12.1 Divide and Conquer Algorithms¶
Divide and conquer is a very important and common algorithmic strategy. Divide and conquer is typically implemented based on recursion, consisting of two steps: "divide" and "conquer".
- Divide (partition phase): Recursively divide the original problem into two or more subproblems until the smallest subproblem is reached.
- Conquer (merge phase): Starting from the smallest subproblems with known solutions, merge the solutions of subproblems from bottom to top to construct the solution to the original problem.
As shown in Figure 12-1, "merge sort" is one of the typical applications of the divide and conquer strategy.
- Divide: Recursively divide the original array (original problem) into two subarrays (subproblems) until the subarray has only one element (smallest subproblem).
- Conquer: Merge the sorted subarrays (solutions to subproblems) from bottom to top to obtain a sorted original array (solution to the original problem).
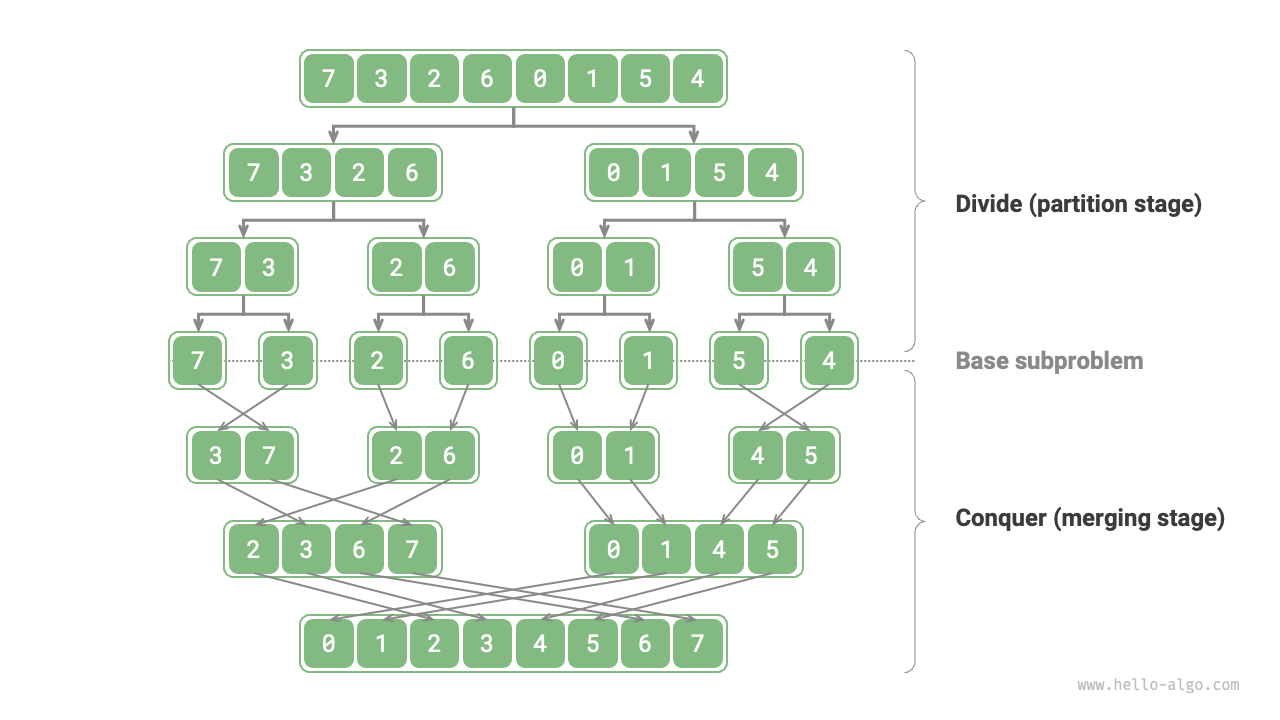
Figure 12-1 Divide and conquer strategy of merge sort
12.1.1 How to Determine Divide and Conquer Problems¶
Whether a problem is suitable for solving with divide and conquer can usually be determined based on the following criteria.
- The problem can be decomposed: The original problem can be divided into smaller, similar subproblems, and can be recursively divided in the same way.
- Subproblems are independent: There is no overlap between subproblems, they are independent of each other and can be solved independently.
- Solutions of subproblems can be merged: The solution to the original problem is obtained by merging the solutions of subproblems.
Clearly, merge sort satisfies these three criteria.
- The problem can be decomposed: Recursively divide the array (original problem) into two subarrays (subproblems).
- Subproblems are independent: Each subarray can be sorted independently (subproblems can be solved independently).
- Solutions of subproblems can be merged: Two sorted subarrays (solutions of subproblems) can be merged into one sorted array (solution of the original problem).
12.1.2 Improving Efficiency Through Divide and Conquer¶
Divide and conquer can not only effectively solve algorithmic problems, but can often also improve algorithmic efficiency. In sorting algorithms, quick sort, merge sort, and heap sort are faster than selection, bubble, and insertion sort because they apply the divide and conquer strategy.
This raises the question: Why can divide and conquer improve algorithm efficiency, and what is the underlying logic? In other words, why is dividing a large problem into multiple subproblems, solving the subproblems, and merging their solutions more efficient than directly solving the original problem? This question can be discussed from two aspects: operation count and parallel computation.
1. Operation Count Optimization¶
Taking "bubble sort" as an example, processing an array of length \(n\) requires \(O(n^2)\) time. Suppose we divide the array at the midpoint into two subarrays, as shown in Figure 12-2. The division requires \(O(n)\) time, sorting each subarray requires \(O((n / 2)^2)\) time, and merging the two subarrays requires \(O(n)\) time, resulting in an overall time complexity of:
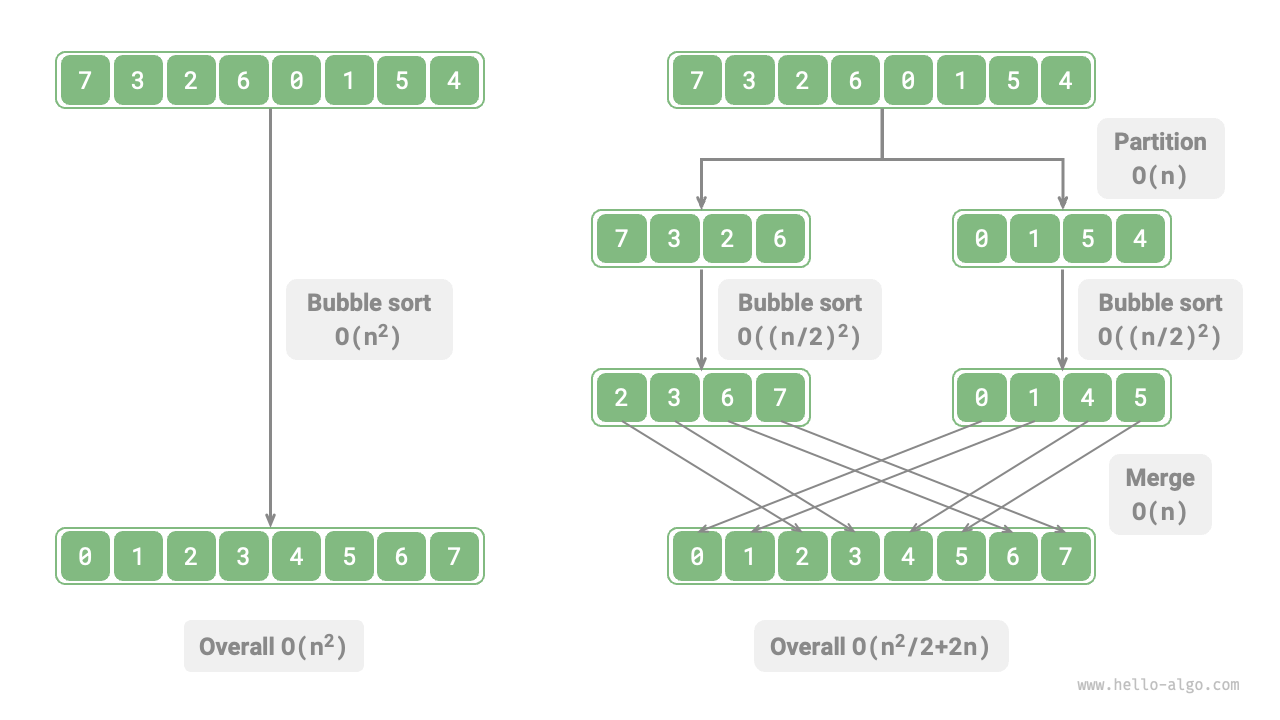
Figure 12-2 Bubble sort before and after array division
Next, we compute the following inequality, where the left and right sides represent the total number of operations before and after division, respectively:
This means that when \(n > 4\), the number of operations after division is smaller, and sorting efficiency should be higher. Note that the time complexity after division is still quadratic \(O(n^2)\), but the constant term in the complexity has become smaller.
Going further, what if we continuously divide the subarrays from their midpoints into two subarrays until the subarrays have only one element? This approach is actually "merge sort", with a time complexity of \(O(n \log n)\).
Thinking further, what if we set multiple division points and evenly divide the original array into \(k\) subarrays? This situation is very similar to "bucket sort", which is well-suited for sorting massive amounts of data, with a theoretical time complexity of \(O(n + k)\).
2. Parallel Computation Optimization¶
We know that the subproblems generated by divide and conquer are independent of each other, so they can typically be solved in parallel. This means divide and conquer can not only reduce the time complexity of algorithms, but is also amenable to parallel optimization by the operating system.
Parallel optimization is particularly effective in multi-core or multi-processor environments, as the system can simultaneously handle multiple subproblems, making fuller use of computing resources and significantly reducing overall runtime.
For example, in the "bucket sort" shown in Figure 12-3, we evenly distribute massive data into various buckets, and the sorting tasks for all buckets can be distributed to various computing units. After completion, the results are merged.
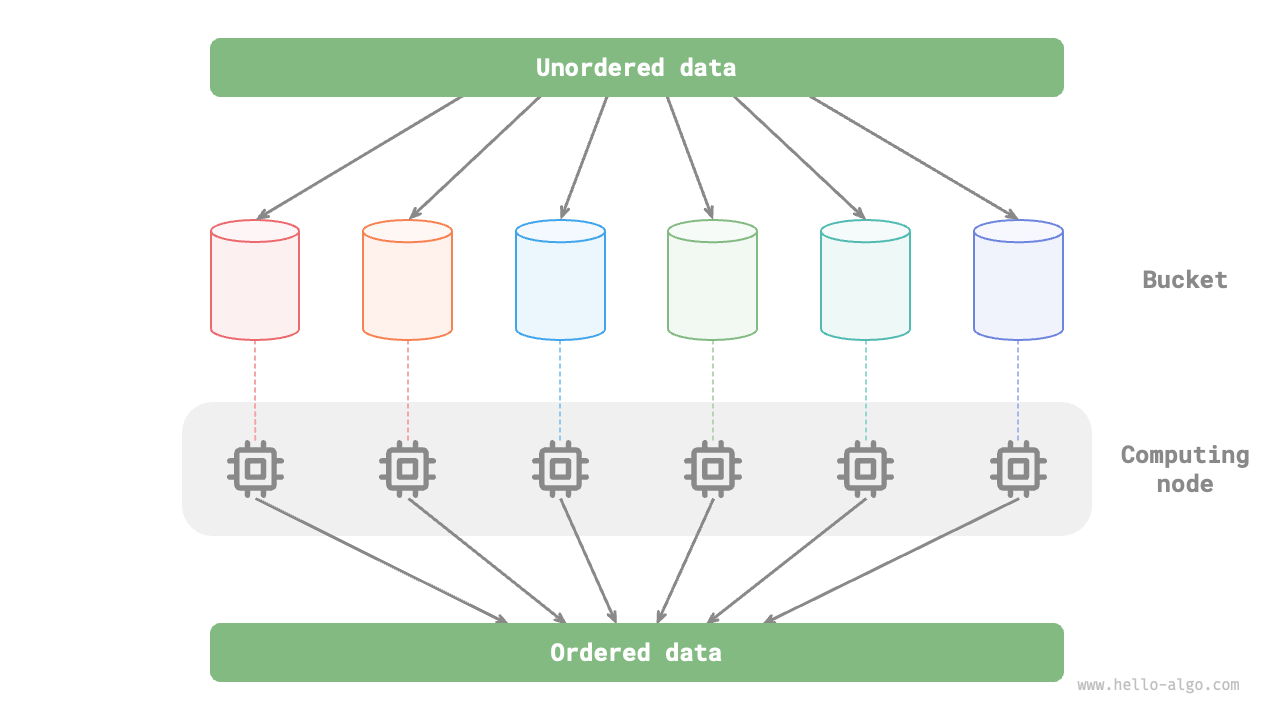
Figure 12-3 Parallel computation in bucket sort
12.1.3 Common Applications of Divide and Conquer¶
On the one hand, divide and conquer can be used to solve many classic algorithmic problems.
- Finding the closest pair of points: This algorithm first divides the point set into two parts, then finds the closest pair of points in each part separately, and finally finds the closest pair of points that spans both parts.
- Large integer multiplication: For example, the Karatsuba algorithm, which decomposes large integer multiplication into several smaller integer multiplications and additions.
- Matrix multiplication: For example, the Strassen algorithm, which decomposes large matrix multiplication into multiple small matrix multiplications and additions.
- Hanota problem: The hanota problem can be solved through recursion, which is a typical application of the divide and conquer strategy.
- Solving inversion pairs: In a sequence, if a preceding number is greater than a following number, these two numbers form an inversion pair. Solving the inversion pair problem can utilize the divide and conquer approach with the help of merge sort.
On the other hand, divide and conquer is widely applied in the design of algorithms and data structures.
- Binary search: Binary search divides a sorted array into two parts from the midpoint index, then decides which half to eliminate based on the comparison result between the target value and the middle element value, and performs the same binary-search step on the remaining interval.
- Merge sort: Already introduced at the beginning of this section, no further elaboration needed.
- Quick sort: Quick sort selects a pivot value, then divides the array into two subarrays, one with elements smaller than the pivot and the other with elements larger than the pivot, then performs the same division operation on these two parts until the subarrays have only one element.
- Bucket sort: The basic idea of bucket sort is to scatter data into multiple buckets, then sort the elements within each bucket, and finally extract the elements from each bucket in sequence to obtain a sorted array.
- Trees: For example, binary search trees, AVL trees, red-black trees, B-trees, B+ trees, etc. Their search, insertion, and deletion operations can all be viewed as applications of the divide and conquer strategy.
- Heaps: A heap is a special complete binary tree, and its various operations, such as insertion, deletion, and heapify, actually imply the divide and conquer idea.
- Hash tables: Although hash tables do not directly apply divide and conquer, some methods for resolving hash collisions indirectly apply the divide and conquer strategy. For example, long linked lists in chaining may be converted to red-black trees to improve lookup efficiency.
It can be seen that divide and conquer is a "quietly pervasive" algorithmic idea, embedded in various algorithms and data structures.