14.5 Unbounded Knapsack Problem¶
In this section, we first solve another common knapsack problem: the unbounded knapsack, and then explore a special case of it: the coin change problem.
14.5.1 Unbounded Knapsack Problem¶
Question
Given \(n\) items, where the weight of the \(i\)-th item is \(wgt[i-1]\) and its value is \(val[i-1]\), and a knapsack with capacity \(cap\). Each item can be selected multiple times. What is the maximum value that can be placed in the knapsack within the capacity limit? An example is shown in Figure 14-22.
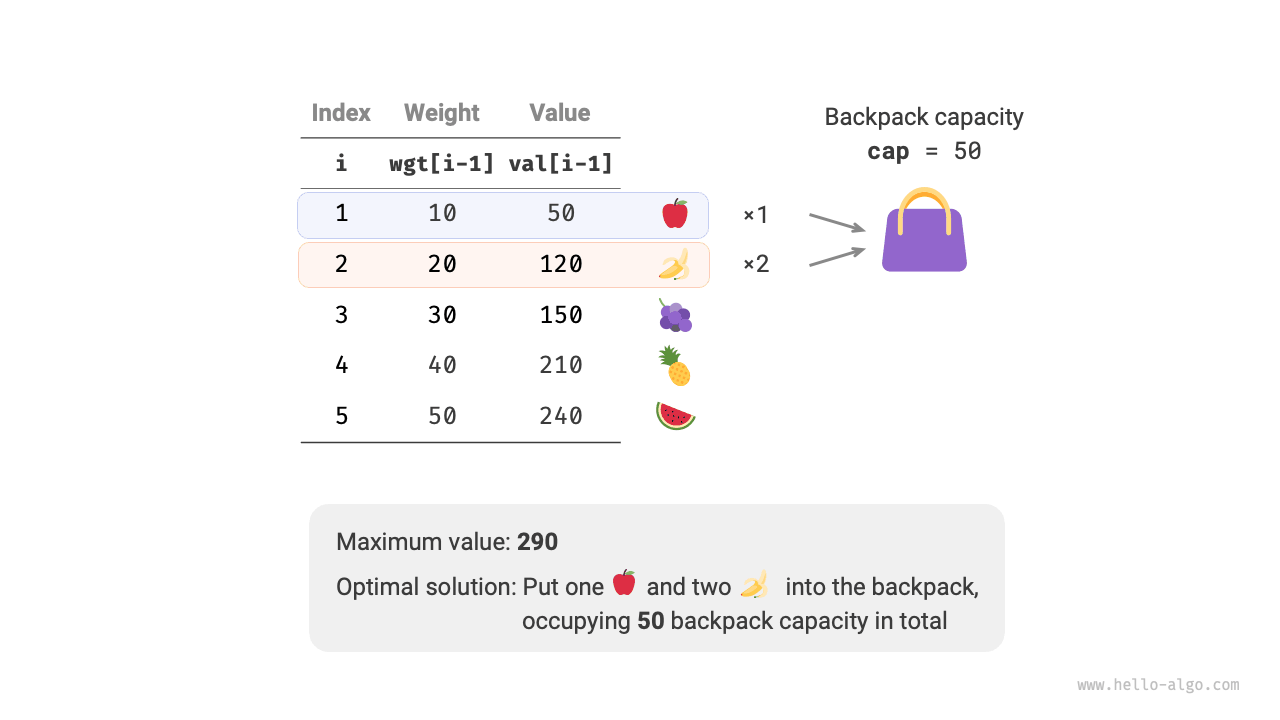
Figure 14-22 Example data for unbounded knapsack problem
1. Dynamic Programming Approach¶
The unbounded knapsack problem is very similar to the 0-1 knapsack problem, differing only in that there is no limit on the number of times an item can be selected.
- In the 0-1 knapsack problem, there is only one of each type of item, so after placing item \(i\) in the knapsack, we can only choose from the first \(i-1\) items.
- In the unbounded knapsack problem, the quantity of each type of item is unlimited, so after placing item \(i\) in the knapsack, we can still choose from the first \(i\) items.
Under the rules of the unbounded knapsack problem, the changes in state \([i, c]\) are divided into two cases.
- Not putting item \(i\): Same as the 0-1 knapsack problem, transfer to \([i-1, c]\).
- Putting item \(i\): Different from the 0-1 knapsack problem, transfer to \([i, c-wgt[i-1]]\).
Thus, the state transition equation becomes:
2. Code Implementation¶
Comparing the code for the two problems, there is one change in state transition from \(i-1\) to \(i\), with everything else identical:
def unbounded_knapsack_dp(wgt: list[int], val: list[int], cap: int) -> int:
"""Unbounded knapsack: Dynamic programming"""
n = len(wgt)
# Initialize dp table
dp = [[0] * (cap + 1) for _ in range(n + 1)]
# State transition
for i in range(1, n + 1):
for c in range(1, cap + 1):
if wgt[i - 1] > c:
# If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c]
else:
# The larger value between not selecting and selecting item i
dp[i][c] = max(dp[i - 1][c], dp[i][c - wgt[i - 1]] + val[i - 1])
return dp[n][cap]
/* Unbounded knapsack: Dynamic programming */
int unboundedKnapsackDP(vector<int> &wgt, vector<int> &val, int cap) {
int n = wgt.size();
// Initialize dp table
vector<vector<int>> dp(n + 1, vector<int>(cap + 1, 0));
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c];
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = max(dp[i - 1][c], dp[i][c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[n][cap];
}
/* Unbounded knapsack: Dynamic programming */
int unboundedKnapsackDP(int[] wgt, int[] val, int cap) {
int n = wgt.length;
// Initialize dp table
int[][] dp = new int[n + 1][cap + 1];
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c];
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = Math.max(dp[i - 1][c], dp[i][c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[n][cap];
}
/* Unbounded knapsack: Dynamic programming */
int UnboundedKnapsackDP(int[] wgt, int[] val, int cap) {
int n = wgt.Length;
// Initialize dp table
int[,] dp = new int[n + 1, cap + 1];
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i, c] = dp[i - 1, c];
} else {
// The larger value between not selecting and selecting item i
dp[i, c] = Math.Max(dp[i - 1, c], dp[i, c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[n, cap];
}
/* Unbounded knapsack: Dynamic programming */
func unboundedKnapsackDP(wgt, val []int, cap int) int {
n := len(wgt)
// Initialize dp table
dp := make([][]int, n+1)
for i := 0; i <= n; i++ {
dp[i] = make([]int, cap+1)
}
// State transition
for i := 1; i <= n; i++ {
for c := 1; c <= cap; c++ {
if wgt[i-1] > c {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i-1][c]
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = int(math.Max(float64(dp[i-1][c]), float64(dp[i][c-wgt[i-1]]+val[i-1])))
}
}
}
return dp[n][cap]
}
/* Unbounded knapsack: Dynamic programming */
func unboundedKnapsackDP(wgt: [Int], val: [Int], cap: Int) -> Int {
let n = wgt.count
// Initialize dp table
var dp = Array(repeating: Array(repeating: 0, count: cap + 1), count: n + 1)
// State transition
for i in 1 ... n {
for c in 1 ... cap {
if wgt[i - 1] > c {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c]
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = max(dp[i - 1][c], dp[i][c - wgt[i - 1]] + val[i - 1])
}
}
}
return dp[n][cap]
}
/* Unbounded knapsack: Dynamic programming */
function unboundedKnapsackDP(wgt, val, cap) {
const n = wgt.length;
// Initialize dp table
const dp = Array.from({ length: n + 1 }, () =>
Array.from({ length: cap + 1 }, () => 0)
);
// State transition
for (let i = 1; i <= n; i++) {
for (let c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c];
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = Math.max(
dp[i - 1][c],
dp[i][c - wgt[i - 1]] + val[i - 1]
);
}
}
}
return dp[n][cap];
}
/* Unbounded knapsack: Dynamic programming */
function unboundedKnapsackDP(
wgt: Array<number>,
val: Array<number>,
cap: number
): number {
const n = wgt.length;
// Initialize dp table
const dp = Array.from({ length: n + 1 }, () =>
Array.from({ length: cap + 1 }, () => 0)
);
// State transition
for (let i = 1; i <= n; i++) {
for (let c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c];
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = Math.max(
dp[i - 1][c],
dp[i][c - wgt[i - 1]] + val[i - 1]
);
}
}
}
return dp[n][cap];
}
/* Unbounded knapsack: Dynamic programming */
int unboundedKnapsackDP(List<int> wgt, List<int> val, int cap) {
int n = wgt.length;
// Initialize dp table
List<List<int>> dp = List.generate(n + 1, (index) => List.filled(cap + 1, 0));
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c];
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = max(dp[i - 1][c], dp[i][c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[n][cap];
}
/* Unbounded knapsack: Dynamic programming */
fn unbounded_knapsack_dp(wgt: &[i32], val: &[i32], cap: usize) -> i32 {
let n = wgt.len();
// Initialize dp table
let mut dp = vec![vec![0; cap + 1]; n + 1];
// State transition
for i in 1..=n {
for c in 1..=cap {
if wgt[i - 1] > c as i32 {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c];
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = std::cmp::max(dp[i - 1][c], dp[i][c - wgt[i - 1] as usize] + val[i - 1]);
}
}
}
return dp[n][cap];
}
/* Unbounded knapsack: Dynamic programming */
int unboundedKnapsackDP(int wgt[], int val[], int cap, int wgtSize) {
int n = wgtSize;
// Initialize dp table
int **dp = malloc((n + 1) * sizeof(int *));
for (int i = 0; i <= n; i++) {
dp[i] = calloc(cap + 1, sizeof(int));
}
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c];
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = myMax(dp[i - 1][c], dp[i][c - wgt[i - 1]] + val[i - 1]);
}
}
}
int res = dp[n][cap];
// Free memory
for (int i = 0; i <= n; i++) {
free(dp[i]);
}
return res;
}
/* Unbounded knapsack: Dynamic programming */
fun unboundedKnapsackDP(wgt: IntArray, _val: IntArray, cap: Int): Int {
val n = wgt.size
// Initialize dp table
val dp = Array(n + 1) { IntArray(cap + 1) }
// State transition
for (i in 1..n) {
for (c in 1..cap) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c]
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = max(dp[i - 1][c], dp[i][c - wgt[i - 1]] + _val[i - 1])
}
}
}
return dp[n][cap]
}
### Unbounded knapsack: dynamic programming ###
def unbounded_knapsack_dp(wgt, val, cap)
n = wgt.length
# Initialize dp table
dp = Array.new(n + 1) { Array.new(cap + 1, 0) }
# State transition
for i in 1...(n + 1)
for c in 1...(cap + 1)
if wgt[i - 1] > c
# If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c]
else
# The larger value between not selecting and selecting item i
dp[i][c] = [dp[i - 1][c], dp[i][c - wgt[i - 1]] + val[i - 1]].max
end
end
end
dp[n][cap]
end
3. Space Optimization¶
Since the current state is transferred from states on the left and above, after space optimization, each row in the \(dp\) table should be traversed in forward order.
This traversal order is exactly opposite to the 0-1 knapsack. Please refer to Figure 14-23 to understand the difference between the two.
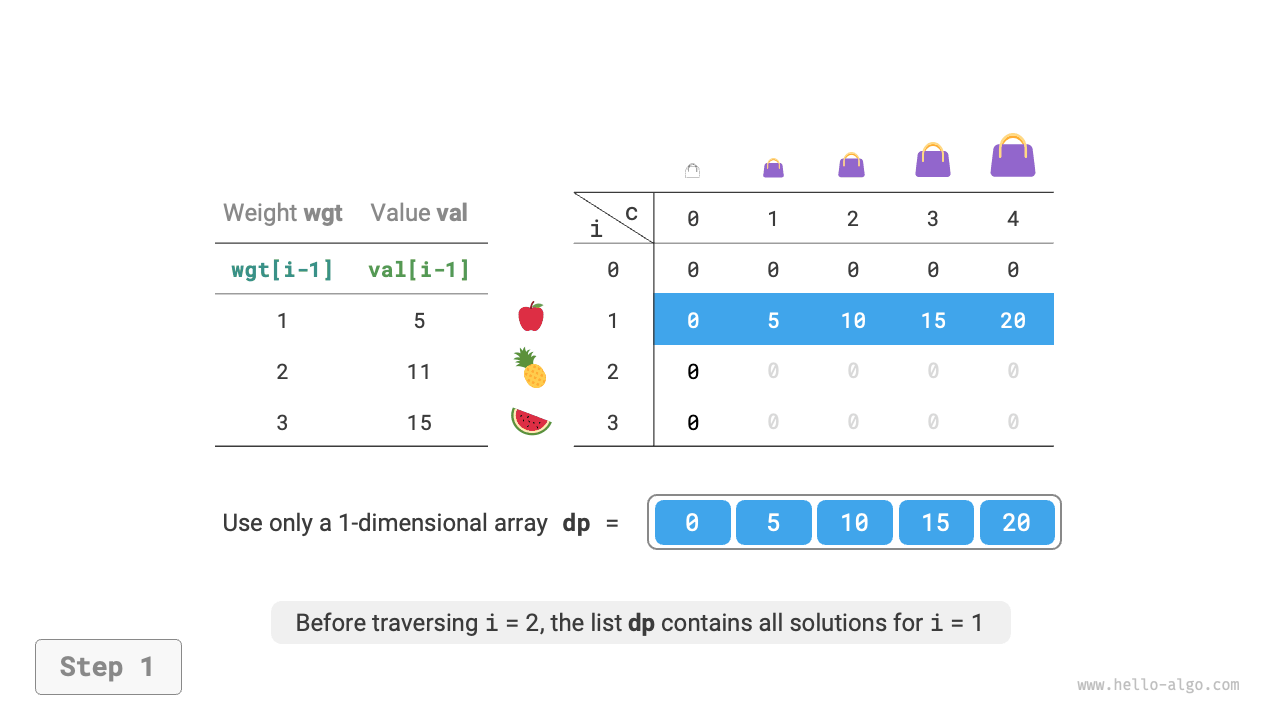
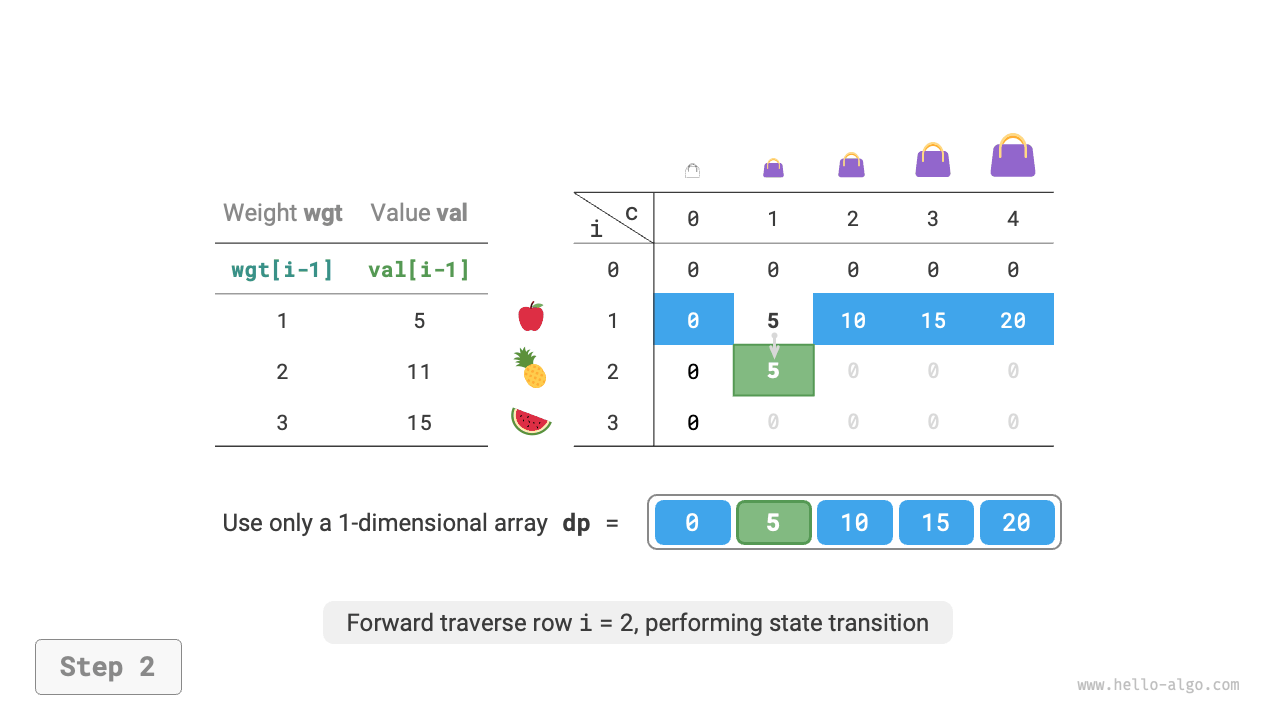

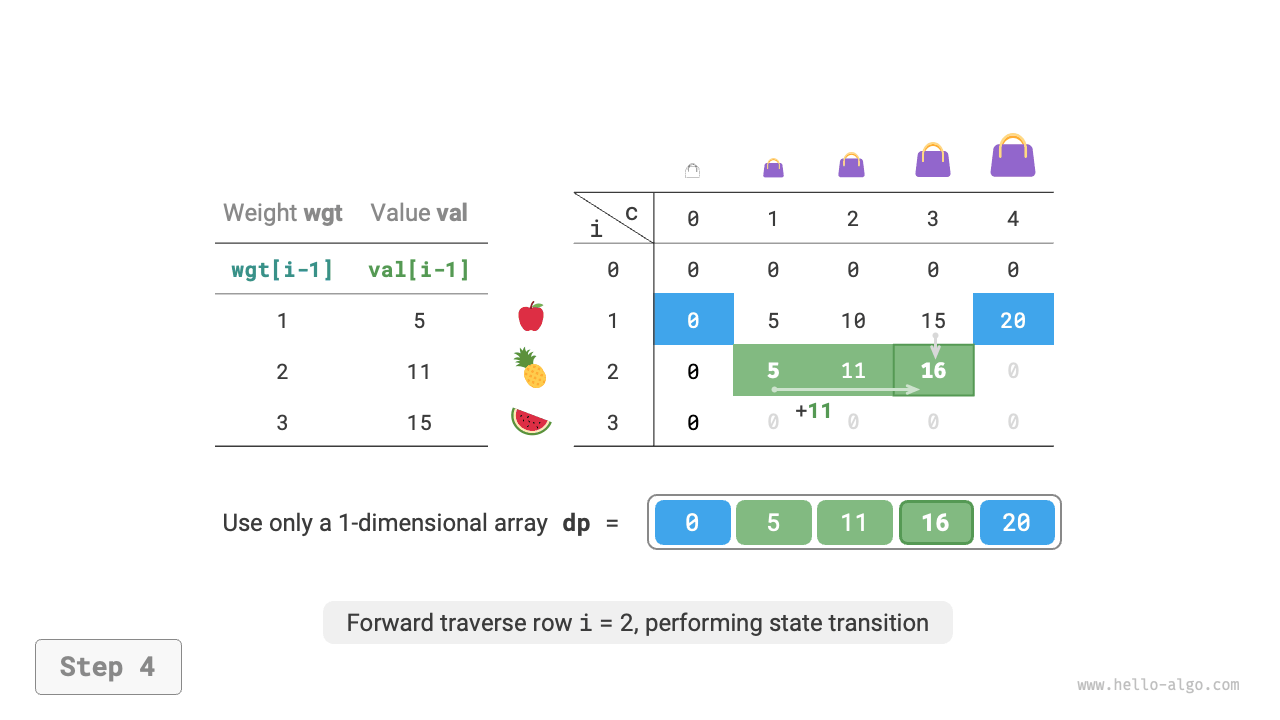


Figure 14-23 Space-optimized dynamic programming process for unbounded knapsack problem
The code implementation is relatively simple, just delete the first dimension of the array dp:
def unbounded_knapsack_dp_comp(wgt: list[int], val: list[int], cap: int) -> int:
"""Unbounded knapsack: Space-optimized dynamic programming"""
n = len(wgt)
# Initialize dp table
dp = [0] * (cap + 1)
# State transition
for i in range(1, n + 1):
# Traverse in forward order
for c in range(1, cap + 1):
if wgt[i - 1] > c:
# If exceeds knapsack capacity, don't select item i
dp[c] = dp[c]
else:
# The larger value between not selecting and selecting item i
dp[c] = max(dp[c], dp[c - wgt[i - 1]] + val[i - 1])
return dp[cap]
/* Unbounded knapsack: Space-optimized dynamic programming */
int unboundedKnapsackDPComp(vector<int> &wgt, vector<int> &val, int cap) {
int n = wgt.size();
// Initialize dp table
vector<int> dp(cap + 1, 0);
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[c] = dp[c];
} else {
// The larger value between not selecting and selecting item i
dp[c] = max(dp[c], dp[c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[cap];
}
/* Unbounded knapsack: Space-optimized dynamic programming */
int unboundedKnapsackDPComp(int[] wgt, int[] val, int cap) {
int n = wgt.length;
// Initialize dp table
int[] dp = new int[cap + 1];
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[c] = dp[c];
} else {
// The larger value between not selecting and selecting item i
dp[c] = Math.max(dp[c], dp[c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[cap];
}
/* Unbounded knapsack: Space-optimized dynamic programming */
int UnboundedKnapsackDPComp(int[] wgt, int[] val, int cap) {
int n = wgt.Length;
// Initialize dp table
int[] dp = new int[cap + 1];
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[c] = dp[c];
} else {
// The larger value between not selecting and selecting item i
dp[c] = Math.Max(dp[c], dp[c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[cap];
}
/* Unbounded knapsack: Space-optimized dynamic programming */
func unboundedKnapsackDPComp(wgt, val []int, cap int) int {
n := len(wgt)
// Initialize dp table
dp := make([]int, cap+1)
// State transition
for i := 1; i <= n; i++ {
for c := 1; c <= cap; c++ {
if wgt[i-1] > c {
// If exceeds knapsack capacity, don't select item i
dp[c] = dp[c]
} else {
// The larger value between not selecting and selecting item i
dp[c] = int(math.Max(float64(dp[c]), float64(dp[c-wgt[i-1]]+val[i-1])))
}
}
}
return dp[cap]
}
/* Unbounded knapsack: Space-optimized dynamic programming */
func unboundedKnapsackDPComp(wgt: [Int], val: [Int], cap: Int) -> Int {
let n = wgt.count
// Initialize dp table
var dp = Array(repeating: 0, count: cap + 1)
// State transition
for i in 1 ... n {
for c in 1 ... cap {
if wgt[i - 1] > c {
// If exceeds knapsack capacity, don't select item i
dp[c] = dp[c]
} else {
// The larger value between not selecting and selecting item i
dp[c] = max(dp[c], dp[c - wgt[i - 1]] + val[i - 1])
}
}
}
return dp[cap]
}
/* Unbounded knapsack: Space-optimized dynamic programming */
function unboundedKnapsackDPComp(wgt, val, cap) {
const n = wgt.length;
// Initialize dp table
const dp = Array.from({ length: cap + 1 }, () => 0);
// State transition
for (let i = 1; i <= n; i++) {
for (let c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[c] = dp[c];
} else {
// The larger value between not selecting and selecting item i
dp[c] = Math.max(dp[c], dp[c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[cap];
}
/* Unbounded knapsack: Space-optimized dynamic programming */
function unboundedKnapsackDPComp(
wgt: Array<number>,
val: Array<number>,
cap: number
): number {
const n = wgt.length;
// Initialize dp table
const dp = Array.from({ length: cap + 1 }, () => 0);
// State transition
for (let i = 1; i <= n; i++) {
for (let c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[c] = dp[c];
} else {
// The larger value between not selecting and selecting item i
dp[c] = Math.max(dp[c], dp[c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[cap];
}
/* Unbounded knapsack: Space-optimized dynamic programming */
int unboundedKnapsackDPComp(List<int> wgt, List<int> val, int cap) {
int n = wgt.length;
// Initialize dp table
List<int> dp = List.filled(cap + 1, 0);
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[c] = dp[c];
} else {
// The larger value between not selecting and selecting item i
dp[c] = max(dp[c], dp[c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[cap];
}
/* Unbounded knapsack: Space-optimized dynamic programming */
fn unbounded_knapsack_dp_comp(wgt: &[i32], val: &[i32], cap: usize) -> i32 {
let n = wgt.len();
// Initialize dp table
let mut dp = vec![0; cap + 1];
// State transition
for i in 1..=n {
for c in 1..=cap {
if wgt[i - 1] > c as i32 {
// If exceeds knapsack capacity, don't select item i
dp[c] = dp[c];
} else {
// The larger value between not selecting and selecting item i
dp[c] = std::cmp::max(dp[c], dp[c - wgt[i - 1] as usize] + val[i - 1]);
}
}
}
dp[cap]
}
/* Unbounded knapsack: Space-optimized dynamic programming */
int unboundedKnapsackDPComp(int wgt[], int val[], int cap, int wgtSize) {
int n = wgtSize;
// Initialize dp table
int *dp = calloc(cap + 1, sizeof(int));
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[c] = dp[c];
} else {
// The larger value between not selecting and selecting item i
dp[c] = myMax(dp[c], dp[c - wgt[i - 1]] + val[i - 1]);
}
}
}
int res = dp[cap];
// Free memory
free(dp);
return res;
}
/* Unbounded knapsack: Space-optimized dynamic programming */
fun unboundedKnapsackDPComp(
wgt: IntArray,
_val: IntArray,
cap: Int
): Int {
val n = wgt.size
// Initialize dp table
val dp = IntArray(cap + 1)
// State transition
for (i in 1..n) {
for (c in 1..cap) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[c] = dp[c]
} else {
// The larger value between not selecting and selecting item i
dp[c] = max(dp[c], dp[c - wgt[i - 1]] + _val[i - 1])
}
}
}
return dp[cap]
}
### Unbounded knapsack: space-optimized DP ###
def unbounded_knapsack_dp_comp(wgt, val, cap)
n = wgt.length
# Initialize dp table
dp = Array.new(cap + 1, 0)
# State transition
for i in 1...(n + 1)
# Traverse in forward order
for c in 1...(cap + 1)
if wgt[i -1] > c
# If exceeds knapsack capacity, don't select item i
dp[c] = dp[c]
else
# The larger value between not selecting and selecting item i
dp[c] = [dp[c], dp[c - wgt[i - 1]] + val[i - 1]].max
end
end
end
dp[cap]
end
14.5.2 Coin Change Problem¶
The knapsack problem represents a large class of dynamic programming problems and has many variants, such as the coin change problem.
Question
Given \(n\) types of coins, where the denomination of the \(i\)-th type of coin is \(coins[i - 1]\), and the target amount is \(amt\). Each type of coin can be selected multiple times. What is the minimum number of coins needed to make up the target amount? If it is impossible to make up the target amount, return \(-1\). An example is shown in Figure 14-24.
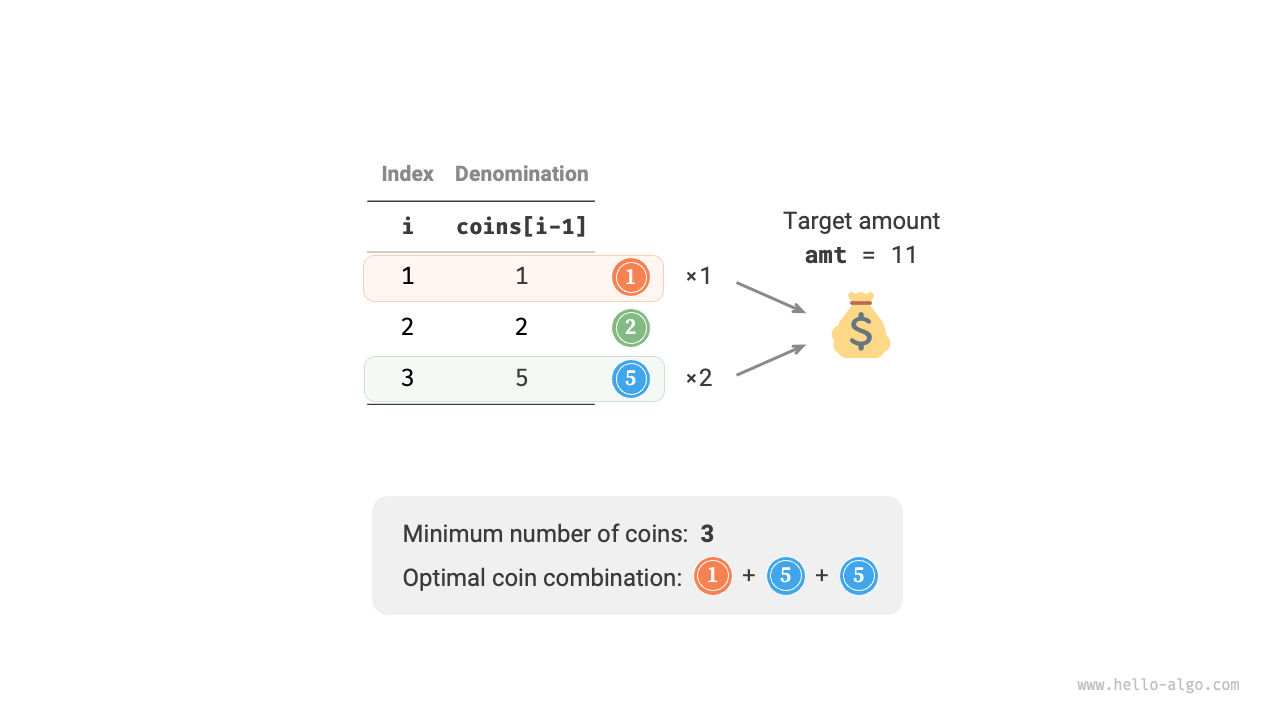
Figure 14-24 Example data for coin change problem
1. Dynamic Programming Approach¶
The coin change problem can be viewed as a special case of the unbounded knapsack problem, with the following connections and differences.
- The two problems can be converted to each other: "item" corresponds to "coin", "item weight" corresponds to "coin denomination", and "knapsack capacity" corresponds to "target amount".
- The optimization goals are opposite: the unbounded knapsack problem aims to maximize item value, while the coin change problem aims to minimize the number of coins.
- The unbounded knapsack problem seeks solutions "not exceeding" the knapsack capacity, while the coin change problem seeks solutions that "exactly" make up the target amount.
Step 1: Think about the decisions in each round, define the state, and thus obtain the \(dp\) table
State \([i, a]\) corresponds to the subproblem: the minimum number of coins among the first \(i\) types of coins that can make up amount \(a\), denoted as \(dp[i, a]\).
The two-dimensional \(dp\) table has size \((n+1) \times (amt+1)\).
Step 2: Identify the optimal substructure, and then derive the state transition equation
This problem differs from the unbounded knapsack problem in the following two aspects regarding the state transition equation.
- This problem seeks the minimum value, so the operator \(\max()\) needs to be changed to \(\min()\).
- The optimization target is the number of coins rather than item value, so when a coin is selected, simply add \(1\).
Step 3: Determine boundary conditions and state transition order
When the target amount is \(0\), the minimum number of coins needed to make it up is \(0\), so all \(dp[i, 0]\) in the first column equal \(0\).
When there are no coins, it is impossible to make up any amount \(> 0\), which is an invalid solution. To enable the \(\min()\) function in the state transition equation to identify and filter out invalid solutions, we consider using \(+ \infty\) to represent them, i.e., set all \(dp[0, a]\) in the first row to \(+ \infty\).
2. Code Implementation¶
Most programming languages do not provide a \(+ \infty\) variable, and can only use the maximum value of integer type int as a substitute. However, this can lead to integer overflow: the \(+ 1\) operation in the state transition equation may cause overflow.
For this reason, we use the number \(amt + 1\) to represent invalid solutions, because the maximum number of coins needed to make up \(amt\) is at most \(amt\). Before returning, check whether \(dp[n, amt]\) equals \(amt + 1\); if so, return \(-1\), indicating that the target amount cannot be made up. The code is as follows:
def coin_change_dp(coins: list[int], amt: int) -> int:
"""Coin change: Dynamic programming"""
n = len(coins)
MAX = amt + 1
# Initialize dp table
dp = [[0] * (amt + 1) for _ in range(n + 1)]
# State transition: first row and first column
for a in range(1, amt + 1):
dp[0][a] = MAX
# State transition: rest of the rows and columns
for i in range(1, n + 1):
for a in range(1, amt + 1):
if coins[i - 1] > a:
# If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a]
else:
# The smaller value between not selecting and selecting coin i
dp[i][a] = min(dp[i - 1][a], dp[i][a - coins[i - 1]] + 1)
return dp[n][amt] if dp[n][amt] != MAX else -1
/* Coin change: Dynamic programming */
int coinChangeDP(vector<int> &coins, int amt) {
int n = coins.size();
int MAX = amt + 1;
// Initialize dp table
vector<vector<int>> dp(n + 1, vector<int>(amt + 1, 0));
// State transition: first row and first column
for (int a = 1; a <= amt; a++) {
dp[0][a] = MAX;
}
// State transition: rest of the rows and columns
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a];
} else {
// The smaller value between not selecting and selecting coin i
dp[i][a] = min(dp[i - 1][a], dp[i][a - coins[i - 1]] + 1);
}
}
}
return dp[n][amt] != MAX ? dp[n][amt] : -1;
}
/* Coin change: Dynamic programming */
int coinChangeDP(int[] coins, int amt) {
int n = coins.length;
int MAX = amt + 1;
// Initialize dp table
int[][] dp = new int[n + 1][amt + 1];
// State transition: first row and first column
for (int a = 1; a <= amt; a++) {
dp[0][a] = MAX;
}
// State transition: rest of the rows and columns
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a];
} else {
// The smaller value between not selecting and selecting coin i
dp[i][a] = Math.min(dp[i - 1][a], dp[i][a - coins[i - 1]] + 1);
}
}
}
return dp[n][amt] != MAX ? dp[n][amt] : -1;
}
/* Coin change: Dynamic programming */
int CoinChangeDP(int[] coins, int amt) {
int n = coins.Length;
int MAX = amt + 1;
// Initialize dp table
int[,] dp = new int[n + 1, amt + 1];
// State transition: first row and first column
for (int a = 1; a <= amt; a++) {
dp[0, a] = MAX;
}
// State transition: rest of the rows and columns
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i, a] = dp[i - 1, a];
} else {
// The smaller value between not selecting and selecting coin i
dp[i, a] = Math.Min(dp[i - 1, a], dp[i, a - coins[i - 1]] + 1);
}
}
}
return dp[n, amt] != MAX ? dp[n, amt] : -1;
}
/* Coin change: Dynamic programming */
func coinChangeDP(coins []int, amt int) int {
n := len(coins)
max := amt + 1
// Initialize dp table
dp := make([][]int, n+1)
for i := 0; i <= n; i++ {
dp[i] = make([]int, amt+1)
}
// State transition: first row and first column
for a := 1; a <= amt; a++ {
dp[0][a] = max
}
// State transition: rest of the rows and columns
for i := 1; i <= n; i++ {
for a := 1; a <= amt; a++ {
if coins[i-1] > a {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i-1][a]
} else {
// The smaller value between not selecting and selecting coin i
dp[i][a] = int(math.Min(float64(dp[i-1][a]), float64(dp[i][a-coins[i-1]]+1)))
}
}
}
if dp[n][amt] != max {
return dp[n][amt]
}
return -1
}
/* Coin change: Dynamic programming */
func coinChangeDP(coins: [Int], amt: Int) -> Int {
let n = coins.count
let MAX = amt + 1
// Initialize dp table
var dp = Array(repeating: Array(repeating: 0, count: amt + 1), count: n + 1)
// State transition: first row and first column
for a in 1 ... amt {
dp[0][a] = MAX
}
// State transition: rest of the rows and columns
for i in 1 ... n {
for a in 1 ... amt {
if coins[i - 1] > a {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a]
} else {
// The smaller value between not selecting and selecting coin i
dp[i][a] = min(dp[i - 1][a], dp[i][a - coins[i - 1]] + 1)
}
}
}
return dp[n][amt] != MAX ? dp[n][amt] : -1
}
/* Coin change: Dynamic programming */
function coinChangeDP(coins, amt) {
const n = coins.length;
const MAX = amt + 1;
// Initialize dp table
const dp = Array.from({ length: n + 1 }, () =>
Array.from({ length: amt + 1 }, () => 0)
);
// State transition: first row and first column
for (let a = 1; a <= amt; a++) {
dp[0][a] = MAX;
}
// State transition: rest of the rows and columns
for (let i = 1; i <= n; i++) {
for (let a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a];
} else {
// The smaller value between not selecting and selecting coin i
dp[i][a] = Math.min(dp[i - 1][a], dp[i][a - coins[i - 1]] + 1);
}
}
}
return dp[n][amt] !== MAX ? dp[n][amt] : -1;
}
/* Coin change: Dynamic programming */
function coinChangeDP(coins: Array<number>, amt: number): number {
const n = coins.length;
const MAX = amt + 1;
// Initialize dp table
const dp = Array.from({ length: n + 1 }, () =>
Array.from({ length: amt + 1 }, () => 0)
);
// State transition: first row and first column
for (let a = 1; a <= amt; a++) {
dp[0][a] = MAX;
}
// State transition: rest of the rows and columns
for (let i = 1; i <= n; i++) {
for (let a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a];
} else {
// The smaller value between not selecting and selecting coin i
dp[i][a] = Math.min(dp[i - 1][a], dp[i][a - coins[i - 1]] + 1);
}
}
}
return dp[n][amt] !== MAX ? dp[n][amt] : -1;
}
/* Coin change: Dynamic programming */
int coinChangeDP(List<int> coins, int amt) {
int n = coins.length;
int MAX = amt + 1;
// Initialize dp table
List<List<int>> dp = List.generate(n + 1, (index) => List.filled(amt + 1, 0));
// State transition: first row and first column
for (int a = 1; a <= amt; a++) {
dp[0][a] = MAX;
}
// State transition: rest of the rows and columns
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a];
} else {
// The smaller value between not selecting and selecting coin i
dp[i][a] = min(dp[i - 1][a], dp[i][a - coins[i - 1]] + 1);
}
}
}
return dp[n][amt] != MAX ? dp[n][amt] : -1;
}
/* Coin change: Dynamic programming */
fn coin_change_dp(coins: &[i32], amt: usize) -> i32 {
let n = coins.len();
let max = amt + 1;
// Initialize dp table
let mut dp = vec![vec![0; amt + 1]; n + 1];
// State transition: first row and first column
for a in 1..=amt {
dp[0][a] = max;
}
// State transition: rest of the rows and columns
for i in 1..=n {
for a in 1..=amt {
if coins[i - 1] > a as i32 {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a];
} else {
// The smaller value between not selecting and selecting coin i
dp[i][a] = std::cmp::min(dp[i - 1][a], dp[i][a - coins[i - 1] as usize] + 1);
}
}
}
if dp[n][amt] != max {
return dp[n][amt] as i32;
} else {
-1
}
}
/* Coin change: Dynamic programming */
int coinChangeDP(int coins[], int amt, int coinsSize) {
int n = coinsSize;
int MAX = amt + 1;
// Initialize dp table
int **dp = malloc((n + 1) * sizeof(int *));
for (int i = 0; i <= n; i++) {
dp[i] = calloc(amt + 1, sizeof(int));
}
// State transition: first row and first column
for (int a = 1; a <= amt; a++) {
dp[0][a] = MAX;
}
// State transition: rest of the rows and columns
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a];
} else {
// The smaller value between not selecting and selecting coin i
dp[i][a] = myMin(dp[i - 1][a], dp[i][a - coins[i - 1]] + 1);
}
}
}
int res = dp[n][amt] != MAX ? dp[n][amt] : -1;
// Free memory
for (int i = 0; i <= n; i++) {
free(dp[i]);
}
free(dp);
return res;
}
/* Coin change: Dynamic programming */
fun coinChangeDP(coins: IntArray, amt: Int): Int {
val n = coins.size
val MAX = amt + 1
// Initialize dp table
val dp = Array(n + 1) { IntArray(amt + 1) }
// State transition: first row and first column
for (a in 1..amt) {
dp[0][a] = MAX
}
// State transition: rest of the rows and columns
for (i in 1..n) {
for (a in 1..amt) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a]
} else {
// The smaller value between not selecting and selecting coin i
dp[i][a] = min(dp[i - 1][a], dp[i][a - coins[i - 1]] + 1)
}
}
}
return if (dp[n][amt] != MAX) dp[n][amt] else -1
}
### Coin change: dynamic programming ###
def coin_change_dp(coins, amt)
n = coins.length
_MAX = amt + 1
# Initialize dp table
dp = Array.new(n + 1) { Array.new(amt + 1, 0) }
# State transition: first row and first column
(1...(amt + 1)).each { |a| dp[0][a] = _MAX }
# State transition: rest of the rows and columns
for i in 1...(n + 1)
for a in 1...(amt + 1)
if coins[i - 1] > a
# If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a]
else
# The smaller value between not selecting and selecting coin i
dp[i][a] = [dp[i - 1][a], dp[i][a - coins[i - 1]] + 1].min
end
end
end
dp[n][amt] != _MAX ? dp[n][amt] : -1
end
Figure 14-25 shows the dynamic programming process for coin change, which is very similar to the unbounded knapsack problem.
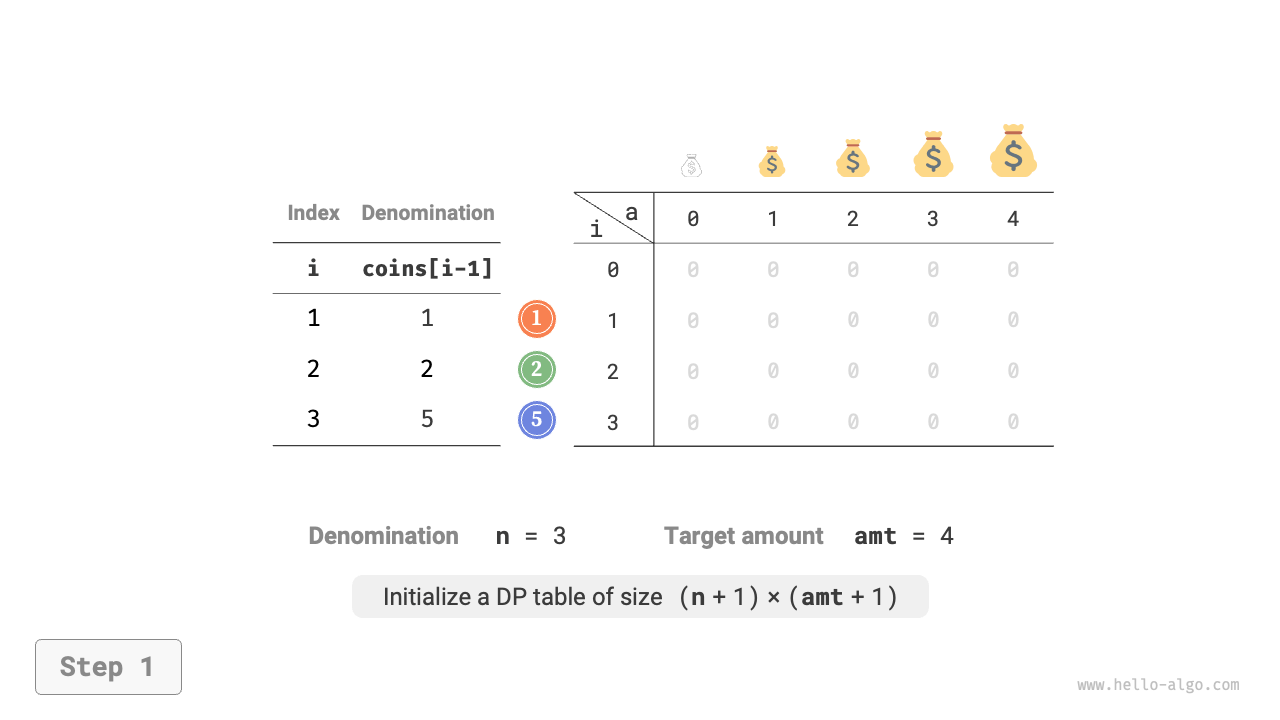
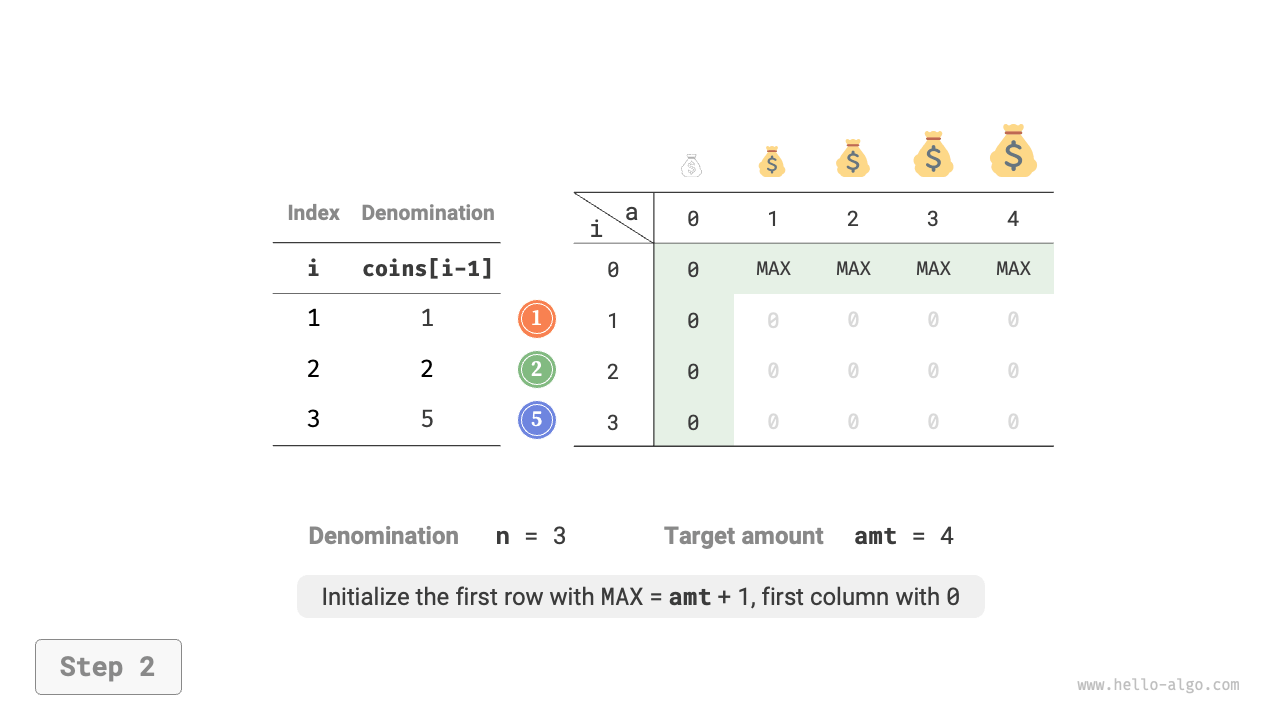
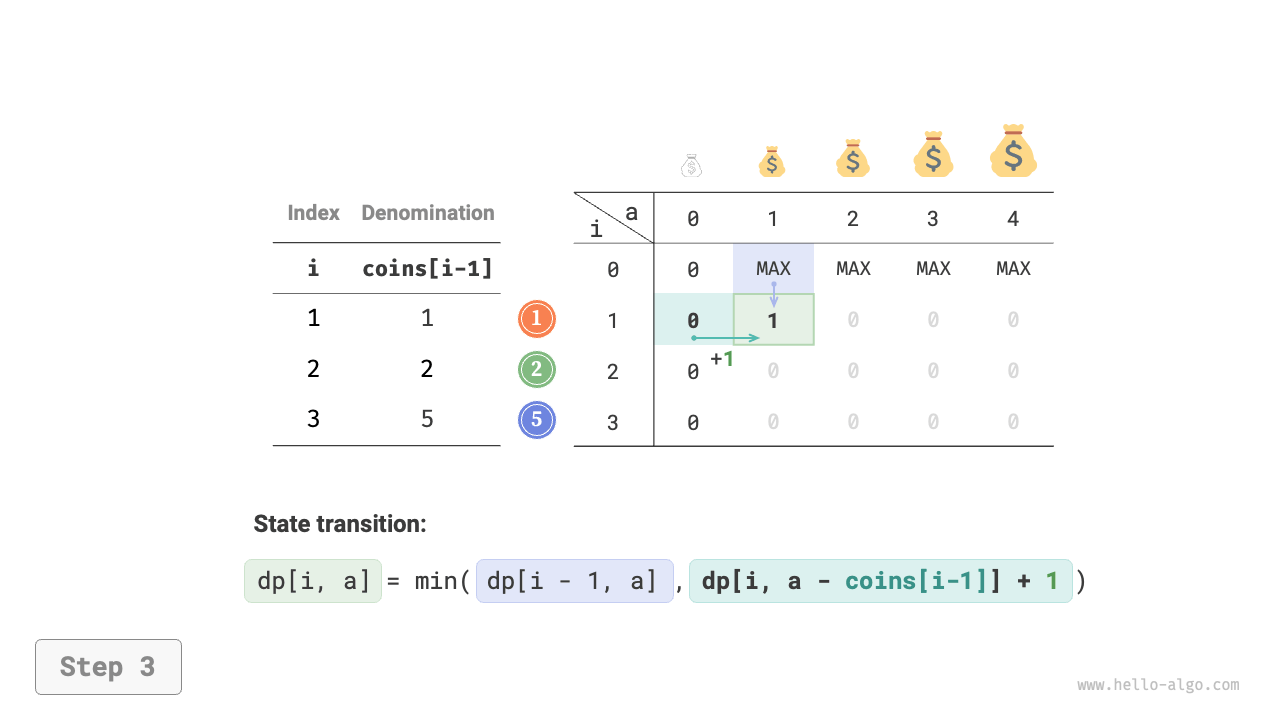
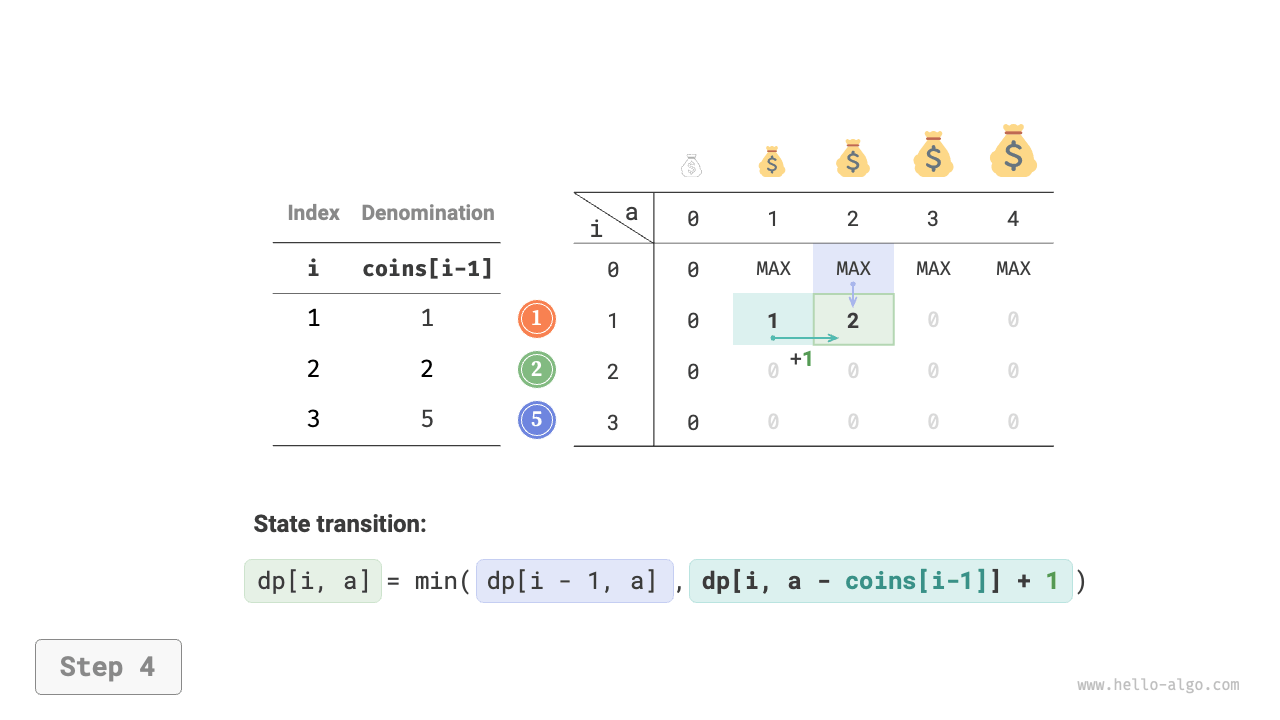
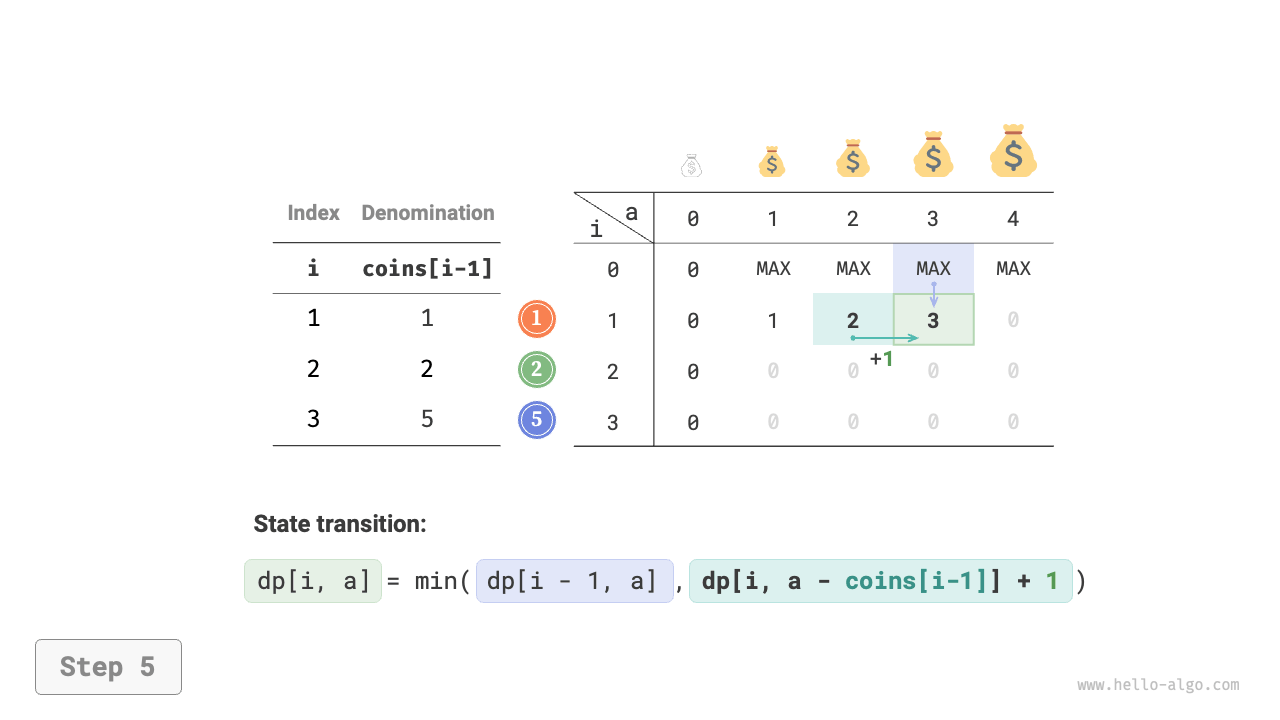
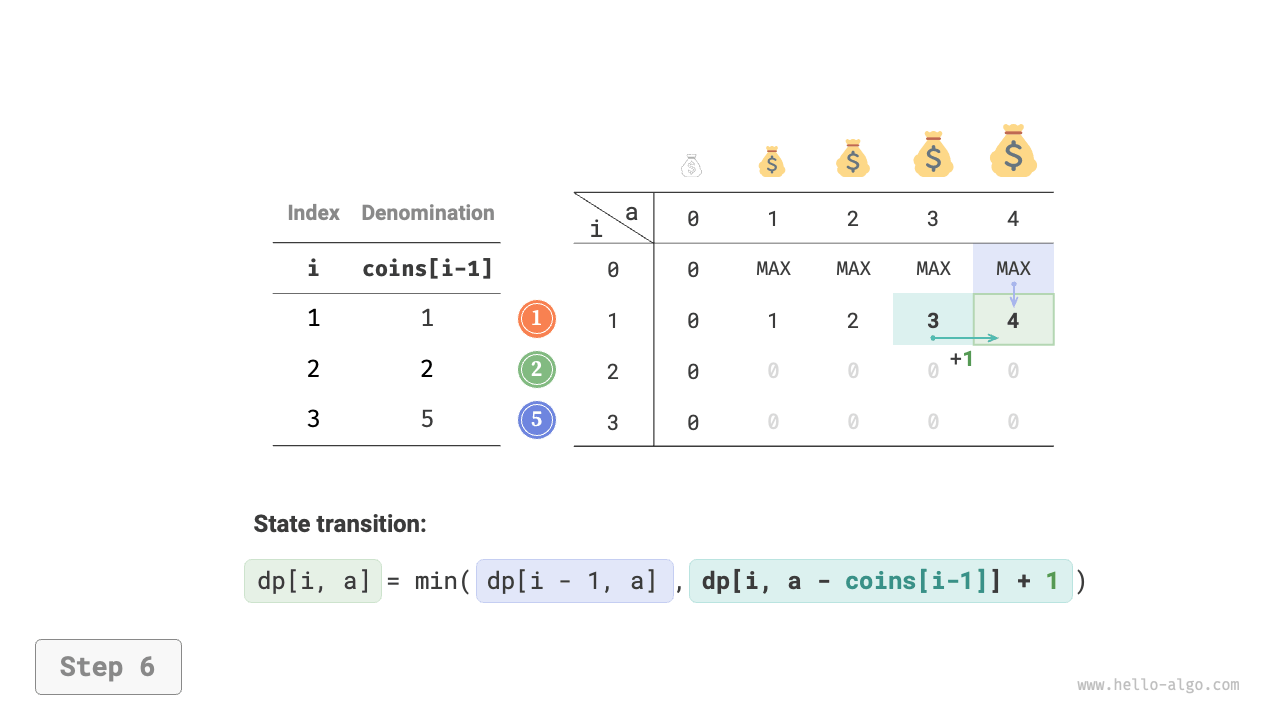
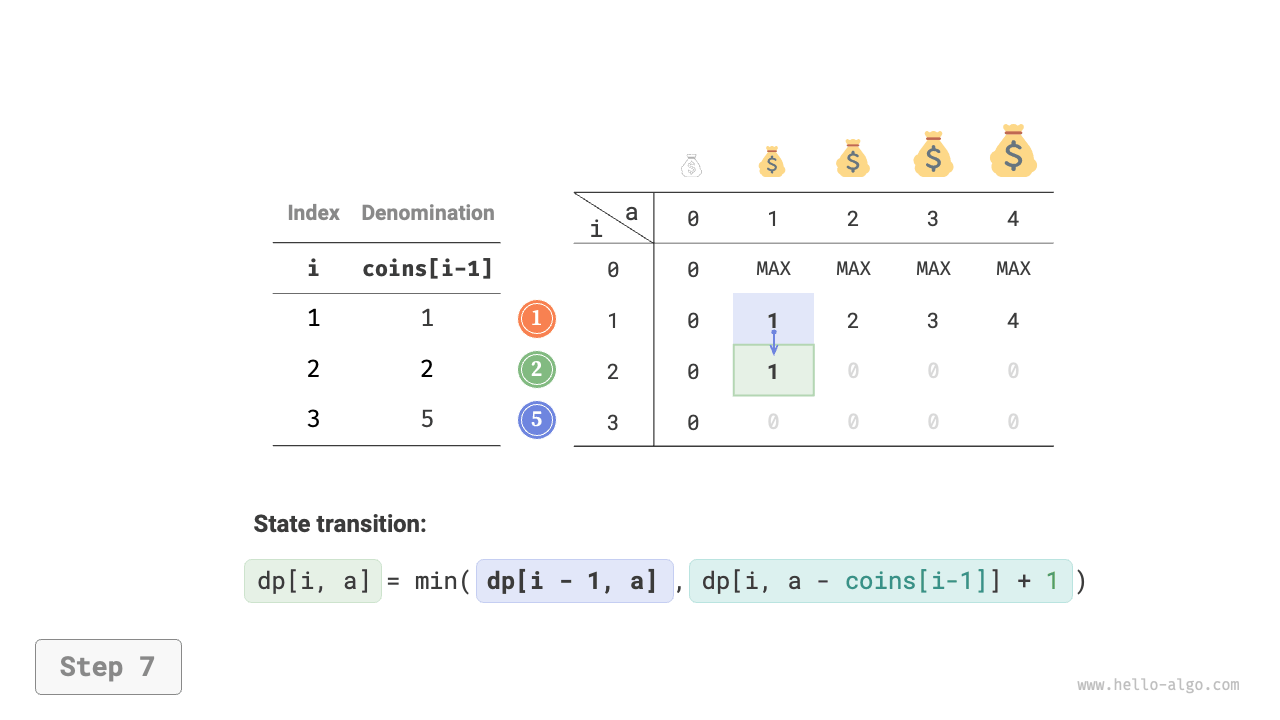
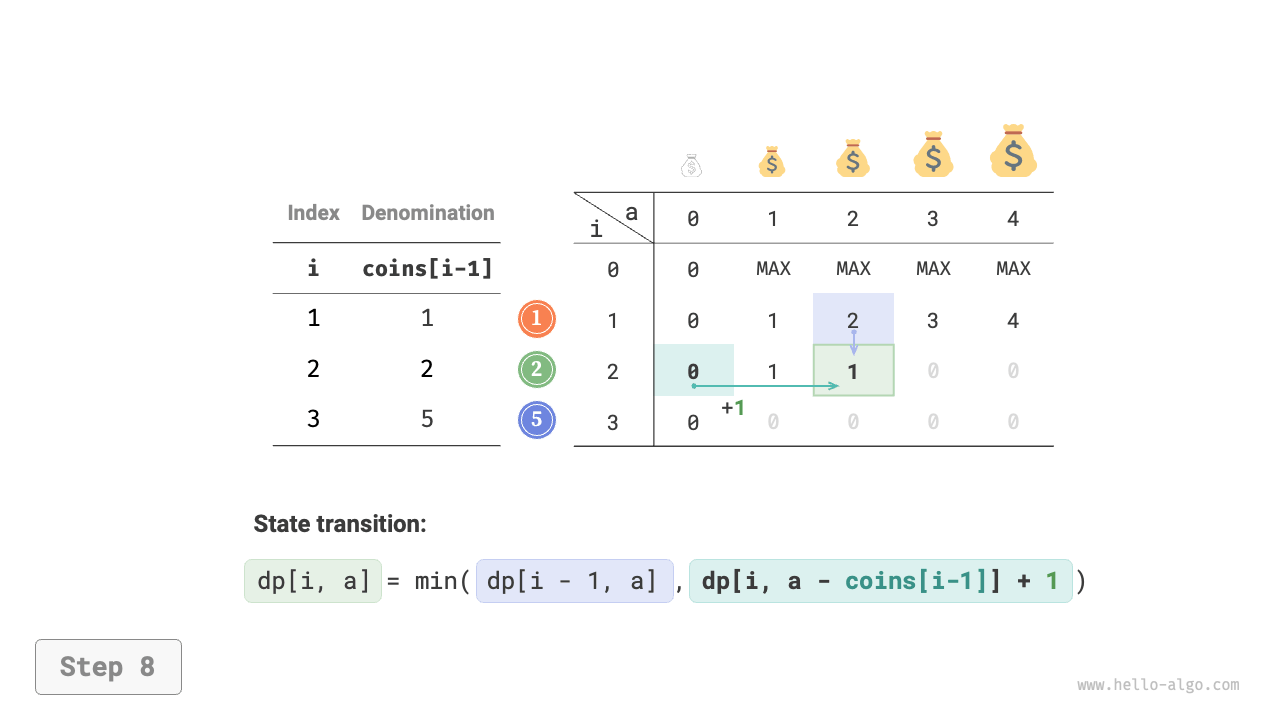
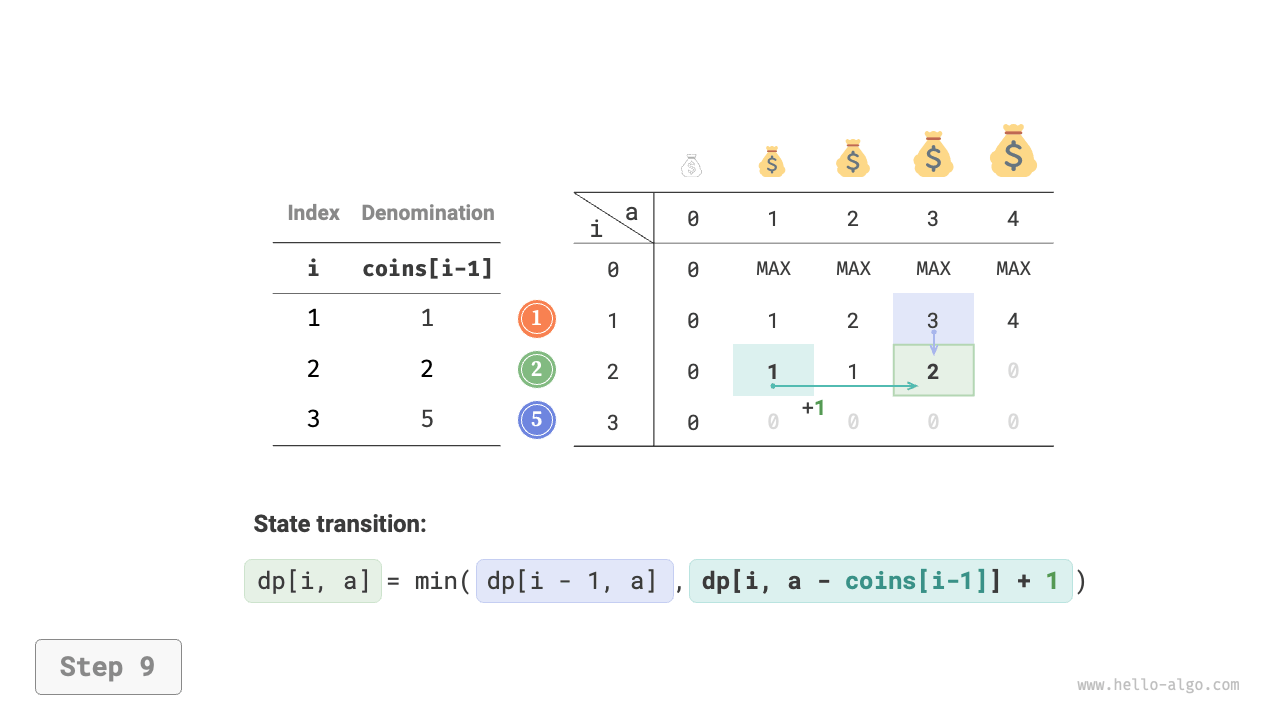
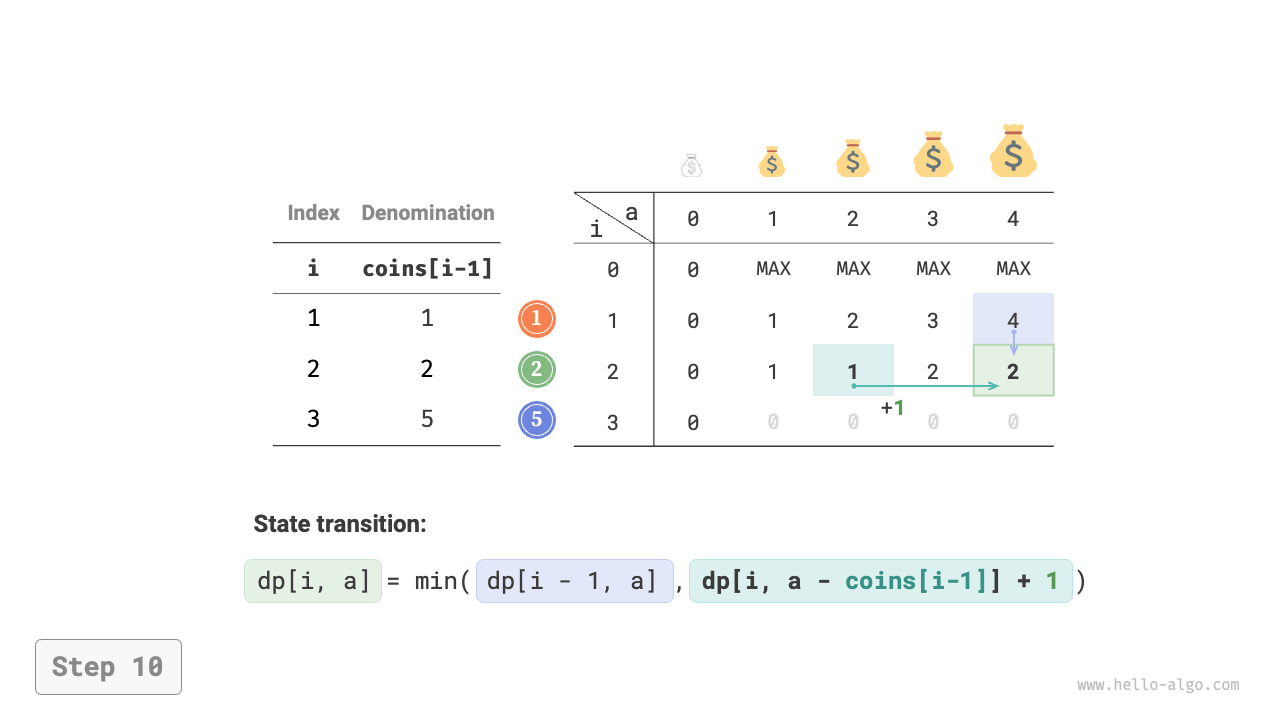
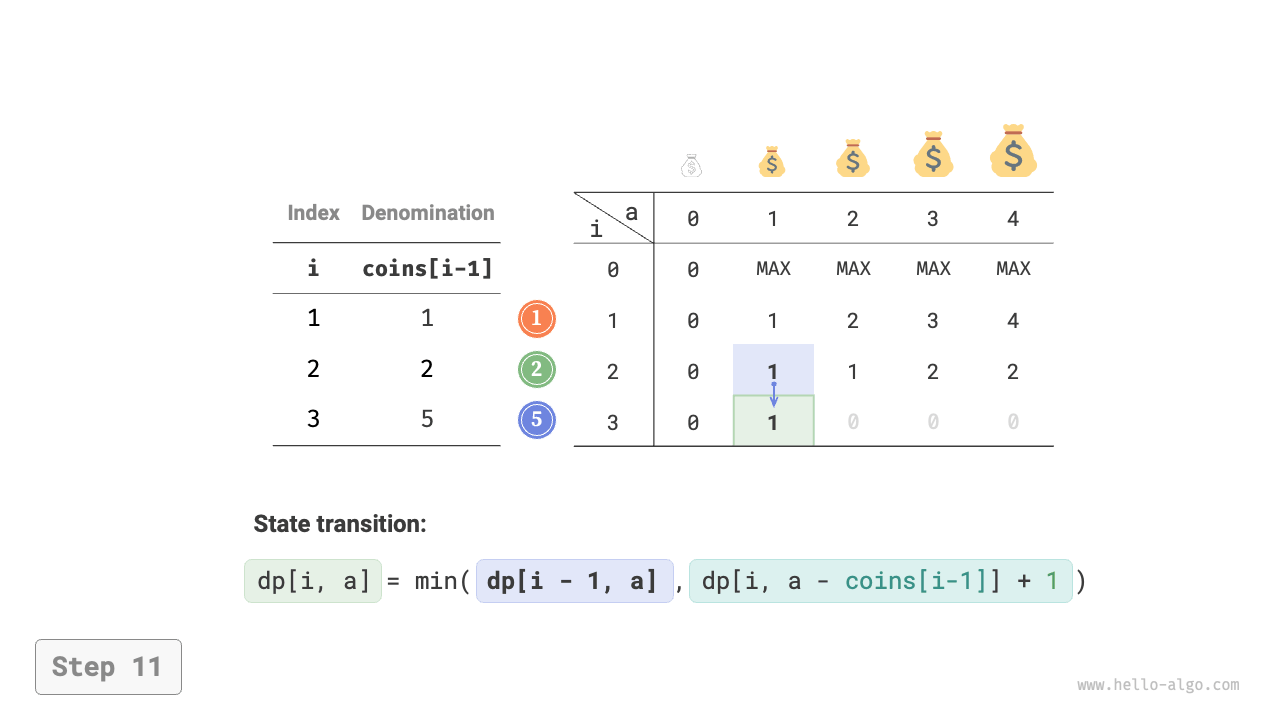
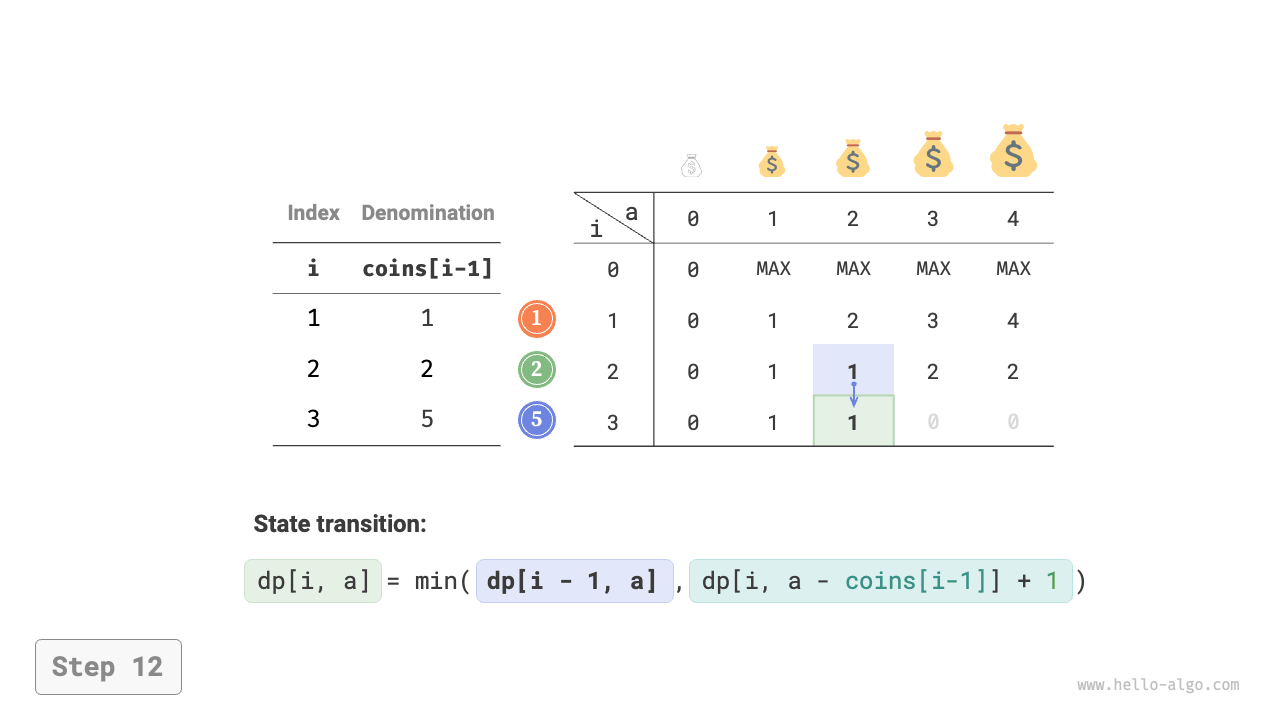
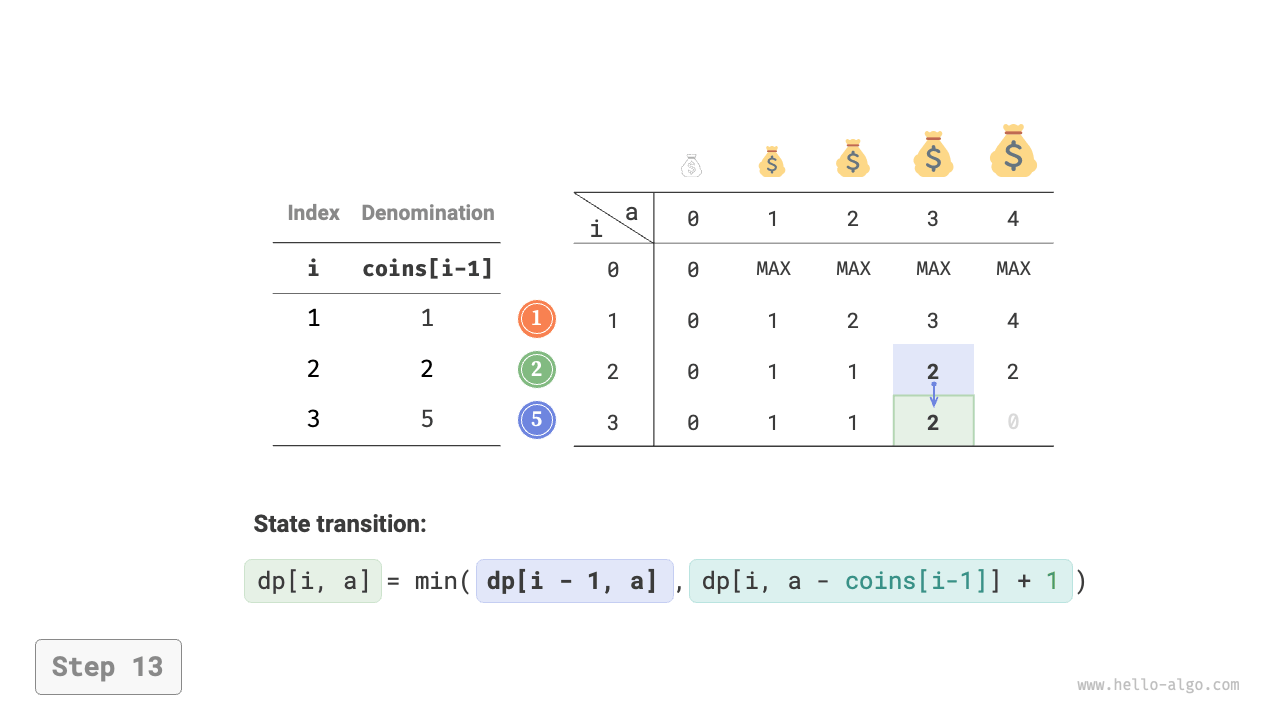
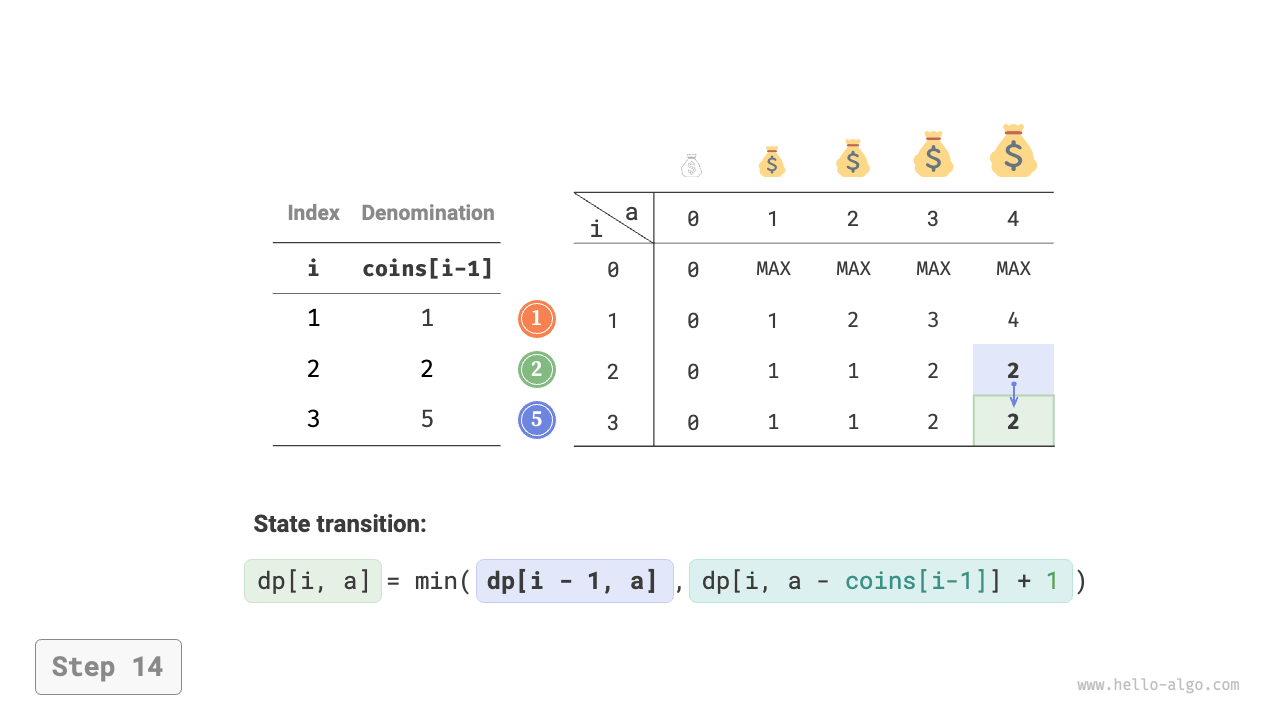
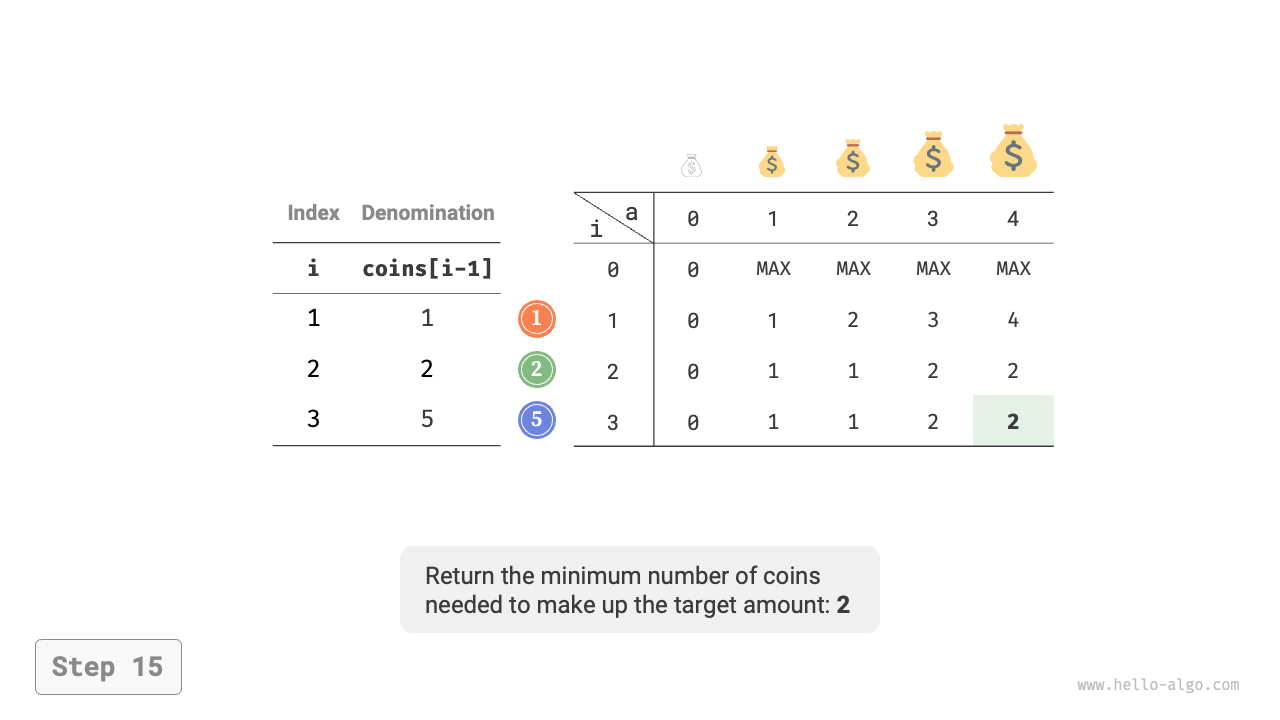
Figure 14-25 Dynamic programming process for coin change problem
3. Space Optimization¶
The space optimization for the coin change problem is handled in the same way as the unbounded knapsack problem:
def coin_change_dp_comp(coins: list[int], amt: int) -> int:
"""Coin change: Space-optimized dynamic programming"""
n = len(coins)
MAX = amt + 1
# Initialize dp table
dp = [MAX] * (amt + 1)
dp[0] = 0
# State transition
for i in range(1, n + 1):
# Traverse in forward order
for a in range(1, amt + 1):
if coins[i - 1] > a:
# If exceeds target amount, don't select coin i
dp[a] = dp[a]
else:
# The smaller value between not selecting and selecting coin i
dp[a] = min(dp[a], dp[a - coins[i - 1]] + 1)
return dp[amt] if dp[amt] != MAX else -1
/* Coin change: Space-optimized dynamic programming */
int coinChangeDPComp(vector<int> &coins, int amt) {
int n = coins.size();
int MAX = amt + 1;
// Initialize dp table
vector<int> dp(amt + 1, MAX);
dp[0] = 0;
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// The smaller value between not selecting and selecting coin i
dp[a] = min(dp[a], dp[a - coins[i - 1]] + 1);
}
}
}
return dp[amt] != MAX ? dp[amt] : -1;
}
/* Coin change: Space-optimized dynamic programming */
int coinChangeDPComp(int[] coins, int amt) {
int n = coins.length;
int MAX = amt + 1;
// Initialize dp table
int[] dp = new int[amt + 1];
Arrays.fill(dp, MAX);
dp[0] = 0;
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// The smaller value between not selecting and selecting coin i
dp[a] = Math.min(dp[a], dp[a - coins[i - 1]] + 1);
}
}
}
return dp[amt] != MAX ? dp[amt] : -1;
}
/* Coin change: Space-optimized dynamic programming */
int CoinChangeDPComp(int[] coins, int amt) {
int n = coins.Length;
int MAX = amt + 1;
// Initialize dp table
int[] dp = new int[amt + 1];
Array.Fill(dp, MAX);
dp[0] = 0;
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// The smaller value between not selecting and selecting coin i
dp[a] = Math.Min(dp[a], dp[a - coins[i - 1]] + 1);
}
}
}
return dp[amt] != MAX ? dp[amt] : -1;
}
/* Coin change: Dynamic programming */
func coinChangeDPComp(coins []int, amt int) int {
n := len(coins)
max := amt + 1
// Initialize dp table
dp := make([]int, amt+1)
for i := 1; i <= amt; i++ {
dp[i] = max
}
// State transition
for i := 1; i <= n; i++ {
// Traverse in forward order
for a := 1; a <= amt; a++ {
if coins[i-1] > a {
// If exceeds target amount, don't select coin i
dp[a] = dp[a]
} else {
// The smaller value between not selecting and selecting coin i
dp[a] = int(math.Min(float64(dp[a]), float64(dp[a-coins[i-1]]+1)))
}
}
}
if dp[amt] != max {
return dp[amt]
}
return -1
}
/* Coin change: Space-optimized dynamic programming */
func coinChangeDPComp(coins: [Int], amt: Int) -> Int {
let n = coins.count
let MAX = amt + 1
// Initialize dp table
var dp = Array(repeating: MAX, count: amt + 1)
dp[0] = 0
// State transition
for i in 1 ... n {
for a in 1 ... amt {
if coins[i - 1] > a {
// If exceeds target amount, don't select coin i
dp[a] = dp[a]
} else {
// The smaller value between not selecting and selecting coin i
dp[a] = min(dp[a], dp[a - coins[i - 1]] + 1)
}
}
}
return dp[amt] != MAX ? dp[amt] : -1
}
/* Coin change: Space-optimized dynamic programming */
function coinChangeDPComp(coins, amt) {
const n = coins.length;
const MAX = amt + 1;
// Initialize dp table
const dp = Array.from({ length: amt + 1 }, () => MAX);
dp[0] = 0;
// State transition
for (let i = 1; i <= n; i++) {
for (let a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// The smaller value between not selecting and selecting coin i
dp[a] = Math.min(dp[a], dp[a - coins[i - 1]] + 1);
}
}
}
return dp[amt] !== MAX ? dp[amt] : -1;
}
/* Coin change: Space-optimized dynamic programming */
function coinChangeDPComp(coins: Array<number>, amt: number): number {
const n = coins.length;
const MAX = amt + 1;
// Initialize dp table
const dp = Array.from({ length: amt + 1 }, () => MAX);
dp[0] = 0;
// State transition
for (let i = 1; i <= n; i++) {
for (let a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// The smaller value between not selecting and selecting coin i
dp[a] = Math.min(dp[a], dp[a - coins[i - 1]] + 1);
}
}
}
return dp[amt] !== MAX ? dp[amt] : -1;
}
/* Coin change: Space-optimized dynamic programming */
int coinChangeDPComp(List<int> coins, int amt) {
int n = coins.length;
int MAX = amt + 1;
// Initialize dp table
List<int> dp = List.filled(amt + 1, MAX);
dp[0] = 0;
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// The smaller value between not selecting and selecting coin i
dp[a] = min(dp[a], dp[a - coins[i - 1]] + 1);
}
}
}
return dp[amt] != MAX ? dp[amt] : -1;
}
/* Coin change: Space-optimized dynamic programming */
fn coin_change_dp_comp(coins: &[i32], amt: usize) -> i32 {
let n = coins.len();
let max = amt + 1;
// Initialize dp table
let mut dp = vec![0; amt + 1];
dp.fill(max);
dp[0] = 0;
// State transition
for i in 1..=n {
for a in 1..=amt {
if coins[i - 1] > a as i32 {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// The smaller value between not selecting and selecting coin i
dp[a] = std::cmp::min(dp[a], dp[a - coins[i - 1] as usize] + 1);
}
}
}
if dp[amt] != max {
return dp[amt] as i32;
} else {
-1
}
}
/* Coin change: Space-optimized dynamic programming */
int coinChangeDPComp(int coins[], int amt, int coinsSize) {
int n = coinsSize;
int MAX = amt + 1;
// Initialize dp table
int *dp = malloc((amt + 1) * sizeof(int));
for (int j = 1; j <= amt; j++) {
dp[j] = MAX;
}
dp[0] = 0;
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// The smaller value between not selecting and selecting coin i
dp[a] = myMin(dp[a], dp[a - coins[i - 1]] + 1);
}
}
}
int res = dp[amt] != MAX ? dp[amt] : -1;
// Free memory
free(dp);
return res;
}
/* Coin change: Space-optimized dynamic programming */
fun coinChangeDPComp(coins: IntArray, amt: Int): Int {
val n = coins.size
val MAX = amt + 1
// Initialize dp table
val dp = IntArray(amt + 1)
dp.fill(MAX)
dp[0] = 0
// State transition
for (i in 1..n) {
for (a in 1..amt) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a]
} else {
// The smaller value between not selecting and selecting coin i
dp[a] = min(dp[a], dp[a - coins[i - 1]] + 1)
}
}
}
return if (dp[amt] != MAX) dp[amt] else -1
}
### Coin change: space-optimized DP ###
def coin_change_dp_comp(coins, amt)
n = coins.length
_MAX = amt + 1
# Initialize dp table
dp = Array.new(amt + 1, _MAX)
dp[0] = 0
# State transition
for i in 1...(n + 1)
# Traverse in forward order
for a in 1...(amt + 1)
if coins[i - 1] > a
# If exceeds target amount, don't select coin i
dp[a] = dp[a]
else
# The smaller value between not selecting and selecting coin i
dp[a] = [dp[a], dp[a - coins[i - 1]] + 1].min
end
end
end
dp[amt] != _MAX ? dp[amt] : -1
end
14.5.3 Coin Change Problem II¶
Question
Given \(n\) types of coins, where the denomination of the \(i\)-th type of coin is \(coins[i - 1]\), and the target amount is \(amt\). Each type of coin can be selected multiple times. What is the number of coin combinations that can make up the target amount? An example is shown in Figure 14-26.
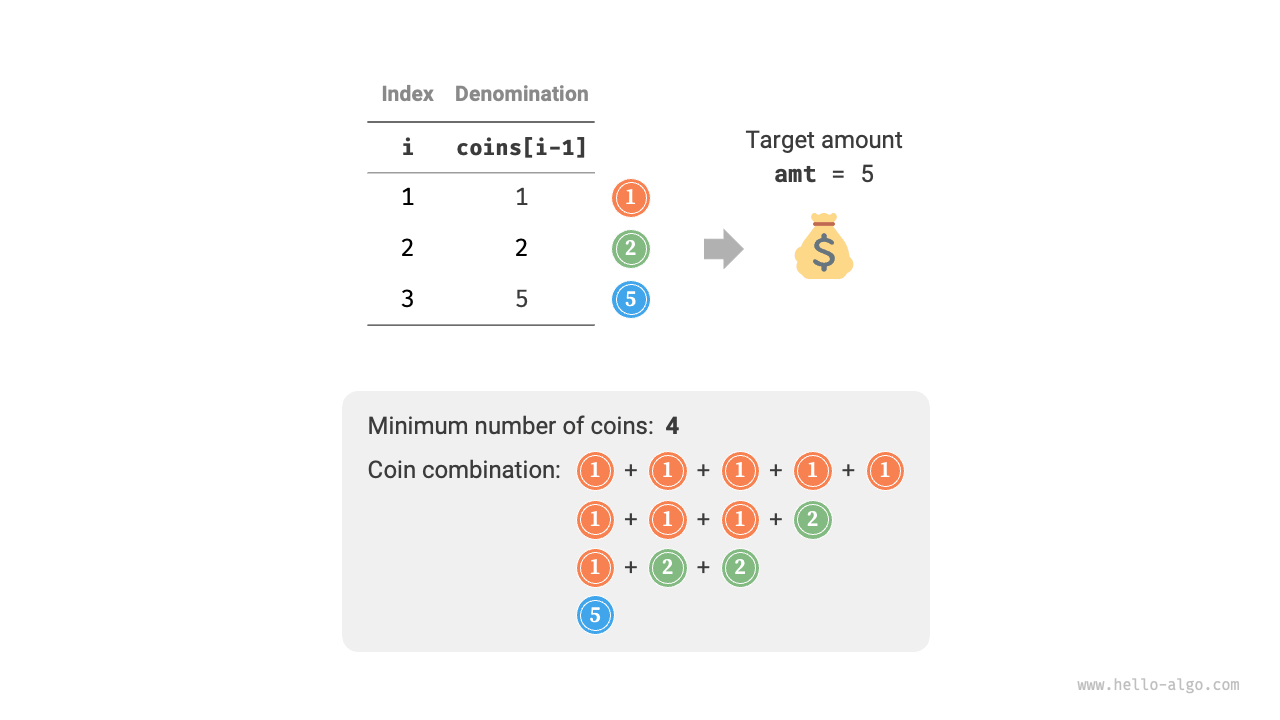
Figure 14-26 Example data for coin change problem II
1. Dynamic Programming Approach¶
Compared to the previous problem, this problem's goal is to find the number of combinations, so the subproblem becomes: the number of combinations among the first \(i\) types of coins that can make up amount \(a\). The \(dp\) table remains a two-dimensional matrix of size \((n+1) \times (amt + 1)\).
The number of combinations for the current state equals the sum of the combinations from not selecting the current coin and selecting the current coin. The state transition equation is:
When the target amount is \(0\), no coins need to be selected to make up the target amount, so all \(dp[i, 0]\) in the first column should be initialized to \(1\). When there are no coins, it is impossible to make up any amount \(>0\), so all \(dp[0, a]\) in the first row equal \(0\).
2. Code Implementation¶
def coin_change_ii_dp(coins: list[int], amt: int) -> int:
"""Coin change II: Dynamic programming"""
n = len(coins)
# Initialize dp table
dp = [[0] * (amt + 1) for _ in range(n + 1)]
# Initialize first column
for i in range(n + 1):
dp[i][0] = 1
# State transition
for i in range(1, n + 1):
for a in range(1, amt + 1):
if coins[i - 1] > a:
# If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a]
else:
# Sum of the two options: not selecting and selecting coin i
dp[i][a] = dp[i - 1][a] + dp[i][a - coins[i - 1]]
return dp[n][amt]
/* Coin change II: Dynamic programming */
int coinChangeIIDP(vector<int> &coins, int amt) {
int n = coins.size();
// Initialize dp table
vector<vector<int>> dp(n + 1, vector<int>(amt + 1, 0));
// Initialize first column
for (int i = 0; i <= n; i++) {
dp[i][0] = 1;
}
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[i][a] = dp[i - 1][a] + dp[i][a - coins[i - 1]];
}
}
}
return dp[n][amt];
}
/* Coin change II: Dynamic programming */
int coinChangeIIDP(int[] coins, int amt) {
int n = coins.length;
// Initialize dp table
int[][] dp = new int[n + 1][amt + 1];
// Initialize first column
for (int i = 0; i <= n; i++) {
dp[i][0] = 1;
}
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[i][a] = dp[i - 1][a] + dp[i][a - coins[i - 1]];
}
}
}
return dp[n][amt];
}
/* Coin change II: Dynamic programming */
int CoinChangeIIDP(int[] coins, int amt) {
int n = coins.Length;
// Initialize dp table
int[,] dp = new int[n + 1, amt + 1];
// Initialize first column
for (int i = 0; i <= n; i++) {
dp[i, 0] = 1;
}
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i, a] = dp[i - 1, a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[i, a] = dp[i - 1, a] + dp[i, a - coins[i - 1]];
}
}
}
return dp[n, amt];
}
/* Coin change II: Dynamic programming */
func coinChangeIIDP(coins []int, amt int) int {
n := len(coins)
// Initialize dp table
dp := make([][]int, n+1)
for i := 0; i <= n; i++ {
dp[i] = make([]int, amt+1)
}
// Initialize first column
for i := 0; i <= n; i++ {
dp[i][0] = 1
}
// State transition: rest of the rows and columns
for i := 1; i <= n; i++ {
for a := 1; a <= amt; a++ {
if coins[i-1] > a {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i-1][a]
} else {
// Sum of the two options: not selecting and selecting coin i
dp[i][a] = dp[i-1][a] + dp[i][a-coins[i-1]]
}
}
}
return dp[n][amt]
}
/* Coin change II: Dynamic programming */
func coinChangeIIDP(coins: [Int], amt: Int) -> Int {
let n = coins.count
// Initialize dp table
var dp = Array(repeating: Array(repeating: 0, count: amt + 1), count: n + 1)
// Initialize first column
for i in 0 ... n {
dp[i][0] = 1
}
// State transition
for i in 1 ... n {
for a in 1 ... amt {
if coins[i - 1] > a {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a]
} else {
// Sum of the two options: not selecting and selecting coin i
dp[i][a] = dp[i - 1][a] + dp[i][a - coins[i - 1]]
}
}
}
return dp[n][amt]
}
/* Coin change II: Dynamic programming */
function coinChangeIIDP(coins, amt) {
const n = coins.length;
// Initialize dp table
const dp = Array.from({ length: n + 1 }, () =>
Array.from({ length: amt + 1 }, () => 0)
);
// Initialize first column
for (let i = 0; i <= n; i++) {
dp[i][0] = 1;
}
// State transition
for (let i = 1; i <= n; i++) {
for (let a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[i][a] = dp[i - 1][a] + dp[i][a - coins[i - 1]];
}
}
}
return dp[n][amt];
}
/* Coin change II: Dynamic programming */
function coinChangeIIDP(coins: Array<number>, amt: number): number {
const n = coins.length;
// Initialize dp table
const dp = Array.from({ length: n + 1 }, () =>
Array.from({ length: amt + 1 }, () => 0)
);
// Initialize first column
for (let i = 0; i <= n; i++) {
dp[i][0] = 1;
}
// State transition
for (let i = 1; i <= n; i++) {
for (let a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[i][a] = dp[i - 1][a] + dp[i][a - coins[i - 1]];
}
}
}
return dp[n][amt];
}
/* Coin change II: Dynamic programming */
int coinChangeIIDP(List<int> coins, int amt) {
int n = coins.length;
// Initialize dp table
List<List<int>> dp = List.generate(n + 1, (index) => List.filled(amt + 1, 0));
// Initialize first column
for (int i = 0; i <= n; i++) {
dp[i][0] = 1;
}
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[i][a] = dp[i - 1][a] + dp[i][a - coins[i - 1]];
}
}
}
return dp[n][amt];
}
/* Coin change II: Dynamic programming */
fn coin_change_ii_dp(coins: &[i32], amt: usize) -> i32 {
let n = coins.len();
// Initialize dp table
let mut dp = vec![vec![0; amt + 1]; n + 1];
// Initialize first column
for i in 0..=n {
dp[i][0] = 1;
}
// State transition
for i in 1..=n {
for a in 1..=amt {
if coins[i - 1] > a as i32 {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[i][a] = dp[i - 1][a] + dp[i][a - coins[i - 1] as usize];
}
}
}
dp[n][amt]
}
/* Coin change II: Dynamic programming */
int coinChangeIIDP(int coins[], int amt, int coinsSize) {
int n = coinsSize;
// Initialize dp table
int **dp = malloc((n + 1) * sizeof(int *));
for (int i = 0; i <= n; i++) {
dp[i] = calloc(amt + 1, sizeof(int));
}
// Initialize first column
for (int i = 0; i <= n; i++) {
dp[i][0] = 1;
}
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[i][a] = dp[i - 1][a] + dp[i][a - coins[i - 1]];
}
}
}
int res = dp[n][amt];
// Free memory
for (int i = 0; i <= n; i++) {
free(dp[i]);
}
free(dp);
return res;
}
/* Coin change II: Dynamic programming */
fun coinChangeIIDP(coins: IntArray, amt: Int): Int {
val n = coins.size
// Initialize dp table
val dp = Array(n + 1) { IntArray(amt + 1) }
// Initialize first column
for (i in 0..n) {
dp[i][0] = 1
}
// State transition
for (i in 1..n) {
for (a in 1..amt) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a]
} else {
// Sum of the two options: not selecting and selecting coin i
dp[i][a] = dp[i - 1][a] + dp[i][a - coins[i - 1]]
}
}
}
return dp[n][amt]
}
### Coin change II: dynamic programming ###
def coin_change_ii_dp(coins, amt)
n = coins.length
# Initialize dp table
dp = Array.new(n + 1) { Array.new(amt + 1, 0) }
# Initialize first column
(0...(n + 1)).each { |i| dp[i][0] = 1 }
# State transition
for i in 1...(n + 1)
for a in 1...(amt + 1)
if coins[i - 1] > a
# If exceeds target amount, don't select coin i
dp[i][a] = dp[i - 1][a]
else
# Sum of the two options: not selecting and selecting coin i
dp[i][a] = dp[i - 1][a] + dp[i][a - coins[i - 1]]
end
end
end
dp[n][amt]
end
3. Space Optimization¶
The space optimization is handled in the same way, just delete the coin dimension:
def coin_change_ii_dp_comp(coins: list[int], amt: int) -> int:
"""Coin change II: Space-optimized dynamic programming"""
n = len(coins)
# Initialize dp table
dp = [0] * (amt + 1)
dp[0] = 1
# State transition
for i in range(1, n + 1):
# Traverse in forward order
for a in range(1, amt + 1):
if coins[i - 1] > a:
# If exceeds target amount, don't select coin i
dp[a] = dp[a]
else:
# Sum of the two options: not selecting and selecting coin i
dp[a] = dp[a] + dp[a - coins[i - 1]]
return dp[amt]
/* Coin change II: Space-optimized dynamic programming */
int coinChangeIIDPComp(vector<int> &coins, int amt) {
int n = coins.size();
// Initialize dp table
vector<int> dp(amt + 1, 0);
dp[0] = 1;
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[a] = dp[a] + dp[a - coins[i - 1]];
}
}
}
return dp[amt];
}
/* Coin change II: Space-optimized dynamic programming */
int coinChangeIIDPComp(int[] coins, int amt) {
int n = coins.length;
// Initialize dp table
int[] dp = new int[amt + 1];
dp[0] = 1;
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[a] = dp[a] + dp[a - coins[i - 1]];
}
}
}
return dp[amt];
}
/* Coin change II: Space-optimized dynamic programming */
int CoinChangeIIDPComp(int[] coins, int amt) {
int n = coins.Length;
// Initialize dp table
int[] dp = new int[amt + 1];
dp[0] = 1;
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[a] = dp[a] + dp[a - coins[i - 1]];
}
}
}
return dp[amt];
}
/* Coin change II: Space-optimized dynamic programming */
func coinChangeIIDPComp(coins []int, amt int) int {
n := len(coins)
// Initialize dp table
dp := make([]int, amt+1)
dp[0] = 1
// State transition
for i := 1; i <= n; i++ {
// Traverse in forward order
for a := 1; a <= amt; a++ {
if coins[i-1] > a {
// If exceeds target amount, don't select coin i
dp[a] = dp[a]
} else {
// Sum of the two options: not selecting and selecting coin i
dp[a] = dp[a] + dp[a-coins[i-1]]
}
}
}
return dp[amt]
}
/* Coin change II: Space-optimized dynamic programming */
func coinChangeIIDPComp(coins: [Int], amt: Int) -> Int {
let n = coins.count
// Initialize dp table
var dp = Array(repeating: 0, count: amt + 1)
dp[0] = 1
// State transition
for i in 1 ... n {
for a in 1 ... amt {
if coins[i - 1] > a {
// If exceeds target amount, don't select coin i
dp[a] = dp[a]
} else {
// Sum of the two options: not selecting and selecting coin i
dp[a] = dp[a] + dp[a - coins[i - 1]]
}
}
}
return dp[amt]
}
/* Coin change II: Space-optimized dynamic programming */
function coinChangeIIDPComp(coins, amt) {
const n = coins.length;
// Initialize dp table
const dp = Array.from({ length: amt + 1 }, () => 0);
dp[0] = 1;
// State transition
for (let i = 1; i <= n; i++) {
for (let a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[a] = dp[a] + dp[a - coins[i - 1]];
}
}
}
return dp[amt];
}
/* Coin change II: Space-optimized dynamic programming */
function coinChangeIIDPComp(coins: Array<number>, amt: number): number {
const n = coins.length;
// Initialize dp table
const dp = Array.from({ length: amt + 1 }, () => 0);
dp[0] = 1;
// State transition
for (let i = 1; i <= n; i++) {
for (let a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[a] = dp[a] + dp[a - coins[i - 1]];
}
}
}
return dp[amt];
}
/* Coin change II: Space-optimized dynamic programming */
int coinChangeIIDPComp(List<int> coins, int amt) {
int n = coins.length;
// Initialize dp table
List<int> dp = List.filled(amt + 1, 0);
dp[0] = 1;
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[a] = dp[a] + dp[a - coins[i - 1]];
}
}
}
return dp[amt];
}
/* Coin change II: Space-optimized dynamic programming */
fn coin_change_ii_dp_comp(coins: &[i32], amt: usize) -> i32 {
let n = coins.len();
// Initialize dp table
let mut dp = vec![0; amt + 1];
dp[0] = 1;
// State transition
for i in 1..=n {
for a in 1..=amt {
if coins[i - 1] > a as i32 {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[a] = dp[a] + dp[a - coins[i - 1] as usize];
}
}
}
dp[amt]
}
/* Coin change II: Space-optimized dynamic programming */
int coinChangeIIDPComp(int coins[], int amt, int coinsSize) {
int n = coinsSize;
// Initialize dp table
int *dp = calloc(amt + 1, sizeof(int));
dp[0] = 1;
// State transition
for (int i = 1; i <= n; i++) {
for (int a = 1; a <= amt; a++) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a];
} else {
// Sum of the two options: not selecting and selecting coin i
dp[a] = dp[a] + dp[a - coins[i - 1]];
}
}
}
int res = dp[amt];
// Free memory
free(dp);
return res;
}
/* Coin change II: Space-optimized dynamic programming */
fun coinChangeIIDPComp(coins: IntArray, amt: Int): Int {
val n = coins.size
// Initialize dp table
val dp = IntArray(amt + 1)
dp[0] = 1
// State transition
for (i in 1..n) {
for (a in 1..amt) {
if (coins[i - 1] > a) {
// If exceeds target amount, don't select coin i
dp[a] = dp[a]
} else {
// Sum of the two options: not selecting and selecting coin i
dp[a] = dp[a] + dp[a - coins[i - 1]]
}
}
}
return dp[amt]
}
### Coin change II: space-optimized DP ###
def coin_change_ii_dp_comp(coins, amt)
n = coins.length
# Initialize dp table
dp = Array.new(amt + 1, 0)
dp[0] = 1
# State transition
for i in 1...(n + 1)
# Traverse in forward order
for a in 1...(amt + 1)
if coins[i - 1] > a
# If exceeds target amount, don't select coin i
dp[a] = dp[a]
else
# Sum of the two options: not selecting and selecting coin i
dp[a] = dp[a] + dp[a - coins[i - 1]]
end
end
end
dp[amt]
end