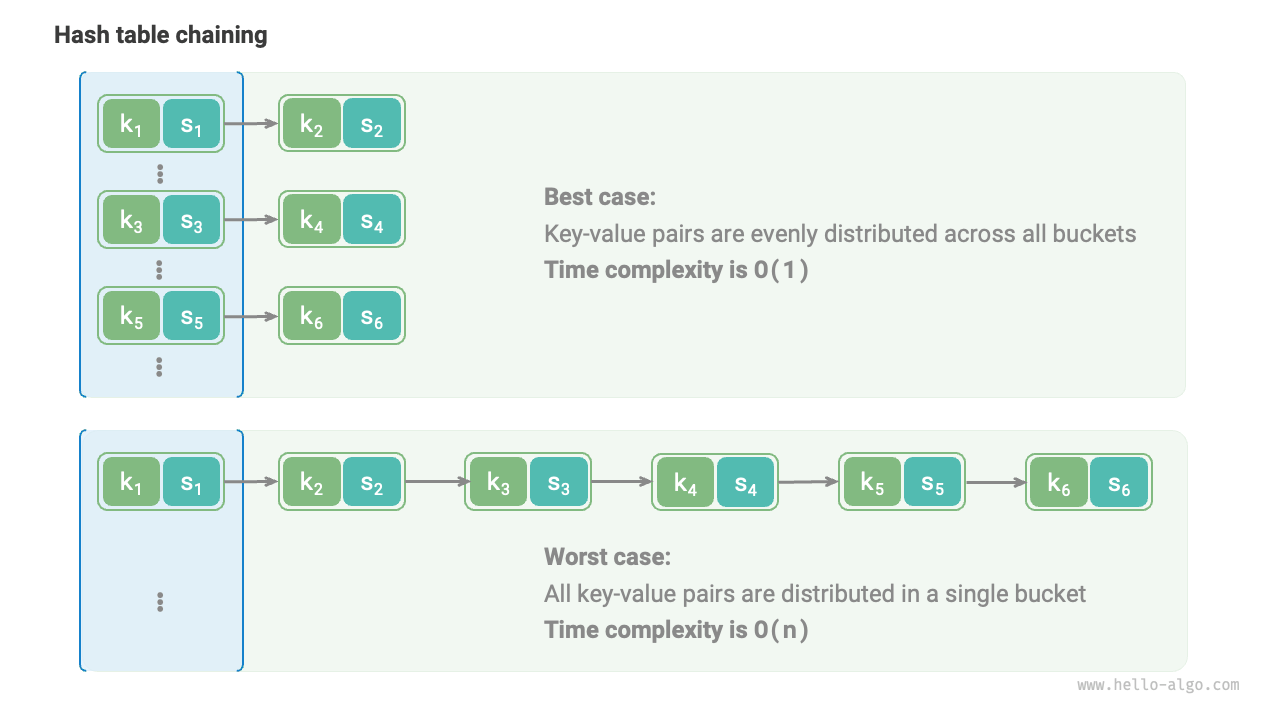
Figure 6-8 Ideal and worst cases of hash collisions
The distribution of key-value pairs is determined by the hash function. Recall the steps of the hash function: first compute the hash value, then take it modulo the array length:
Observing the above formula, when the hash table capacity capacity is fixed, the hash algorithm hash() determines the output value, thereby determining the distribution of key-value pairs in the hash table.
This means that, to reduce the probability of hash collisions, we should focus on the design of the hash algorithm hash().
6.3.1 Goals of Hash Algorithms¶
To build a hash table that is both fast and robust, a hash algorithm should have the following properties:
- Determinism: For the same input, the hash algorithm should always produce the same output. Only then can the hash table be reliable.
- High efficiency: The process of computing the hash value should be fast enough. The smaller the computational overhead, the more practical the hash table.
- Uniform distribution: The hash algorithm should ensure that key-value pairs are evenly distributed in the hash table. The more uniform the distribution, the lower the probability of hash collisions.
In fact, hash algorithms are not only used to implement hash tables but are also widely applied in other fields.
- Password storage: To protect the security of user passwords, systems usually do not store the plaintext passwords but rather the hash values of the passwords. When a user enters a password, the system calculates the hash value of the input and compares it with the stored hash value. If they match, the password is considered correct.
- Data integrity check: The data sender can calculate the hash value of the data and send it along; the receiver can recalculate the hash value of the received data and compare it with the received hash value. If they match, the data is considered intact.
For cryptographic applications, hash algorithms need stronger security properties to prevent reverse engineering, such as inferring the original password from a hash value.
- Unidirectionality: It should be impossible to deduce any information about the input data from the hash value.
- Collision resistance: It should be extremely difficult to find two different inputs that produce the same hash value.
- Avalanche effect: Minor changes in the input should lead to significant and unpredictable changes in the output.
Note that "uniform distribution" and "collision resistance" are two independent concepts. Satisfying uniform distribution does not necessarily mean collision resistance. For example, under random input key, the hash function key % 100 can produce a uniformly distributed output. However, this hash algorithm is too simple, and all key with the same last two digits will have the same output, making it easy to deduce a usable key from the hash value, thereby cracking the password.
6.3.2 Design of Hash Algorithms¶
The design of hash algorithms is a complex issue that requires consideration of many factors. However, for some less demanding scenarios, we can also design some simple hash algorithms.
- Additive hash: Add up the ASCII codes of each character in the input and use the total sum as the hash value.
- Multiplicative hash: Leverage the low correlation introduced by multiplication: multiply by a constant at each step and accumulate the ASCII codes of the characters into the hash value.
- XOR hash: Accumulate the hash value by XORing each element of the input data.
- Rotating hash: Accumulate the ASCII code of each character into a hash value, performing a rotation operation on the hash value before each accumulation.
def add_hash(key: str) -> int:
"""Additive hash"""
hash = 0
modulus = 1000000007
for c in key:
hash += ord(c)
return hash % modulus
def mul_hash(key: str) -> int:
"""Multiplicative hash"""
hash = 0
modulus = 1000000007
for c in key:
hash = 31 * hash + ord(c)
return hash % modulus
def xor_hash(key: str) -> int:
"""XOR hash"""
hash = 0
modulus = 1000000007
for c in key:
hash ^= ord(c)
return hash % modulus
def rot_hash(key: str) -> int:
"""Rotational hash"""
hash = 0
modulus = 1000000007
for c in key:
hash = (hash << 4) ^ (hash >> 28) ^ ord(c)
return hash % modulus
/* Additive hash */
int addHash(string key) {
long long hash = 0;
const int MODULUS = 1000000007;
for (unsigned char c : key) {
hash = (hash + (int)c) % MODULUS;
}
return (int)hash;
}
/* Multiplicative hash */
int mulHash(string key) {
long long hash = 0;
const int MODULUS = 1000000007;
for (unsigned char c : key) {
hash = (31 * hash + (int)c) % MODULUS;
}
return (int)hash;
}
/* XOR hash */
int xorHash(string key) {
int hash = 0;
const int MODULUS = 1000000007;
for (unsigned char c : key) {
hash ^= (int)c;
}
return hash & MODULUS;
}
/* Rotational hash */
int rotHash(string key) {
long long hash = 0;
const int MODULUS = 1000000007;
for (unsigned char c : key) {
hash = ((hash << 4) ^ (hash >> 28) ^ (int)c) % MODULUS;
}
return (int)hash;
}
/* Additive hash */
int addHash(String key) {
long hash = 0;
final int MODULUS = 1000000007;
for (char c : key.toCharArray()) {
hash = (hash + (int) c) % MODULUS;
}
return (int) hash;
}
/* Multiplicative hash */
int mulHash(String key) {
long hash = 0;
final int MODULUS = 1000000007;
for (char c : key.toCharArray()) {
hash = (31 * hash + (int) c) % MODULUS;
}
return (int) hash;
}
/* XOR hash */
int xorHash(String key) {
int hash = 0;
final int MODULUS = 1000000007;
for (char c : key.toCharArray()) {
hash ^= (int) c;
}
return hash & MODULUS;
}
/* Rotational hash */
int rotHash(String key) {
long hash = 0;
final int MODULUS = 1000000007;
for (char c : key.toCharArray()) {
hash = ((hash << 4) ^ (hash >> 28) ^ (int) c) % MODULUS;
}
return (int) hash;
}
/* Additive hash */
int AddHash(string key) {
long hash = 0;
const int MODULUS = 1000000007;
foreach (char c in key) {
hash = (hash + c) % MODULUS;
}
return (int)hash;
}
/* Multiplicative hash */
int MulHash(string key) {
long hash = 0;
const int MODULUS = 1000000007;
foreach (char c in key) {
hash = (31 * hash + c) % MODULUS;
}
return (int)hash;
}
/* XOR hash */
int XorHash(string key) {
int hash = 0;
const int MODULUS = 1000000007;
foreach (char c in key) {
hash ^= c;
}
return hash & MODULUS;
}
/* Rotational hash */
int RotHash(string key) {
long hash = 0;
const int MODULUS = 1000000007;
foreach (char c in key) {
hash = ((hash << 4) ^ (hash >> 28) ^ c) % MODULUS;
}
return (int)hash;
}
/* Additive hash */
func addHash(key string) int {
var hash int64
var modulus int64
modulus = 1000000007
for _, b := range []byte(key) {
hash = (hash + int64(b)) % modulus
}
return int(hash)
}
/* Multiplicative hash */
func mulHash(key string) int {
var hash int64
var modulus int64
modulus = 1000000007
for _, b := range []byte(key) {
hash = (31*hash + int64(b)) % modulus
}
return int(hash)
}
/* XOR hash */
func xorHash(key string) int {
hash := 0
modulus := 1000000007
for _, b := range []byte(key) {
fmt.Println(int(b))
hash ^= int(b)
hash = (31*hash + int(b)) % modulus
}
return hash & modulus
}
/* Rotational hash */
func rotHash(key string) int {
var hash int64
var modulus int64
modulus = 1000000007
for _, b := range []byte(key) {
hash = ((hash << 4) ^ (hash >> 28) ^ int64(b)) % modulus
}
return int(hash)
}
/* Additive hash */
func addHash(key: String) -> Int {
var hash = 0
let MODULUS = 1_000_000_007
for c in key {
for scalar in c.unicodeScalars {
hash = (hash + Int(scalar.value)) % MODULUS
}
}
return hash
}
/* Multiplicative hash */
func mulHash(key: String) -> Int {
var hash = 0
let MODULUS = 1_000_000_007
for c in key {
for scalar in c.unicodeScalars {
hash = (31 * hash + Int(scalar.value)) % MODULUS
}
}
return hash
}
/* XOR hash */
func xorHash(key: String) -> Int {
var hash = 0
let MODULUS = 1_000_000_007
for c in key {
for scalar in c.unicodeScalars {
hash ^= Int(scalar.value)
}
}
return hash & MODULUS
}
/* Rotational hash */
func rotHash(key: String) -> Int {
var hash = 0
let MODULUS = 1_000_000_007
for c in key {
for scalar in c.unicodeScalars {
hash = ((hash << 4) ^ (hash >> 28) ^ Int(scalar.value)) % MODULUS
}
}
return hash
}
/* Additive hash */
function addHash(key) {
let hash = 0;
const MODULUS = 1000000007;
for (const c of key) {
hash = (hash + c.charCodeAt(0)) % MODULUS;
}
return hash;
}
/* Multiplicative hash */
function mulHash(key) {
let hash = 0;
const MODULUS = 1000000007;
for (const c of key) {
hash = (31 * hash + c.charCodeAt(0)) % MODULUS;
}
return hash;
}
/* XOR hash */
function xorHash(key) {
let hash = 0;
const MODULUS = 1000000007;
for (const c of key) {
hash ^= c.charCodeAt(0);
}
return hash % MODULUS;
}
/* Rotational hash */
function rotHash(key) {
let hash = 0;
const MODULUS = 1000000007;
for (const c of key) {
hash = ((hash << 4) ^ (hash >> 28) ^ c.charCodeAt(0)) % MODULUS;
}
return hash;
}
/* Additive hash */
function addHash(key: string): number {
let hash = 0;
const MODULUS = 1000000007;
for (const c of key) {
hash = (hash + c.charCodeAt(0)) % MODULUS;
}
return hash;
}
/* Multiplicative hash */
function mulHash(key: string): number {
let hash = 0;
const MODULUS = 1000000007;
for (const c of key) {
hash = (31 * hash + c.charCodeAt(0)) % MODULUS;
}
return hash;
}
/* XOR hash */
function xorHash(key: string): number {
let hash = 0;
const MODULUS = 1000000007;
for (const c of key) {
hash ^= c.charCodeAt(0);
}
return hash % MODULUS;
}
/* Rotational hash */
function rotHash(key: string): number {
let hash = 0;
const MODULUS = 1000000007;
for (const c of key) {
hash = ((hash << 4) ^ (hash >> 28) ^ c.charCodeAt(0)) % MODULUS;
}
return hash;
}
/* Additive hash */
int addHash(String key) {
int hash = 0;
final int MODULUS = 1000000007;
for (int i = 0; i < key.length; i++) {
hash = (hash + key.codeUnitAt(i)) % MODULUS;
}
return hash;
}
/* Multiplicative hash */
int mulHash(String key) {
int hash = 0;
final int MODULUS = 1000000007;
for (int i = 0; i < key.length; i++) {
hash = (31 * hash + key.codeUnitAt(i)) % MODULUS;
}
return hash;
}
/* XOR hash */
int xorHash(String key) {
int hash = 0;
final int MODULUS = 1000000007;
for (int i = 0; i < key.length; i++) {
hash ^= key.codeUnitAt(i);
}
return hash & MODULUS;
}
/* Rotational hash */
int rotHash(String key) {
int hash = 0;
final int MODULUS = 1000000007;
for (int i = 0; i < key.length; i++) {
hash = ((hash << 4) ^ (hash >> 28) ^ key.codeUnitAt(i)) % MODULUS;
}
return hash;
}
/* Additive hash */
fn add_hash(key: &str) -> i32 {
let mut hash = 0_i64;
const MODULUS: i64 = 1000000007;
for c in key.chars() {
hash = (hash + c as i64) % MODULUS;
}
hash as i32
}
/* Multiplicative hash */
fn mul_hash(key: &str) -> i32 {
let mut hash = 0_i64;
const MODULUS: i64 = 1000000007;
for c in key.chars() {
hash = (31 * hash + c as i64) % MODULUS;
}
hash as i32
}
/* XOR hash */
fn xor_hash(key: &str) -> i32 {
let mut hash = 0_i64;
const MODULUS: i64 = 1000000007;
for c in key.chars() {
hash ^= c as i64;
}
(hash & MODULUS) as i32
}
/* Rotational hash */
fn rot_hash(key: &str) -> i32 {
let mut hash = 0_i64;
const MODULUS: i64 = 1000000007;
for c in key.chars() {
hash = ((hash << 4) ^ (hash >> 28) ^ c as i64) % MODULUS;
}
hash as i32
}
/* Additive hash */
int addHash(char *key) {
long long hash = 0;
const int MODULUS = 1000000007;
for (int i = 0; i < strlen(key); i++) {
hash = (hash + (unsigned char)key[i]) % MODULUS;
}
return (int)hash;
}
/* Multiplicative hash */
int mulHash(char *key) {
long long hash = 0;
const int MODULUS = 1000000007;
for (int i = 0; i < strlen(key); i++) {
hash = (31 * hash + (unsigned char)key[i]) % MODULUS;
}
return (int)hash;
}
/* XOR hash */
int xorHash(char *key) {
int hash = 0;
const int MODULUS = 1000000007;
for (int i = 0; i < strlen(key); i++) {
hash ^= (unsigned char)key[i];
}
return hash & MODULUS;
}
/* Rotational hash */
int rotHash(char *key) {
long long hash = 0;
const int MODULUS = 1000000007;
for (int i = 0; i < strlen(key); i++) {
hash = ((hash << 4) ^ (hash >> 28) ^ (unsigned char)key[i]) % MODULUS;
}
return (int)hash;
}
/* Additive hash */
fun addHash(key: String): Int {
var hash = 0L
val MODULUS = 1000000007
for (c in key.toCharArray()) {
hash = (hash + c.code) % MODULUS
}
return hash.toInt()
}
/* Multiplicative hash */
fun mulHash(key: String): Int {
var hash = 0L
val MODULUS = 1000000007
for (c in key.toCharArray()) {
hash = (31 * hash + c.code) % MODULUS
}
return hash.toInt()
}
/* XOR hash */
fun xorHash(key: String): Int {
var hash = 0
val MODULUS = 1000000007
for (c in key.toCharArray()) {
hash = hash xor c.code
}
return hash and MODULUS
}
/* Rotational hash */
fun rotHash(key: String): Int {
var hash = 0L
val MODULUS = 1000000007
for (c in key.toCharArray()) {
hash = ((hash shl 4) xor (hash shr 28) xor c.code.toLong()) % MODULUS
}
return hash.toInt()
}
### Additive hash ###
def add_hash(key)
hash = 0
modulus = 1_000_000_007
key.each_char { |c| hash += c.ord }
hash % modulus
end
### Multiplicative hash ###
def mul_hash(key)
hash = 0
modulus = 1_000_000_007
key.each_char { |c| hash = 31 * hash + c.ord }
hash % modulus
end
### XOR hash ###
def xor_hash(key)
hash = 0
modulus = 1_000_000_007
key.each_char { |c| hash ^= c.ord }
hash % modulus
end
### Rotational hash ###
def rot_hash(key)
hash = 0
modulus = 1_000_000_007
key.each_char { |c| hash = (hash << 4) ^ (hash >> 28) ^ c.ord }
hash % modulus
end
We can observe that the final step of each hash algorithm is to take the result modulo the large prime \(1000000007\), ensuring that the hash value stays within a suitable range. This naturally raises a question: why emphasize using a prime modulus, and what are the drawbacks of using a composite modulus?
In short: using a large prime as the modulus helps maximize the uniformity of hash values. Because a prime shares no common factors with other numbers, it can reduce periodic patterns introduced by the modulo operation and thus mitigate hash collisions.
For example, suppose we choose the composite number \(9\) as the modulus, which can be divided by \(3\), then all key divisible by \(3\) will be mapped to hash values \(0\), \(3\), \(6\).
If the input key values happen to follow this kind of arithmetic progression, the hash values will cluster, worsening hash collisions. Now suppose we replace modulus with the prime number \(13\). Because key and modulus share no common factors, the output hash values become much more evenly distributed.
It is worth noting that if the key is guaranteed to be randomly and uniformly distributed, then choosing a prime number or a composite number as the modulus can both produce uniformly distributed hash values. However, when the distribution of key has some periodicity, modulo a composite number is more likely to result in clustering.
In summary, we usually choose a prime number as the modulus, and this prime number should be large enough to eliminate periodic patterns as much as possible, enhancing the robustness of the hash algorithm.
6.3.3 Common Hash Algorithms¶
It is easy to see that the simple hash algorithms introduced above are fairly "fragile" and fall far short of the design goals of hash algorithms. For example, because addition and XOR are commutative, additive hash and XOR hash cannot distinguish strings with the same characters in a different order, which may worsen hash collisions and introduce security risks.
In practice, we usually use some standard hash algorithms, such as MD5, SHA-1, SHA-2, and SHA-3. They can map input data of any length to a fixed-length hash value.
Over the past century, hash algorithms have been in a continuous process of upgrading and optimization. Some researchers strive to improve the performance of hash algorithms, while others, including hackers, are dedicated to finding security issues in hash algorithms. Table 6-2 shows hash algorithms commonly used in practical applications.
- MD5 and SHA-1 have been successfully attacked multiple times and are thus abandoned in various security applications.
- SHA-2 series, especially SHA-256, is one of the most secure hash algorithms to date, with no successful attacks reported, hence commonly used in various security applications and protocols.
- SHA-3 has lower implementation costs and higher computational efficiency compared to SHA-2, but its current usage coverage is not as extensive as the SHA-2 series.
Table 6-2 Common hash algorithms
| MD5 | SHA-1 | SHA-2 | SHA-3 | |
|---|---|---|---|---|
| Release Year | 1992 | 1995 | 2002 | 2008 |
| Output Length | 128 bit | 160 bit | 256/512 bit | 224/256/384/512 bit |
| Hash Collisions | Frequent | Frequent | Rare | Rare |
| Security Level | Low, has been successfully attacked | Low, has been successfully attacked | High | High |
| Applications | Abandoned, still used for data integrity checks | Abandoned | Cryptocurrency transaction verification, digital signatures, etc. | Can be used to replace SHA-2 |
6.3.4 Hash Values in Data Structures¶
We know that hash table keys can be integers, floating-point numbers, strings, and other data types. Programming languages usually provide built-in hash algorithms for these types to compute bucket indices in a hash table. Taking Python as an example, we can call the hash() function to compute hash values for various data types.
- The hash values of integers and booleans are their own values.
- The calculation of hash values for floating-point numbers and strings is more complex, and interested readers are encouraged to study this on their own.
- The hash value of a tuple is obtained by hashing each of its elements and combining those results into a single hash value.
- An object's hash value is typically generated from its memory address. By overriding the object's hash method, it can instead be generated from the object's contents.
Tip
Be aware that the definition and methods of the built-in hash value calculation functions in different programming languages vary.
num = 3
hash_num = hash(num)
# Hash value of integer 3 is 3
bol = True
hash_bol = hash(bol)
# Hash value of boolean True is 1
dec = 3.14159
hash_dec = hash(dec)
# Hash value of decimal 3.14159 is 326484311674566659
str = "Hello 算法"
hash_str = hash(str)
# Hash value of string "Hello 算法" is 4617003410720528961
tup = (12836, "小哈")
hash_tup = hash(tup)
# Hash value of tuple (12836, '小哈') is 1029005403108185979
obj = ListNode(0)
hash_obj = hash(obj)
# Hash value of ListNode object at 0x1058fd810 is 274267521
int num = 3;
size_t hashNum = hash<int>()(num);
// Hash value of integer 3 is 3
bool bol = true;
size_t hashBol = hash<bool>()(bol);
// Hash value of boolean 1 is 1
double dec = 3.14159;
size_t hashDec = hash<double>()(dec);
// Hash value of decimal 3.14159 is 4614256650576692846
string str = "Hello 算法";
size_t hashStr = hash<string>()(str);
// Hash value of string "Hello 算法" is 15466937326284535026
// In C++, built-in std::hash() only provides hash values for basic data types
// Hash values for arrays and objects need to be implemented separately
int num = 3;
int hashNum = Integer.hashCode(num);
// Hash value of integer 3 is 3
boolean bol = true;
int hashBol = Boolean.hashCode(bol);
// Hash value of boolean true is 1231
double dec = 3.14159;
int hashDec = Double.hashCode(dec);
// Hash value of decimal 3.14159 is -1340954729
String str = "Hello 算法";
int hashStr = str.hashCode();
// Hash value of string "Hello 算法" is -727081396
Object[] arr = { 12836, "小哈" };
int hashTup = Arrays.hashCode(arr);
// Hash value of array [12836, 小哈] is 1151158
ListNode obj = new ListNode(0);
int hashObj = obj.hashCode();
// Hash value of ListNode object utils.ListNode@7dc5e7b4 is 2110121908
int num = 3;
int hashNum = num.GetHashCode();
// Hash value of integer 3 is 3;
bool bol = true;
int hashBol = bol.GetHashCode();
// Hash value of boolean true is 1;
double dec = 3.14159;
int hashDec = dec.GetHashCode();
// Hash value of decimal 3.14159 is -1340954729;
string str = "Hello 算法";
int hashStr = str.GetHashCode();
// Hash value of string "Hello 算法" is -586107568;
object[] arr = [12836, "小哈"];
int hashTup = arr.GetHashCode();
// Hash value of array [12836, 小哈] is 42931033;
ListNode obj = new(0);
int hashObj = obj.GetHashCode();
// Hash value of ListNode object 0 is 39053774;
let num = 3
let hashNum = num.hashValue
// Hash value of integer 3 is 9047044699613009734
let bol = true
let hashBol = bol.hashValue
// Hash value of boolean true is -4431640247352757451
let dec = 3.14159
let hashDec = dec.hashValue
// Hash value of decimal 3.14159 is -2465384235396674631
let str = "Hello 算法"
let hashStr = str.hashValue
// Hash value of string "Hello 算法" is -7850626797806988787
let arr = [AnyHashable(12836), AnyHashable("小哈")]
let hashTup = arr.hashValue
// Hash value of array [AnyHashable(12836), AnyHashable("小哈")] is -2308633508154532996
let obj = ListNode(x: 0)
let hashObj = obj.hashValue
// Hash value of ListNode object utils.ListNode is -2434780518035996159
int num = 3;
int hashNum = num.hashCode;
// Hash value of integer 3 is 34803
bool bol = true;
int hashBol = bol.hashCode;
// Hash value of boolean true is 1231
double dec = 3.14159;
int hashDec = dec.hashCode;
// Hash value of decimal 3.14159 is 2570631074981783
String str = "Hello 算法";
int hashStr = str.hashCode;
// Hash value of string "Hello 算法" is 468167534
List arr = [12836, "小哈"];
int hashArr = arr.hashCode;
// Hash value of array [12836, 小哈] is 976512528
ListNode obj = new ListNode(0);
int hashObj = obj.hashCode;
// Hash value of ListNode object Instance of 'ListNode' is 1033450432
use std::collections::hash_map::DefaultHasher;
use std::hash::{Hash, Hasher};
let num = 3;
let mut num_hasher = DefaultHasher::new();
num.hash(&mut num_hasher);
let hash_num = num_hasher.finish();
// Hash value of integer 3 is 568126464209439262
let bol = true;
let mut bol_hasher = DefaultHasher::new();
bol.hash(&mut bol_hasher);
let hash_bol = bol_hasher.finish();
// Hash value of boolean true is 4952851536318644461
let dec: f32 = 3.14159;
let mut dec_hasher = DefaultHasher::new();
dec.to_bits().hash(&mut dec_hasher);
let hash_dec = dec_hasher.finish();
// Hash value of decimal 3.14159 is 2566941990314602357
let str = "Hello 算法";
let mut str_hasher = DefaultHasher::new();
str.hash(&mut str_hasher);
let hash_str = str_hasher.finish();
// Hash value of string "Hello 算法" is 16092673739211250988
let arr = (&12836, &"小哈");
let mut tup_hasher = DefaultHasher::new();
arr.hash(&mut tup_hasher);
let hash_tup = tup_hasher.finish();
// Hash value of tuple (12836, "小哈") is 1885128010422702749
let node = ListNode::new(42);
let mut hasher = DefaultHasher::new();
node.borrow().val.hash(&mut hasher);
let hash = hasher.finish();
// Hash value of ListNode object RefCell { value: ListNode { val: 42, next: None } } is 15387811073369036852
val num = 3
val hashNum = num.hashCode()
// Hash value of integer 3 is 3
val bol = true
val hashBol = bol.hashCode()
// Hash value of boolean true is 1231
val dec = 3.14159
val hashDec = dec.hashCode()
// Hash value of decimal 3.14159 is -1340954729
val str = "Hello 算法"
val hashStr = str.hashCode()
// Hash value of string "Hello 算法" is -727081396
val arr = arrayOf<Any>(12836, "小哈")
val hashTup = arr.hashCode()
// Hash value of array [12836, 小哈] is 189568618
val obj = ListNode(0)
val hashObj = obj.hashCode()
// Hash value of ListNode object utils.ListNode@1d81eb93 is 495053715
num = 3
hash_num = num.hash
# Hash value of integer 3 is -4385856518450339636
bol = true
hash_bol = bol.hash
# Hash value of boolean true is -1617938112149317027
dec = 3.14159
hash_dec = dec.hash
# Hash value of decimal 3.14159 is -1479186995943067893
str = "Hello 算法"
hash_str = str.hash
# Hash value of string "Hello 算法" is -4075943250025831763
tup = [12836, '小哈']
hash_tup = tup.hash
# Hash value of tuple (12836, '小哈') is 1999544809202288822
obj = ListNode.new(0)
hash_obj = obj.hash
# Hash value of ListNode object #<ListNode:0x000078133140ab70> is 4302940560806366381
Visualized Execution
https://pythontutor.com/render.html#code=class%20ListNode%3A%0A%20%20%20%20%22%22%22%E9%93%BE%E8%A1%A8%E8%8A%82%E7%82%B9%E7%B1%BB%22%22%22%0A%20%20%20%20def%20__init__%28self,%20val%3A%20int%29%3A%0A%20%20%20%20%20%20%20%20self.val%3A%20int%20%3D%20val%20%20%23%20%E8%8A%82%E7%82%B9%E5%80%BC%0A%20%20%20%20%20%20%20%20self.next%3A%20ListNode%20%7C%20None%20%3D%20None%20%20%23%20%E5%90%8E%E7%BB%A7%E8%8A%82%E7%82%B9%E5%BC%95%E7%94%A8%0A%0A%22%22%22Driver%20Code%22%22%22%0Aif%20__name__%20%3D%3D%20%22__main__%22%3A%0A%20%20%20%20num%20%3D%203%0A%20%20%20%20hash_num%20%3D%20hash%28num%29%0A%20%20%20%20%23%20%E6%95%B4%E6%95%B0%203%20%E7%9A%84%E5%93%88%E5%B8%8C%E5%80%BC%E4%B8%BA%203%0A%0A%20%20%20%20bol%20%3D%20True%0A%20%20%20%20hash_bol%20%3D%20hash%28bol%29%0A%20%20%20%20%23%20%E5%B8%83%E5%B0%94%E9%87%8F%20True%20%E7%9A%84%E5%93%88%E5%B8%8C%E5%80%BC%E4%B8%BA%201%0A%0A%20%20%20%20dec%20%3D%203.14159%0A%20%20%20%20hash_dec%20%3D%20hash%28dec%29%0A%20%20%20%20%23%20%E5%B0%8F%E6%95%B0%203.14159%20%E7%9A%84%E5%93%88%E5%B8%8C%E5%80%BC%E4%B8%BA%20326484311674566659%0A%0A%20%20%20%20str%20%3D%20%22Hello%20%E7%AE%97%E6%B3%95%22%0A%20%20%20%20hash_str%20%3D%20hash%28str%29%0A%20%20%20%20%23%20%E5%AD%97%E7%AC%A6%E4%B8%B2%E2%80%9CHello%20%E7%AE%97%E6%B3%95%E2%80%9D%E7%9A%84%E5%93%88%E5%B8%8C%E5%80%BC%E4%B8%BA%204617003410720528961%0A%0A%20%20%20%20tup%20%3D%20%2812836,%20%22%E5%B0%8F%E5%93%88%22%29%0A%20%20%20%20hash_tup%20%3D%20hash%28tup%29%0A%20%20%20%20%23%20%E5%85%83%E7%BB%84%20%2812836,%20'%E5%B0%8F%E5%93%88'%29%20%E7%9A%84%E5%93%88%E5%B8%8C%E5%80%BC%E4%B8%BA%201029005403108185979%0A%0A%20%20%20%20obj%20%3D%20ListNode%280%29%0A%20%20%20%20hash_obj%20%3D%20hash%28obj%29%0A%20%20%20%20%23%20%E8%8A%82%E7%82%B9%E5%AF%B9%E8%B1%A1%20%3CListNode%20object%20at%200x1058fd810%3E%20%E7%9A%84%E5%93%88%E5%B8%8C%E5%80%BC%E4%B8%BA%20274267521&cumulative=false&curInstr=19&heapPrimitives=nevernest&mode=display&origin=opt-frontend.js&py=311&rawInputLstJSON=%5B%5D&textReferences=false
In many programming languages, only immutable objects can serve as the key in a hash table. If we use a list (dynamic array) as a key, when the contents of the list change, its hash value also changes, and we would no longer be able to find the original value in the hash table.
Although the member variables of a custom object (such as a linked list node) are mutable, it is hashable. This is because the hash value of an object is usually generated based on its memory address, and even if the contents of the object change, the memory address remains the same, so the hash value remains unchanged.
You might have noticed that the hash values output in different consoles are different. This is because the Python interpreter adds a random salt to the string hash function each time it starts up. This approach effectively prevents HashDoS attacks and enhances the security of the hash algorithm.