14.4 0-1 Knapsack Problem¶
The knapsack problem is an excellent introductory problem for dynamic programming and is one of the most common problem forms in dynamic programming. It has many variants, such as the 0-1 knapsack problem, the unbounded knapsack problem, and the multiple knapsack problem.
In this section, we will first solve the most common 0-1 knapsack problem.
Question
Given \(n\) items and a knapsack with capacity \(cap\), where the weight and value of the \(i\)-th item are \(wgt[i-1]\) and \(val[i-1]\), respectively. Each item can be selected at most once. What is the maximum value that can fit in the knapsack under the capacity limit?
Observe Figure 14-17. Since item number \(i\) starts counting from \(1\) and array indices start from \(0\), item \(i\) corresponds to weight \(wgt[i-1]\) and value \(val[i-1]\).

Figure 14-17 Example data for 0-1 knapsack
We can view the 0-1 knapsack problem as a process consisting of \(n\) rounds of decisions, where for each item there are two decisions: not putting it in and putting it in, thus the problem satisfies the decision tree model.
The goal of this problem is to find "the maximum value that can be placed in the knapsack within the capacity limit", so it is more likely to be a dynamic programming problem.
Step 1: Think about the decisions in each round, define the state, and thus obtain the \(dp\) table
For each item, if not placed in the knapsack, the knapsack capacity remains unchanged; if placed in, the knapsack capacity decreases. From this, we can derive the state definition: current item number \(i\) and knapsack capacity \(c\), denoted as \([i, c]\).
State \([i, c]\) corresponds to the subproblem: the maximum value among the first \(i\) items in a knapsack of capacity \(c\), denoted as \(dp[i, c]\).
What we need to find is \(dp[n, cap]\), so we need a two-dimensional \(dp\) table of size \((n+1) \times (cap+1)\).
Step 2: Identify the optimal substructure, and then derive the state transition equation
After making the decision for item \(i\), what remains is the subproblem of the first \(i-1\) items, which can be divided into the following two cases.
- Not putting item \(i\): The knapsack capacity remains unchanged, and the state changes to \([i-1, c]\).
- Putting item \(i\): The knapsack capacity decreases by \(wgt[i-1]\), the value increases by \(val[i-1]\), and the state changes to \([i-1, c-wgt[i-1]]\).
The above analysis reveals the optimal substructure of this problem: the maximum value \(dp[i, c]\) equals the greater of the values obtained by not putting item \(i\) into the knapsack and by putting it into the knapsack. From this, the state transition equation can be derived:
Note that if the weight of the current item \(wgt[i - 1]\) exceeds the remaining knapsack capacity \(c\), then the only option is not to put it in the knapsack.
Step 3: Determine boundary conditions and state transition order
When there are no items or the knapsack capacity is \(0\), the maximum value is \(0\), i.e., the first column \(dp[i, 0]\) and the first row \(dp[0, c]\) are both equal to \(0\).
The current state \([i, c]\) transitions from the state above \([i-1, c]\) and the upper-left state \([i-1, c-wgt[i-1]]\), so we can traverse the entire \(dp\) table in forward order using two nested loops.
Based on the above analysis, we will next implement the brute force search, memoization, and dynamic programming solutions in order.
1. Method 1: Brute Force Search¶
The search code includes the following elements.
- Recursive parameters: state \([i, c]\).
- Return value: solution to the subproblem \(dp[i, c]\).
- Termination condition: when there are no items left (\(i = 0\)) or the remaining knapsack capacity is \(0\), terminate the recursion and return value \(0\).
- Pruning: if the weight of the current item exceeds the remaining knapsack capacity, only the option of not putting it in is available.
def knapsack_dfs(wgt: list[int], val: list[int], i: int, c: int) -> int:
"""0-1 knapsack: Brute-force search"""
# If all items have been selected or knapsack has no remaining capacity, return value 0
if i == 0 or c == 0:
return 0
# If exceeds knapsack capacity, can only choose not to put it in
if wgt[i - 1] > c:
return knapsack_dfs(wgt, val, i - 1, c)
# Calculate the maximum value of not putting in and putting in item i
no = knapsack_dfs(wgt, val, i - 1, c)
yes = knapsack_dfs(wgt, val, i - 1, c - wgt[i - 1]) + val[i - 1]
# Return the larger value of the two options
return max(no, yes)
/* 0-1 knapsack: Brute-force search */
int knapsackDFS(vector<int> &wgt, vector<int> &val, int i, int c) {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i == 0 || c == 0) {
return 0;
}
// If exceeds knapsack capacity, can only choose not to put it in
if (wgt[i - 1] > c) {
return knapsackDFS(wgt, val, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
int no = knapsackDFS(wgt, val, i - 1, c);
int yes = knapsackDFS(wgt, val, i - 1, c - wgt[i - 1]) + val[i - 1];
// Return the larger value of the two options
return max(no, yes);
}
/* 0-1 knapsack: Brute-force search */
int knapsackDFS(int[] wgt, int[] val, int i, int c) {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i == 0 || c == 0) {
return 0;
}
// If exceeds knapsack capacity, can only choose not to put it in
if (wgt[i - 1] > c) {
return knapsackDFS(wgt, val, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
int no = knapsackDFS(wgt, val, i - 1, c);
int yes = knapsackDFS(wgt, val, i - 1, c - wgt[i - 1]) + val[i - 1];
// Return the larger value of the two options
return Math.max(no, yes);
}
/* 0-1 knapsack: Brute-force search */
int KnapsackDFS(int[] weight, int[] val, int i, int c) {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i == 0 || c == 0) {
return 0;
}
// If exceeds knapsack capacity, can only choose not to put it in
if (weight[i - 1] > c) {
return KnapsackDFS(weight, val, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
int no = KnapsackDFS(weight, val, i - 1, c);
int yes = KnapsackDFS(weight, val, i - 1, c - weight[i - 1]) + val[i - 1];
// Return the larger value of the two options
return Math.Max(no, yes);
}
/* 0-1 knapsack: Brute-force search */
func knapsackDFS(wgt, val []int, i, c int) int {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if i == 0 || c == 0 {
return 0
}
// If exceeds knapsack capacity, can only choose not to put it in
if wgt[i-1] > c {
return knapsackDFS(wgt, val, i-1, c)
}
// Calculate the maximum value of not putting in and putting in item i
no := knapsackDFS(wgt, val, i-1, c)
yes := knapsackDFS(wgt, val, i-1, c-wgt[i-1]) + val[i-1]
// Return the larger value of the two options
return int(math.Max(float64(no), float64(yes)))
}
/* 0-1 knapsack: Brute-force search */
func knapsackDFS(wgt: [Int], val: [Int], i: Int, c: Int) -> Int {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if i == 0 || c == 0 {
return 0
}
// If exceeds knapsack capacity, can only choose not to put it in
if wgt[i - 1] > c {
return knapsackDFS(wgt: wgt, val: val, i: i - 1, c: c)
}
// Calculate the maximum value of not putting in and putting in item i
let no = knapsackDFS(wgt: wgt, val: val, i: i - 1, c: c)
let yes = knapsackDFS(wgt: wgt, val: val, i: i - 1, c: c - wgt[i - 1]) + val[i - 1]
// Return the larger value of the two options
return max(no, yes)
}
/* 0-1 knapsack: Brute-force search */
function knapsackDFS(wgt, val, i, c) {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i === 0 || c === 0) {
return 0;
}
// If exceeds knapsack capacity, can only choose not to put it in
if (wgt[i - 1] > c) {
return knapsackDFS(wgt, val, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
const no = knapsackDFS(wgt, val, i - 1, c);
const yes = knapsackDFS(wgt, val, i - 1, c - wgt[i - 1]) + val[i - 1];
// Return the larger value of the two options
return Math.max(no, yes);
}
/* 0-1 knapsack: Brute-force search */
function knapsackDFS(
wgt: Array<number>,
val: Array<number>,
i: number,
c: number
): number {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i === 0 || c === 0) {
return 0;
}
// If exceeds knapsack capacity, can only choose not to put it in
if (wgt[i - 1] > c) {
return knapsackDFS(wgt, val, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
const no = knapsackDFS(wgt, val, i - 1, c);
const yes = knapsackDFS(wgt, val, i - 1, c - wgt[i - 1]) + val[i - 1];
// Return the larger value of the two options
return Math.max(no, yes);
}
/* 0-1 knapsack: Brute-force search */
int knapsackDFS(List<int> wgt, List<int> val, int i, int c) {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i == 0 || c == 0) {
return 0;
}
// If exceeds knapsack capacity, can only choose not to put it in
if (wgt[i - 1] > c) {
return knapsackDFS(wgt, val, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
int no = knapsackDFS(wgt, val, i - 1, c);
int yes = knapsackDFS(wgt, val, i - 1, c - wgt[i - 1]) + val[i - 1];
// Return the larger value of the two options
return max(no, yes);
}
/* 0-1 knapsack: Brute-force search */
fn knapsack_dfs(wgt: &[i32], val: &[i32], i: usize, c: usize) -> i32 {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if i == 0 || c == 0 {
return 0;
}
// If exceeds knapsack capacity, can only choose not to put it in
if wgt[i - 1] > c as i32 {
return knapsack_dfs(wgt, val, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
let no = knapsack_dfs(wgt, val, i - 1, c);
let yes = knapsack_dfs(wgt, val, i - 1, c - wgt[i - 1] as usize) + val[i - 1];
// Return the larger value of the two options
std::cmp::max(no, yes)
}
/* 0-1 knapsack: Brute-force search */
int knapsackDFS(int wgt[], int val[], int i, int c) {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i == 0 || c == 0) {
return 0;
}
// If exceeds knapsack capacity, can only choose not to put it in
if (wgt[i - 1] > c) {
return knapsackDFS(wgt, val, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
int no = knapsackDFS(wgt, val, i - 1, c);
int yes = knapsackDFS(wgt, val, i - 1, c - wgt[i - 1]) + val[i - 1];
// Return the larger value of the two options
return myMax(no, yes);
}
/* 0-1 knapsack: Brute-force search */
fun knapsackDFS(
wgt: IntArray,
_val: IntArray,
i: Int,
c: Int
): Int {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i == 0 || c == 0) {
return 0
}
// If exceeds knapsack capacity, can only choose not to put it in
if (wgt[i - 1] > c) {
return knapsackDFS(wgt, _val, i - 1, c)
}
// Calculate the maximum value of not putting in and putting in item i
val no = knapsackDFS(wgt, _val, i - 1, c)
val yes = knapsackDFS(wgt, _val, i - 1, c - wgt[i - 1]) + _val[i - 1]
// Return the larger value of the two options
return max(no, yes)
}
### 0-1 knapsack: brute force search ###
def knapsack_dfs(wgt, val, i, c)
# If all items have been selected or knapsack has no remaining capacity, return value 0
return 0 if i == 0 || c == 0
# If exceeds knapsack capacity, can only choose not to put it in
return knapsack_dfs(wgt, val, i - 1, c) if wgt[i - 1] > c
# Calculate the maximum value of not putting in and putting in item i
no = knapsack_dfs(wgt, val, i - 1, c)
yes = knapsack_dfs(wgt, val, i - 1, c - wgt[i - 1]) + val[i - 1]
# Return the larger value of the two options
[no, yes].max
end
As shown in Figure 14-18, since each item generates two search branches, excluding it and including it, the time complexity is \(O(2^n)\).
Observing the recursion tree, it is easy to see overlapping subproblems, such as \(dp[1, 10]\). When there are many items, large knapsack capacity, and especially many items with the same weight, the number of overlapping subproblems will increase significantly.
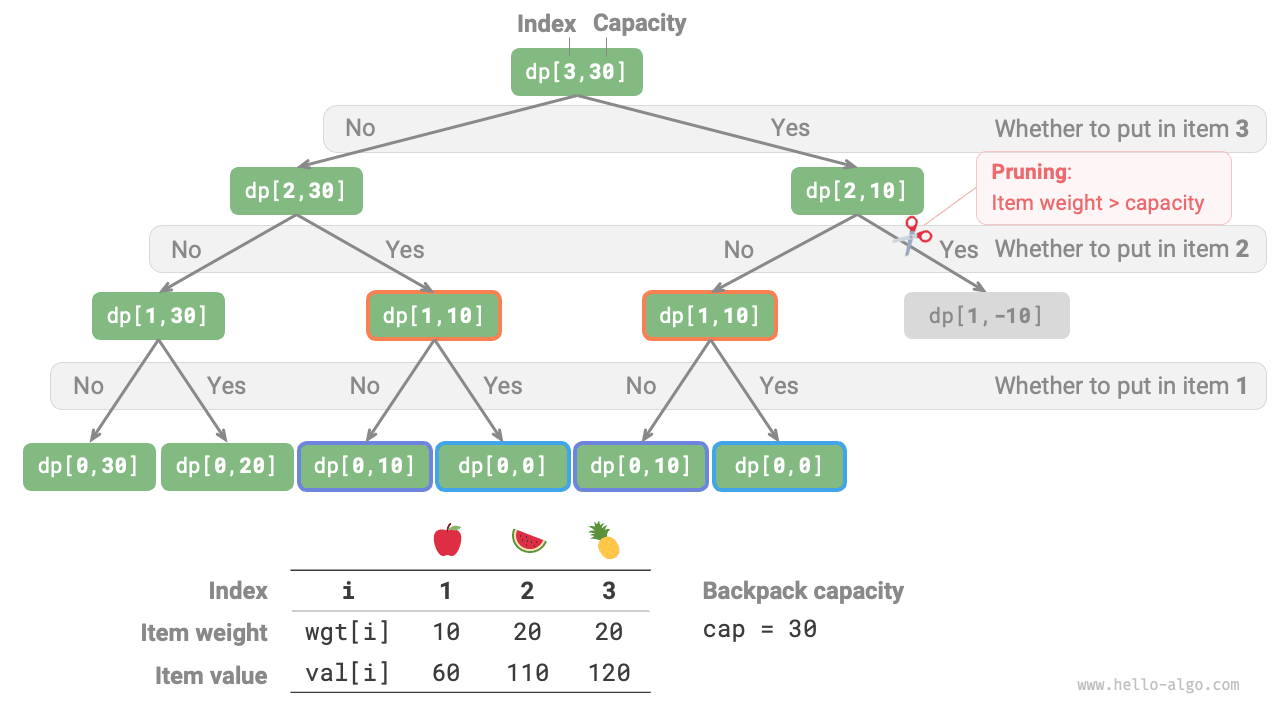
Figure 14-18 Brute force search recursion tree for 0-1 knapsack problem
2. Method 2: Memoization¶
To ensure that overlapping subproblems are only computed once, we use a memo list mem to record the solutions to subproblems, where mem[i][c] corresponds to \(dp[i, c]\).
After introducing memoization, the time complexity depends on the number of subproblems, which is \(O(n \times cap)\). The implementation code is as follows:
def knapsack_dfs_mem(
wgt: list[int], val: list[int], mem: list[list[int]], i: int, c: int
) -> int:
"""0-1 knapsack: Memoization search"""
# If all items have been selected or knapsack has no remaining capacity, return value 0
if i == 0 or c == 0:
return 0
# If there's a record, return it directly
if mem[i][c] != -1:
return mem[i][c]
# If exceeds knapsack capacity, can only choose not to put it in
if wgt[i - 1] > c:
return knapsack_dfs_mem(wgt, val, mem, i - 1, c)
# Calculate the maximum value of not putting in and putting in item i
no = knapsack_dfs_mem(wgt, val, mem, i - 1, c)
yes = knapsack_dfs_mem(wgt, val, mem, i - 1, c - wgt[i - 1]) + val[i - 1]
# Record and return the larger value of the two options
mem[i][c] = max(no, yes)
return mem[i][c]
/* 0-1 knapsack: Memoization search */
int knapsackDFSMem(vector<int> &wgt, vector<int> &val, vector<vector<int>> &mem, int i, int c) {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i == 0 || c == 0) {
return 0;
}
// If there's a record, return it directly
if (mem[i][c] != -1) {
return mem[i][c];
}
// If exceeds knapsack capacity, can only choose not to put it in
if (wgt[i - 1] > c) {
return knapsackDFSMem(wgt, val, mem, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
int no = knapsackDFSMem(wgt, val, mem, i - 1, c);
int yes = knapsackDFSMem(wgt, val, mem, i - 1, c - wgt[i - 1]) + val[i - 1];
// Record and return the larger value of the two options
mem[i][c] = max(no, yes);
return mem[i][c];
}
/* 0-1 knapsack: Memoization search */
int knapsackDFSMem(int[] wgt, int[] val, int[][] mem, int i, int c) {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i == 0 || c == 0) {
return 0;
}
// If there's a record, return it directly
if (mem[i][c] != -1) {
return mem[i][c];
}
// If exceeds knapsack capacity, can only choose not to put it in
if (wgt[i - 1] > c) {
return knapsackDFSMem(wgt, val, mem, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
int no = knapsackDFSMem(wgt, val, mem, i - 1, c);
int yes = knapsackDFSMem(wgt, val, mem, i - 1, c - wgt[i - 1]) + val[i - 1];
// Record and return the larger value of the two options
mem[i][c] = Math.max(no, yes);
return mem[i][c];
}
/* 0-1 knapsack: Memoization search */
int KnapsackDFSMem(int[] weight, int[] val, int[][] mem, int i, int c) {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i == 0 || c == 0) {
return 0;
}
// If there's a record, return it directly
if (mem[i][c] != -1) {
return mem[i][c];
}
// If exceeds knapsack capacity, can only choose not to put it in
if (weight[i - 1] > c) {
return KnapsackDFSMem(weight, val, mem, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
int no = KnapsackDFSMem(weight, val, mem, i - 1, c);
int yes = KnapsackDFSMem(weight, val, mem, i - 1, c - weight[i - 1]) + val[i - 1];
// Record and return the larger value of the two options
mem[i][c] = Math.Max(no, yes);
return mem[i][c];
}
/* 0-1 knapsack: Memoization search */
func knapsackDFSMem(wgt, val []int, mem [][]int, i, c int) int {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if i == 0 || c == 0 {
return 0
}
// If there's a record, return it directly
if mem[i][c] != -1 {
return mem[i][c]
}
// If exceeds knapsack capacity, can only choose not to put it in
if wgt[i-1] > c {
return knapsackDFSMem(wgt, val, mem, i-1, c)
}
// Calculate the maximum value of not putting in and putting in item i
no := knapsackDFSMem(wgt, val, mem, i-1, c)
yes := knapsackDFSMem(wgt, val, mem, i-1, c-wgt[i-1]) + val[i-1]
// Return the larger value of the two options
mem[i][c] = int(math.Max(float64(no), float64(yes)))
return mem[i][c]
}
/* 0-1 knapsack: Memoization search */
func knapsackDFSMem(wgt: [Int], val: [Int], mem: inout [[Int]], i: Int, c: Int) -> Int {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if i == 0 || c == 0 {
return 0
}
// If there's a record, return it directly
if mem[i][c] != -1 {
return mem[i][c]
}
// If exceeds knapsack capacity, can only choose not to put it in
if wgt[i - 1] > c {
return knapsackDFSMem(wgt: wgt, val: val, mem: &mem, i: i - 1, c: c)
}
// Calculate the maximum value of not putting in and putting in item i
let no = knapsackDFSMem(wgt: wgt, val: val, mem: &mem, i: i - 1, c: c)
let yes = knapsackDFSMem(wgt: wgt, val: val, mem: &mem, i: i - 1, c: c - wgt[i - 1]) + val[i - 1]
// Record and return the larger value of the two options
mem[i][c] = max(no, yes)
return mem[i][c]
}
/* 0-1 knapsack: Memoization search */
function knapsackDFSMem(wgt, val, mem, i, c) {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i === 0 || c === 0) {
return 0;
}
// If there's a record, return it directly
if (mem[i][c] !== -1) {
return mem[i][c];
}
// If exceeds knapsack capacity, can only choose not to put it in
if (wgt[i - 1] > c) {
return knapsackDFSMem(wgt, val, mem, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
const no = knapsackDFSMem(wgt, val, mem, i - 1, c);
const yes =
knapsackDFSMem(wgt, val, mem, i - 1, c - wgt[i - 1]) + val[i - 1];
// Record and return the larger value of the two options
mem[i][c] = Math.max(no, yes);
return mem[i][c];
}
/* 0-1 knapsack: Memoization search */
function knapsackDFSMem(
wgt: Array<number>,
val: Array<number>,
mem: Array<Array<number>>,
i: number,
c: number
): number {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i === 0 || c === 0) {
return 0;
}
// If there's a record, return it directly
if (mem[i][c] !== -1) {
return mem[i][c];
}
// If exceeds knapsack capacity, can only choose not to put it in
if (wgt[i - 1] > c) {
return knapsackDFSMem(wgt, val, mem, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
const no = knapsackDFSMem(wgt, val, mem, i - 1, c);
const yes =
knapsackDFSMem(wgt, val, mem, i - 1, c - wgt[i - 1]) + val[i - 1];
// Record and return the larger value of the two options
mem[i][c] = Math.max(no, yes);
return mem[i][c];
}
/* 0-1 knapsack: Memoization search */
int knapsackDFSMem(
List<int> wgt,
List<int> val,
List<List<int>> mem,
int i,
int c,
) {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i == 0 || c == 0) {
return 0;
}
// If there's a record, return it directly
if (mem[i][c] != -1) {
return mem[i][c];
}
// If exceeds knapsack capacity, can only choose not to put it in
if (wgt[i - 1] > c) {
return knapsackDFSMem(wgt, val, mem, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
int no = knapsackDFSMem(wgt, val, mem, i - 1, c);
int yes = knapsackDFSMem(wgt, val, mem, i - 1, c - wgt[i - 1]) + val[i - 1];
// Record and return the larger value of the two options
mem[i][c] = max(no, yes);
return mem[i][c];
}
/* 0-1 knapsack: Memoization search */
fn knapsack_dfs_mem(wgt: &[i32], val: &[i32], mem: &mut Vec<Vec<i32>>, i: usize, c: usize) -> i32 {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if i == 0 || c == 0 {
return 0;
}
// If there's a record, return it directly
if mem[i][c] != -1 {
return mem[i][c];
}
// If exceeds knapsack capacity, can only choose not to put it in
if wgt[i - 1] > c as i32 {
return knapsack_dfs_mem(wgt, val, mem, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
let no = knapsack_dfs_mem(wgt, val, mem, i - 1, c);
let yes = knapsack_dfs_mem(wgt, val, mem, i - 1, c - wgt[i - 1] as usize) + val[i - 1];
// Record and return the larger value of the two options
mem[i][c] = std::cmp::max(no, yes);
mem[i][c]
}
/* 0-1 knapsack: Memoization search */
int knapsackDFSMem(int wgt[], int val[], int memCols, int **mem, int i, int c) {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i == 0 || c == 0) {
return 0;
}
// If there's a record, return it directly
if (mem[i][c] != -1) {
return mem[i][c];
}
// If exceeds knapsack capacity, can only choose not to put it in
if (wgt[i - 1] > c) {
return knapsackDFSMem(wgt, val, memCols, mem, i - 1, c);
}
// Calculate the maximum value of not putting in and putting in item i
int no = knapsackDFSMem(wgt, val, memCols, mem, i - 1, c);
int yes = knapsackDFSMem(wgt, val, memCols, mem, i - 1, c - wgt[i - 1]) + val[i - 1];
// Record and return the larger value of the two options
mem[i][c] = myMax(no, yes);
return mem[i][c];
}
/* 0-1 knapsack: Memoization search */
fun knapsackDFSMem(
wgt: IntArray,
_val: IntArray,
mem: Array<IntArray>,
i: Int,
c: Int
): Int {
// If all items have been selected or knapsack has no remaining capacity, return value 0
if (i == 0 || c == 0) {
return 0
}
// If there's a record, return it directly
if (mem[i][c] != -1) {
return mem[i][c]
}
// If exceeds knapsack capacity, can only choose not to put it in
if (wgt[i - 1] > c) {
return knapsackDFSMem(wgt, _val, mem, i - 1, c)
}
// Calculate the maximum value of not putting in and putting in item i
val no = knapsackDFSMem(wgt, _val, mem, i - 1, c)
val yes = knapsackDFSMem(wgt, _val, mem, i - 1, c - wgt[i - 1]) + _val[i - 1]
// Record and return the larger value of the two options
mem[i][c] = max(no, yes)
return mem[i][c]
}
### 0-1 knapsack: memoization search ###
def knapsack_dfs_mem(wgt, val, mem, i, c)
# If all items have been selected or knapsack has no remaining capacity, return value 0
return 0 if i == 0 || c == 0
# If there's a record, return it directly
return mem[i][c] if mem[i][c] != -1
# If exceeds knapsack capacity, can only choose not to put it in
return knapsack_dfs_mem(wgt, val, mem, i - 1, c) if wgt[i - 1] > c
# Calculate the maximum value of not putting in and putting in item i
no = knapsack_dfs_mem(wgt, val, mem, i - 1, c)
yes = knapsack_dfs_mem(wgt, val, mem, i - 1, c - wgt[i - 1]) + val[i - 1]
# Record and return the larger value of the two options
mem[i][c] = [no, yes].max
end
Figure 14-19 shows the search branches pruned in memoization.
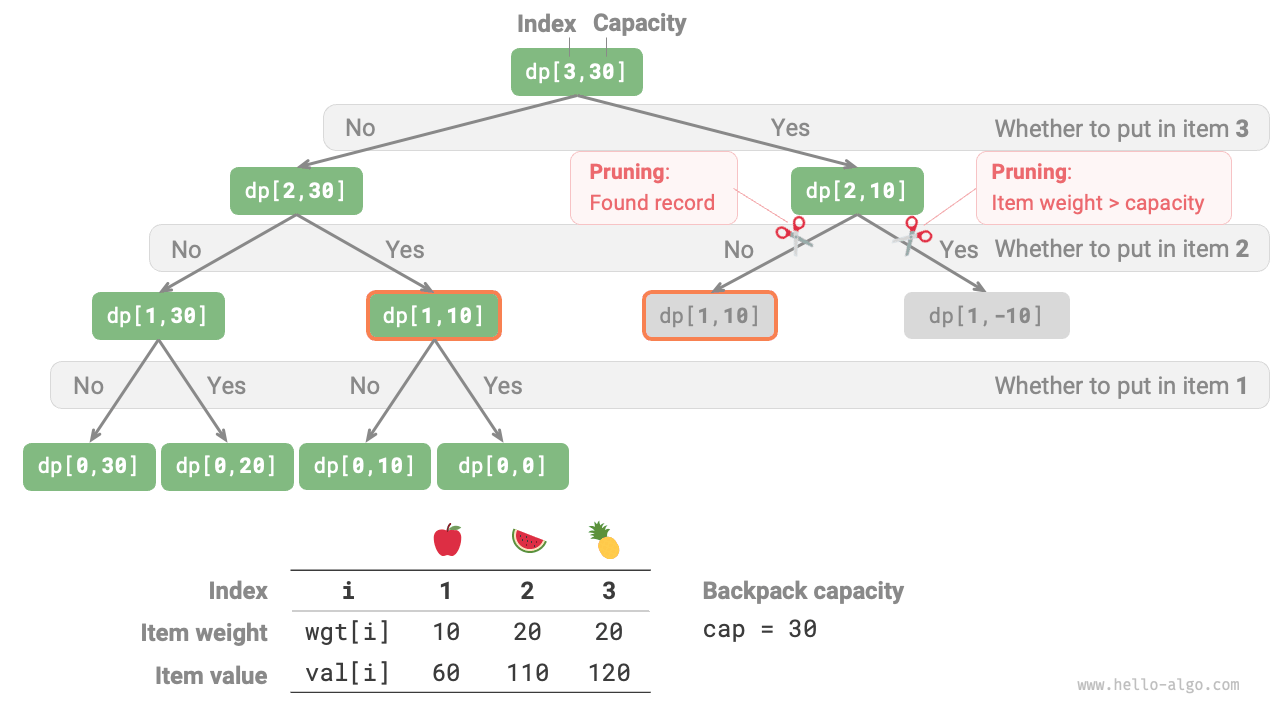
Figure 14-19 Memoization recursion tree for 0-1 knapsack problem
3. Method 3: Dynamic Programming¶
Dynamic programming is essentially the process of filling the \(dp\) table during state transitions. The code is as follows:
def knapsack_dp(wgt: list[int], val: list[int], cap: int) -> int:
"""0-1 knapsack: Dynamic programming"""
n = len(wgt)
# Initialize dp table
dp = [[0] * (cap + 1) for _ in range(n + 1)]
# State transition
for i in range(1, n + 1):
for c in range(1, cap + 1):
if wgt[i - 1] > c:
# If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c]
else:
# The larger value between not selecting and selecting item i
dp[i][c] = max(dp[i - 1][c], dp[i - 1][c - wgt[i - 1]] + val[i - 1])
return dp[n][cap]
/* 0-1 knapsack: Dynamic programming */
int knapsackDP(vector<int> &wgt, vector<int> &val, int cap) {
int n = wgt.size();
// Initialize dp table
vector<vector<int>> dp(n + 1, vector<int>(cap + 1, 0));
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c];
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = max(dp[i - 1][c], dp[i - 1][c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[n][cap];
}
/* 0-1 knapsack: Dynamic programming */
int knapsackDP(int[] wgt, int[] val, int cap) {
int n = wgt.length;
// Initialize dp table
int[][] dp = new int[n + 1][cap + 1];
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c];
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = Math.max(dp[i - 1][c], dp[i - 1][c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[n][cap];
}
/* 0-1 knapsack: Dynamic programming */
int KnapsackDP(int[] weight, int[] val, int cap) {
int n = weight.Length;
// Initialize dp table
int[,] dp = new int[n + 1, cap + 1];
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (weight[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i, c] = dp[i - 1, c];
} else {
// The larger value between not selecting and selecting item i
dp[i, c] = Math.Max(dp[i - 1, c - weight[i - 1]] + val[i - 1], dp[i - 1, c]);
}
}
}
return dp[n, cap];
}
/* 0-1 knapsack: Dynamic programming */
func knapsackDP(wgt, val []int, cap int) int {
n := len(wgt)
// Initialize dp table
dp := make([][]int, n+1)
for i := 0; i <= n; i++ {
dp[i] = make([]int, cap+1)
}
// State transition
for i := 1; i <= n; i++ {
for c := 1; c <= cap; c++ {
if wgt[i-1] > c {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i-1][c]
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = int(math.Max(float64(dp[i-1][c]), float64(dp[i-1][c-wgt[i-1]]+val[i-1])))
}
}
}
return dp[n][cap]
}
/* 0-1 knapsack: Dynamic programming */
func knapsackDP(wgt: [Int], val: [Int], cap: Int) -> Int {
let n = wgt.count
// Initialize dp table
var dp = Array(repeating: Array(repeating: 0, count: cap + 1), count: n + 1)
// State transition
for i in 1 ... n {
for c in 1 ... cap {
if wgt[i - 1] > c {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c]
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = max(dp[i - 1][c], dp[i - 1][c - wgt[i - 1]] + val[i - 1])
}
}
}
return dp[n][cap]
}
/* 0-1 knapsack: Dynamic programming */
function knapsackDP(wgt, val, cap) {
const n = wgt.length;
// Initialize dp table
const dp = Array(n + 1)
.fill(0)
.map(() => Array(cap + 1).fill(0));
// State transition
for (let i = 1; i <= n; i++) {
for (let c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c];
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = Math.max(
dp[i - 1][c],
dp[i - 1][c - wgt[i - 1]] + val[i - 1]
);
}
}
}
return dp[n][cap];
}
/* 0-1 knapsack: Dynamic programming */
function knapsackDP(
wgt: Array<number>,
val: Array<number>,
cap: number
): number {
const n = wgt.length;
// Initialize dp table
const dp = Array.from({ length: n + 1 }, () =>
Array.from({ length: cap + 1 }, () => 0)
);
// State transition
for (let i = 1; i <= n; i++) {
for (let c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c];
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = Math.max(
dp[i - 1][c],
dp[i - 1][c - wgt[i - 1]] + val[i - 1]
);
}
}
}
return dp[n][cap];
}
/* 0-1 knapsack: Dynamic programming */
int knapsackDP(List<int> wgt, List<int> val, int cap) {
int n = wgt.length;
// Initialize dp table
List<List<int>> dp = List.generate(n + 1, (index) => List.filled(cap + 1, 0));
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c];
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = max(dp[i - 1][c], dp[i - 1][c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[n][cap];
}
/* 0-1 knapsack: Dynamic programming */
fn knapsack_dp(wgt: &[i32], val: &[i32], cap: usize) -> i32 {
let n = wgt.len();
// Initialize dp table
let mut dp = vec![vec![0; cap + 1]; n + 1];
// State transition
for i in 1..=n {
for c in 1..=cap {
if wgt[i - 1] > c as i32 {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c];
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = std::cmp::max(
dp[i - 1][c],
dp[i - 1][c - wgt[i - 1] as usize] + val[i - 1],
);
}
}
}
dp[n][cap]
}
/* 0-1 knapsack: Dynamic programming */
int knapsackDP(int wgt[], int val[], int cap, int wgtSize) {
int n = wgtSize;
// Initialize dp table
int **dp = malloc((n + 1) * sizeof(int *));
for (int i = 0; i <= n; i++) {
dp[i] = calloc(cap + 1, sizeof(int));
}
// State transition
for (int i = 1; i <= n; i++) {
for (int c = 1; c <= cap; c++) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c];
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = myMax(dp[i - 1][c], dp[i - 1][c - wgt[i - 1]] + val[i - 1]);
}
}
}
int res = dp[n][cap];
// Free memory
for (int i = 0; i <= n; i++) {
free(dp[i]);
}
return res;
}
/* 0-1 knapsack: Dynamic programming */
fun knapsackDP(wgt: IntArray, _val: IntArray, cap: Int): Int {
val n = wgt.size
// Initialize dp table
val dp = Array(n + 1) { IntArray(cap + 1) }
// State transition
for (i in 1..n) {
for (c in 1..cap) {
if (wgt[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c]
} else {
// The larger value between not selecting and selecting item i
dp[i][c] = max(dp[i - 1][c], dp[i - 1][c - wgt[i - 1]] + _val[i - 1])
}
}
}
return dp[n][cap]
}
### 0-1 knapsack: dynamic programming ###
def knapsack_dp(wgt, val, cap)
n = wgt.length
# Initialize dp table
dp = Array.new(n + 1) { Array.new(cap + 1, 0) }
# State transition
for i in 1...(n + 1)
for c in 1...(cap + 1)
if wgt[i - 1] > c
# If exceeds knapsack capacity, don't select item i
dp[i][c] = dp[i - 1][c]
else
# The larger value between not selecting and selecting item i
dp[i][c] = [dp[i - 1][c], dp[i - 1][c - wgt[i - 1]] + val[i - 1]].max
end
end
end
dp[n][cap]
end
As shown in Figure 14-20, both time complexity and space complexity are determined by the size of the array dp, which is \(O(n \times cap)\).

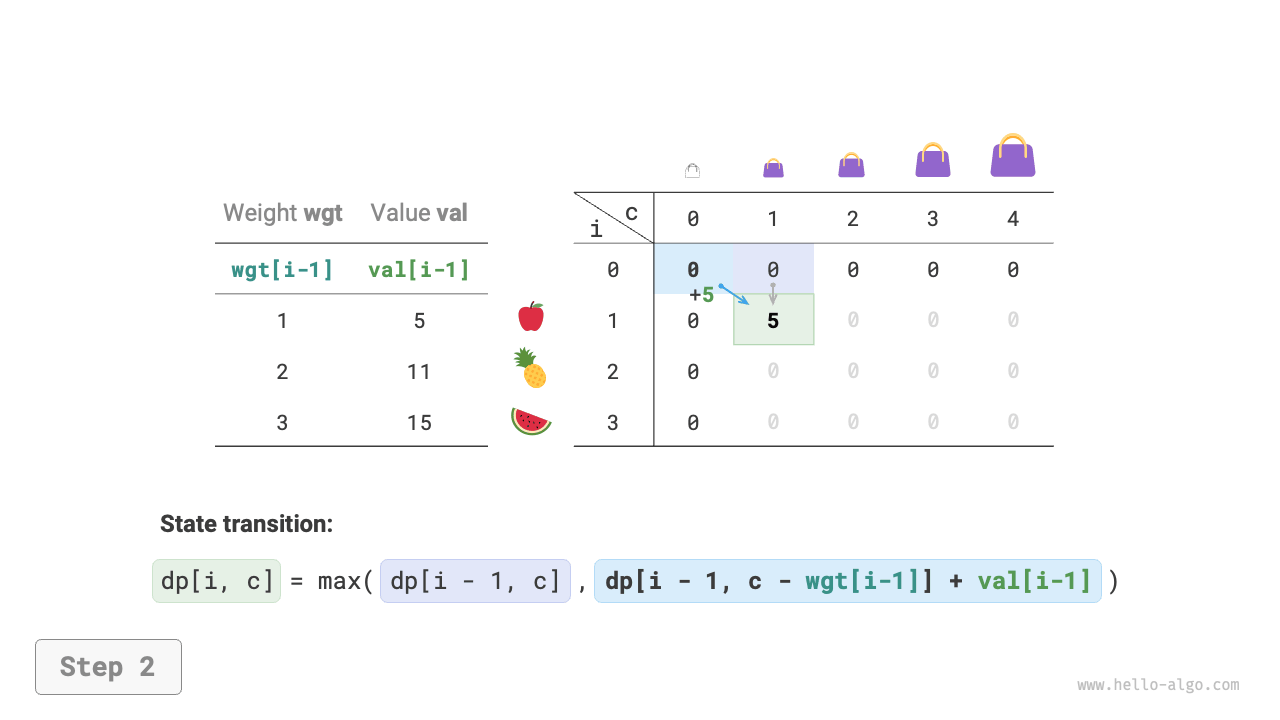

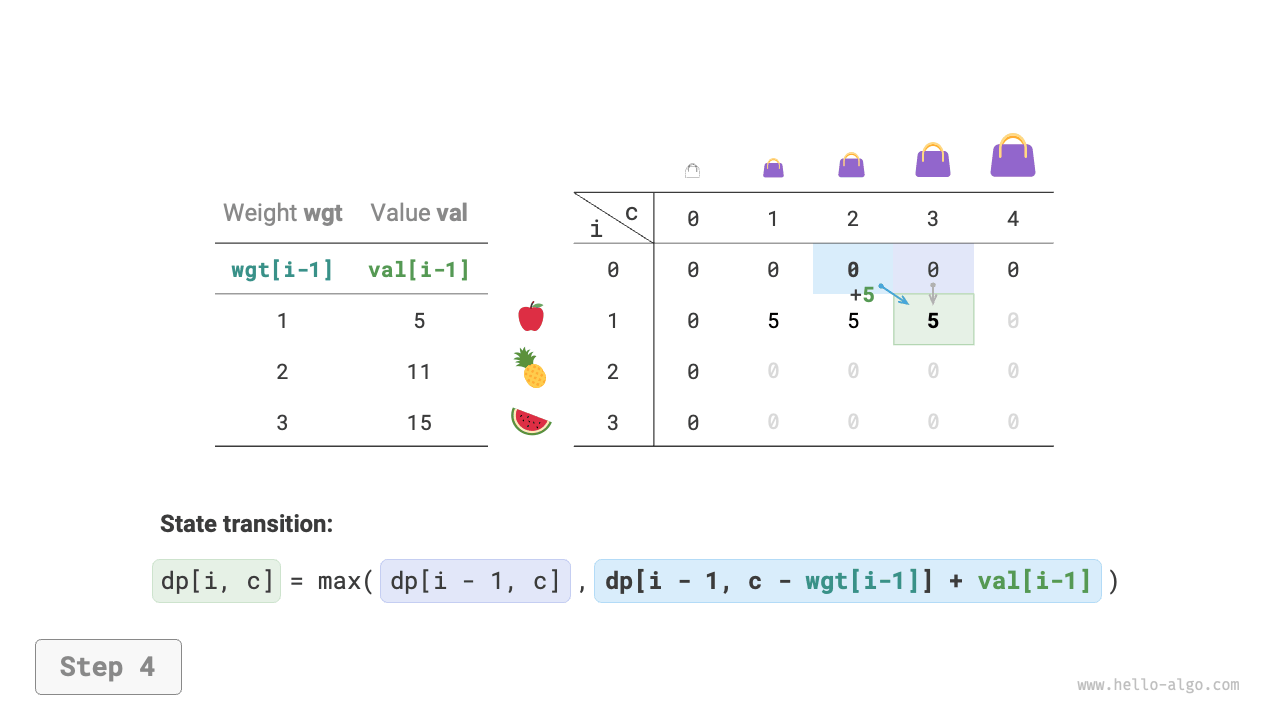
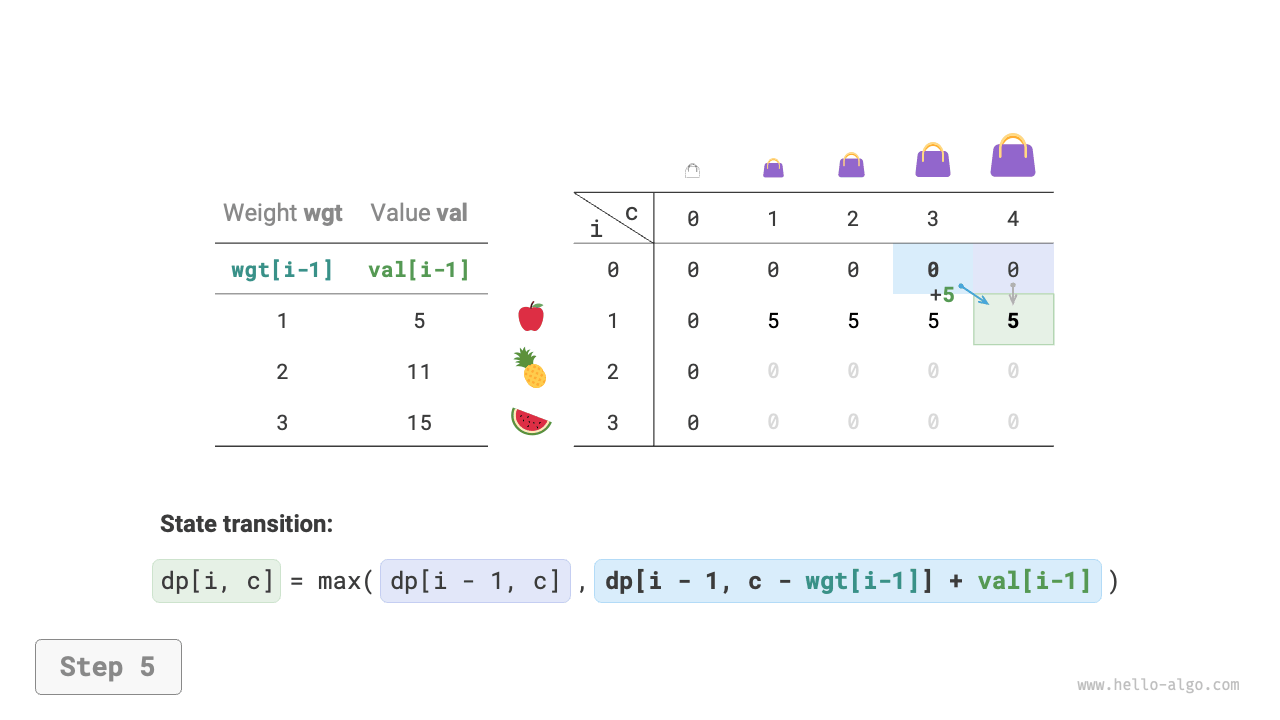


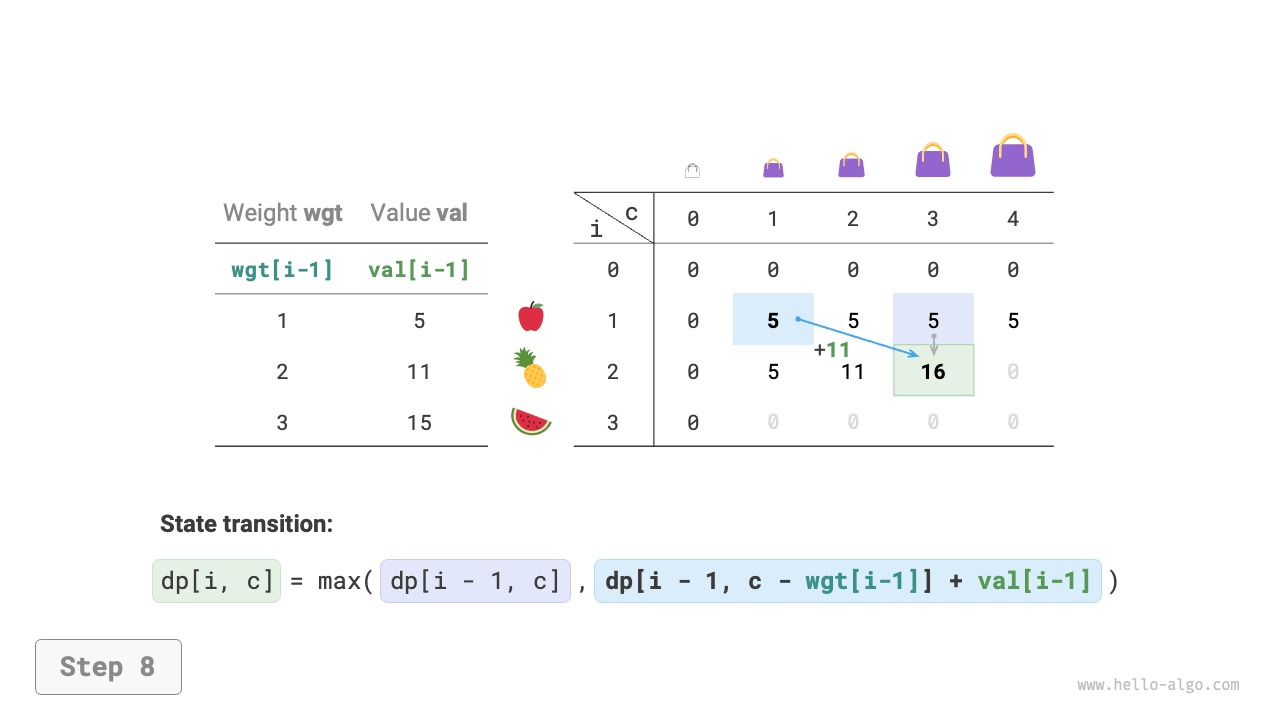
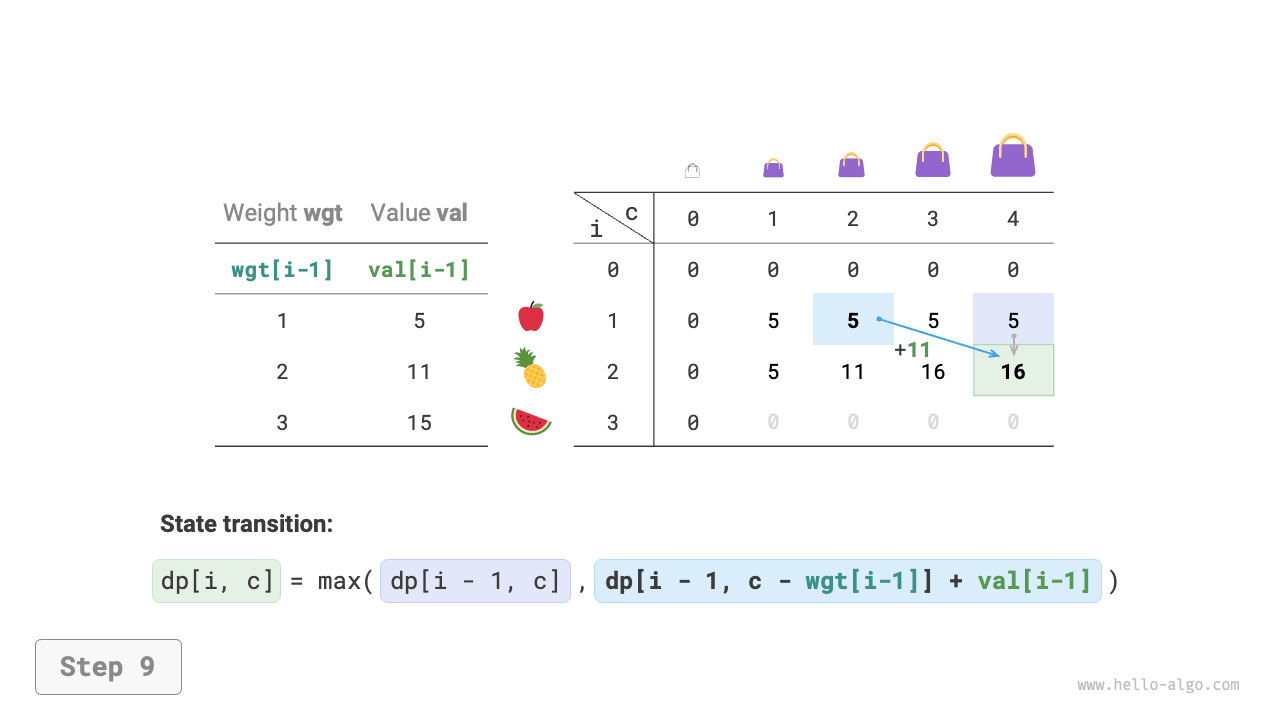
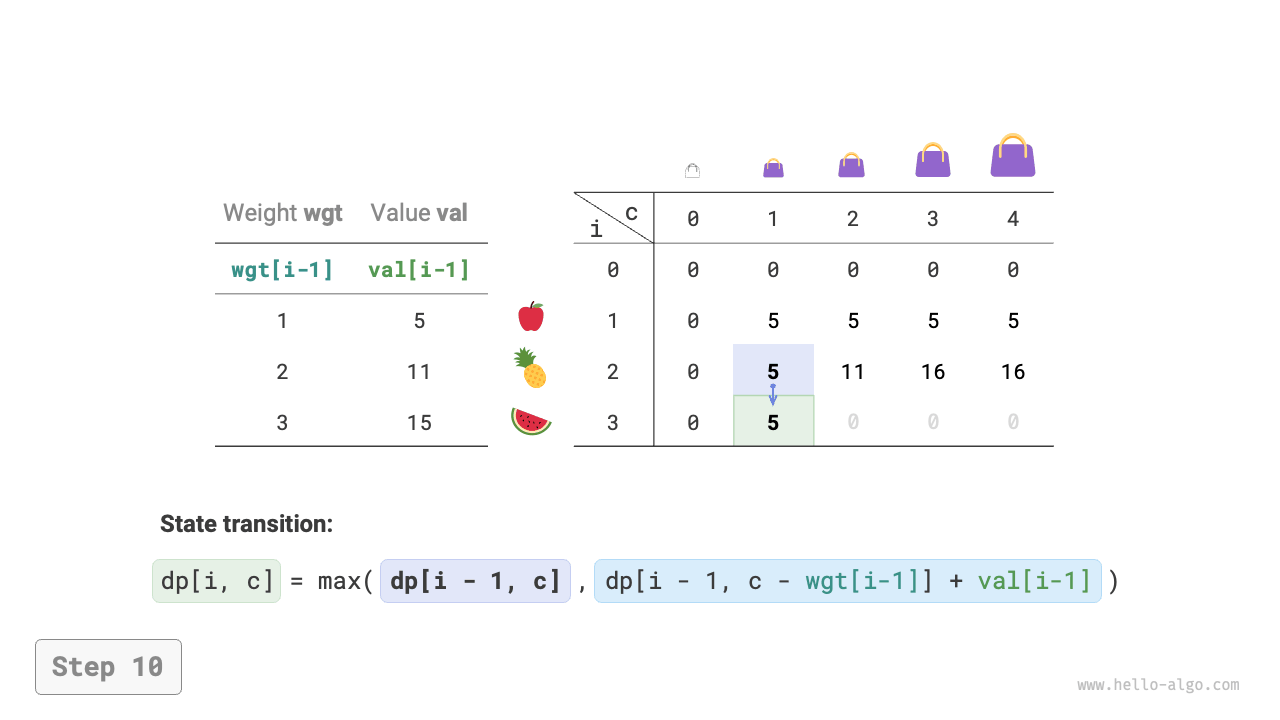
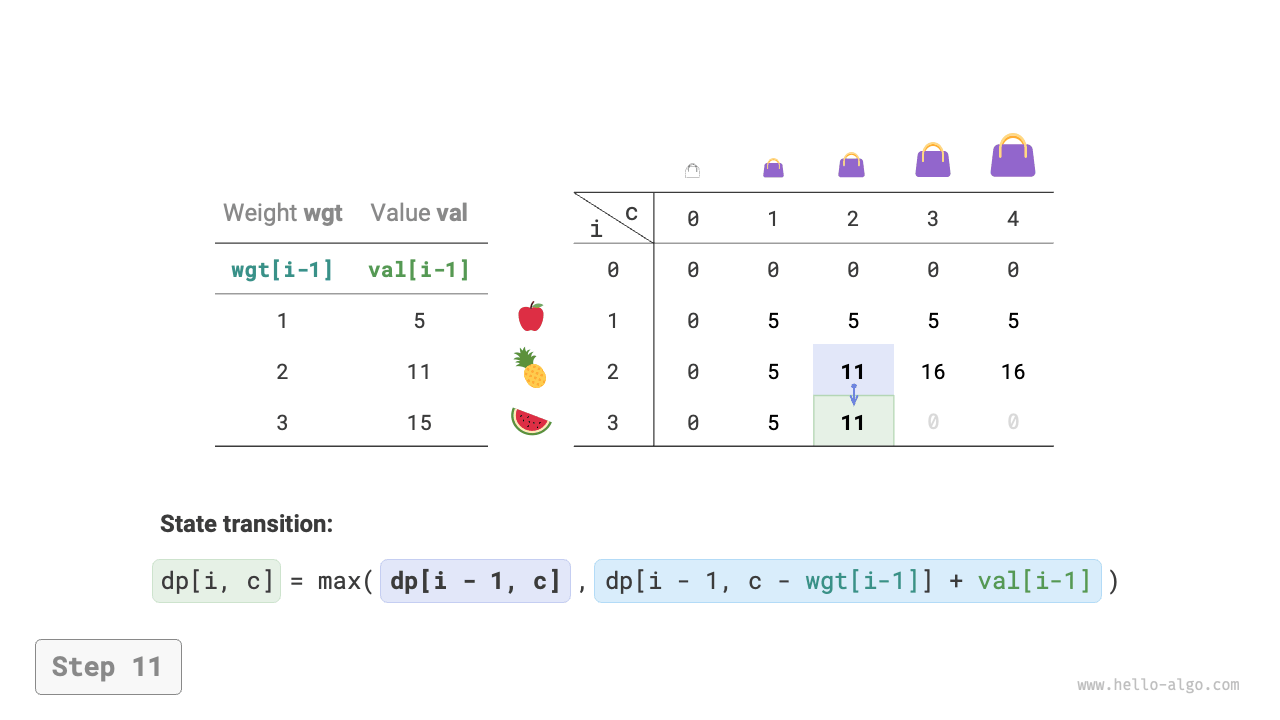
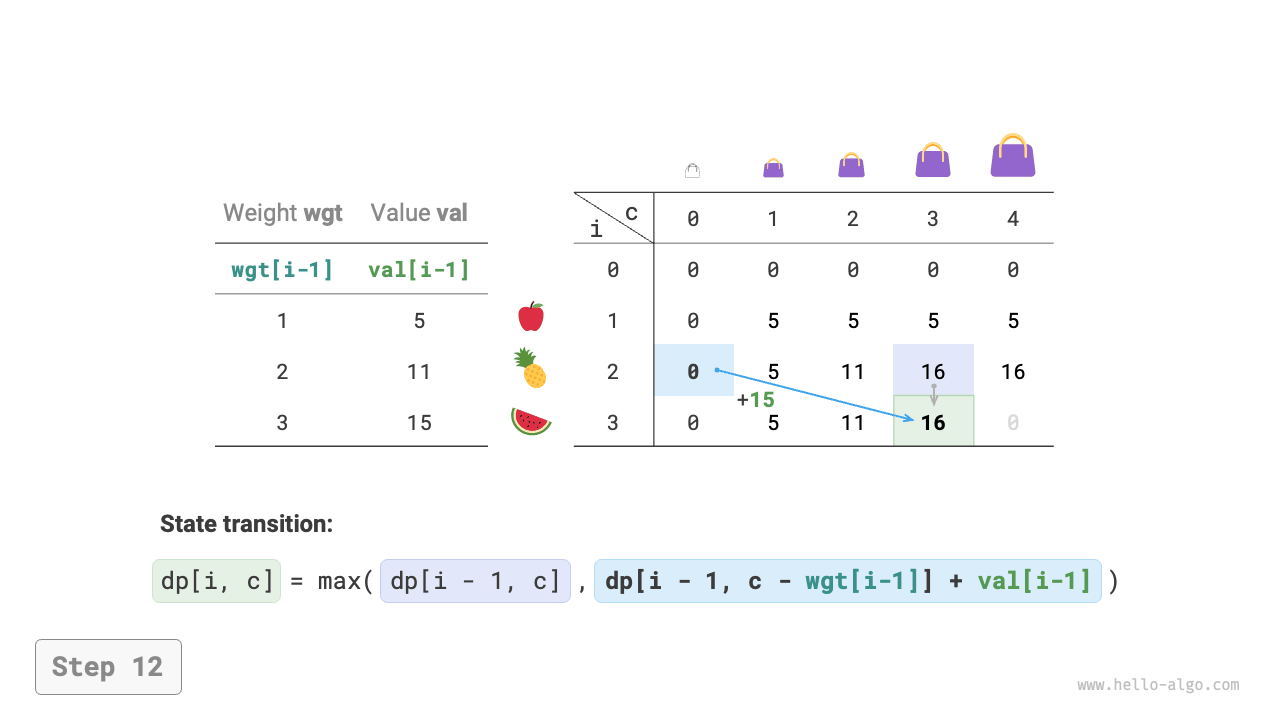
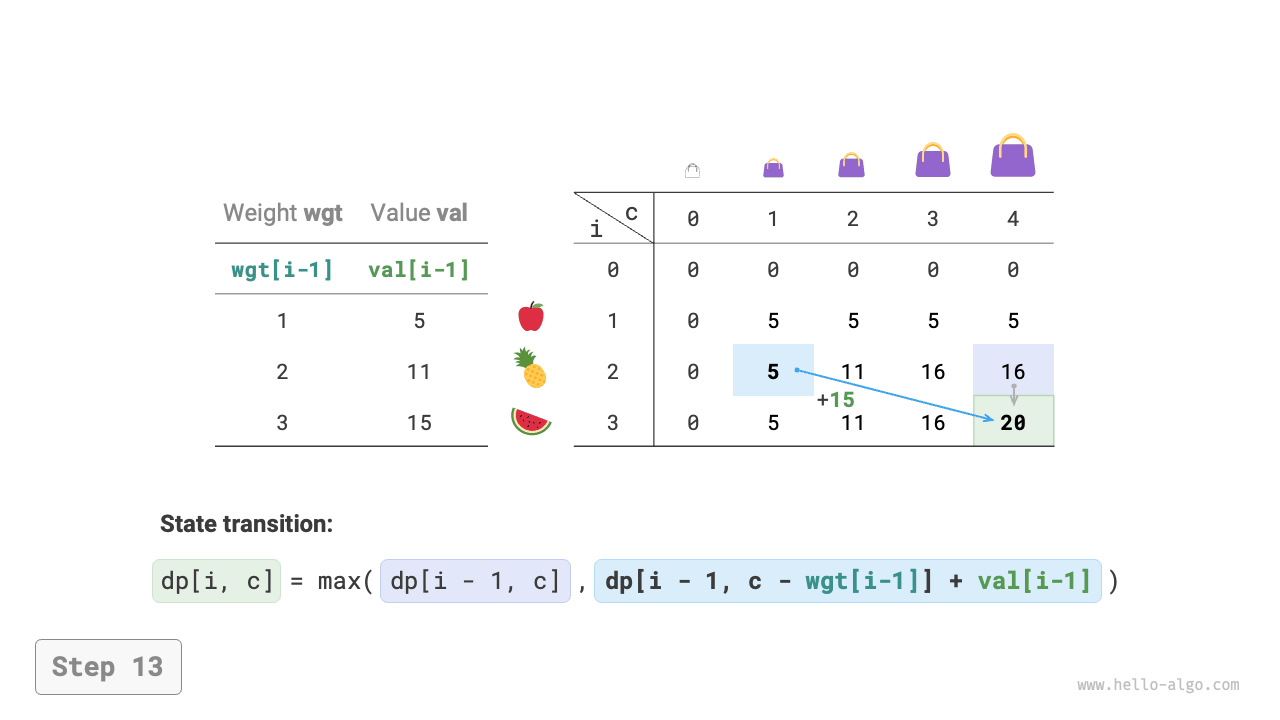
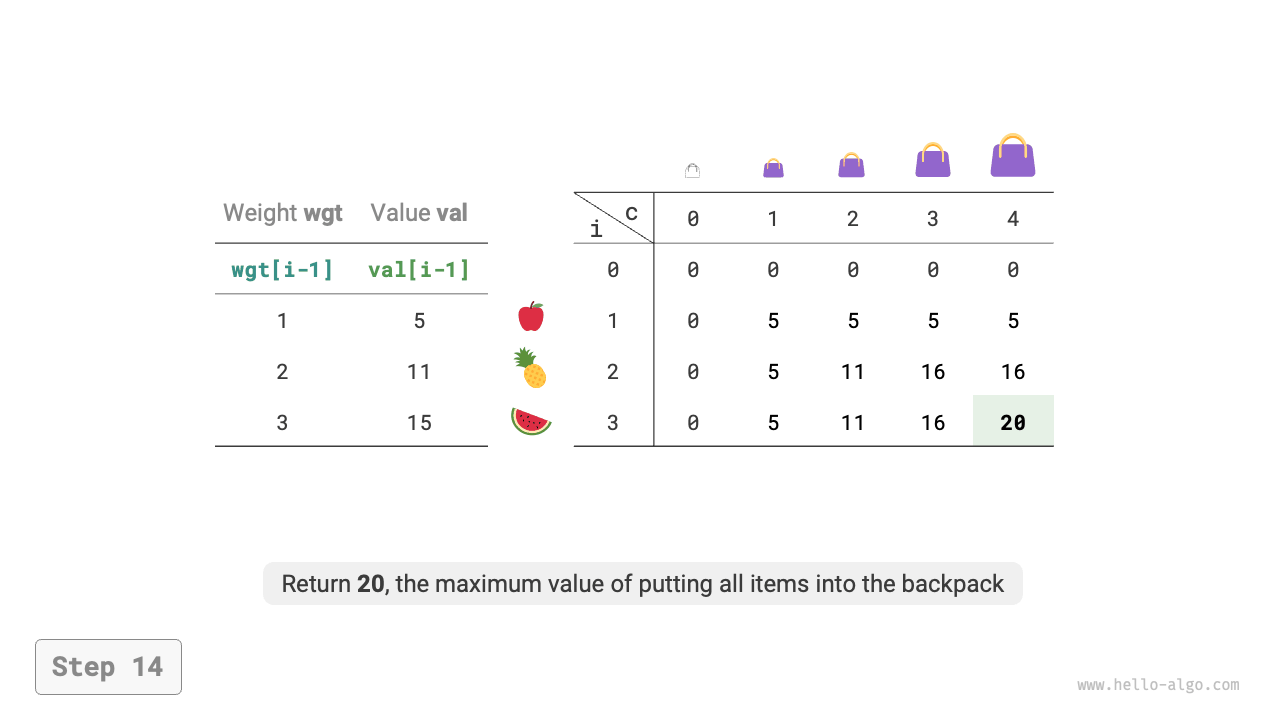
Figure 14-20 Dynamic programming process for 0-1 knapsack problem
4. Space Optimization¶
Since each state is only related to the state in the row above it, we can use two arrays rolling forward to reduce the space complexity from \(O(n^2)\) to \(O(n)\).
Further thinking, can we achieve space optimization using just one array? Observing, we can see that each state is transferred from the cell directly above or the cell in the upper-left. If there is only one array, when we start traversing row \(i\), that array still stores the state of row \(i-1\).
- If using forward traversal, then when traversing to \(dp[i, j]\), the values in the upper-left \(dp[i-1, 1]\) ~ \(dp[i-1, j-1]\) may have already been overwritten, thus preventing correct state transition.
- If using reverse traversal, there will be no overwriting issue, and state transition can proceed correctly.
Figure 14-21 shows the transition process from row \(i = 1\) to row \(i = 2\) using a single array. Please consider the difference between forward and reverse traversal.
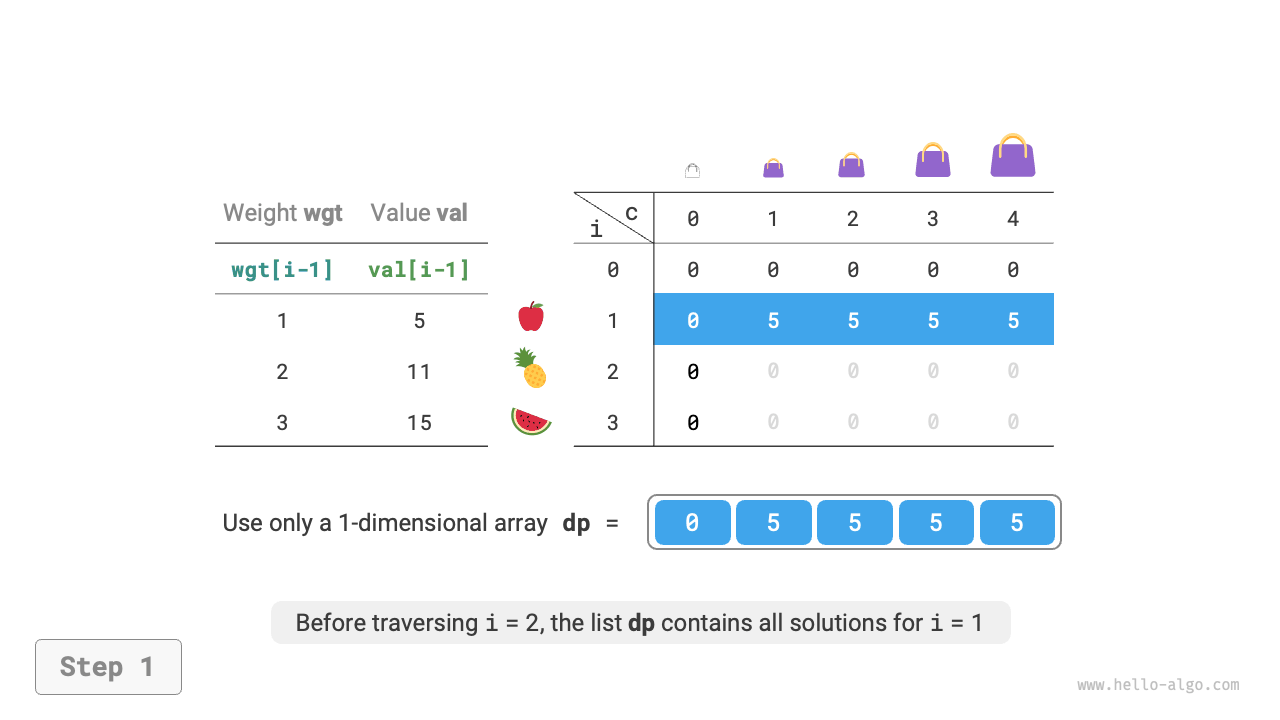
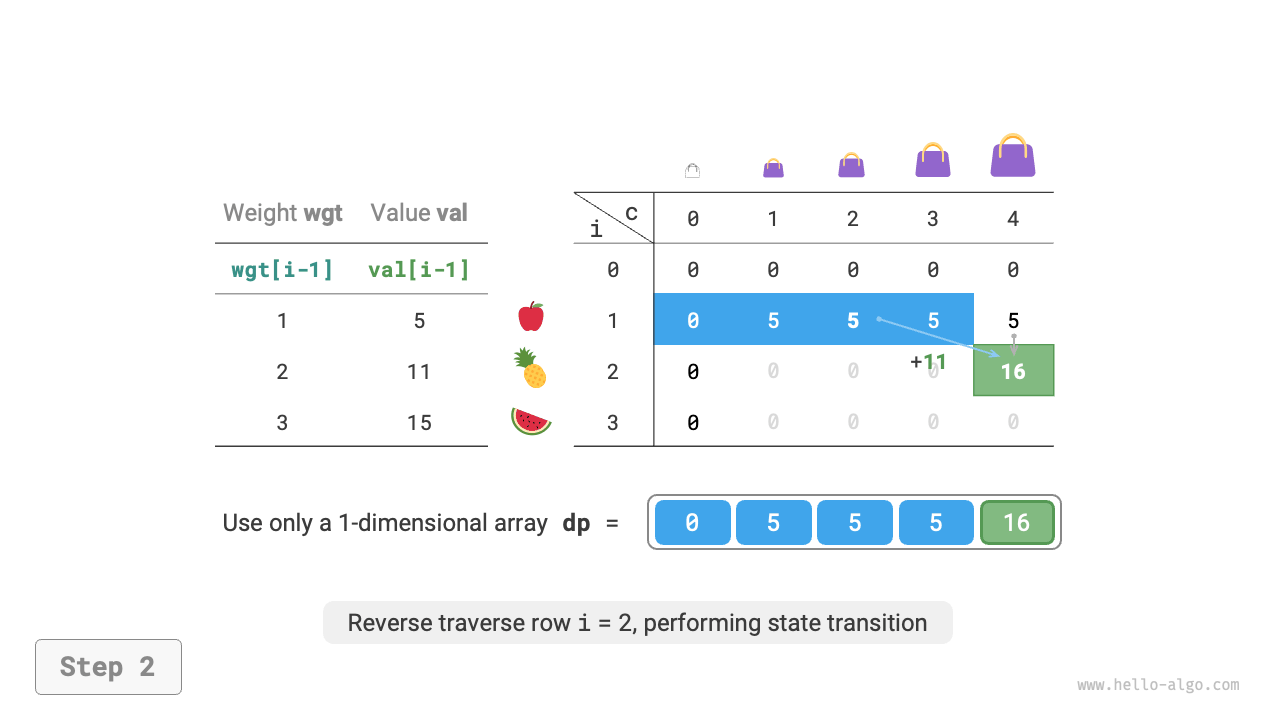




Figure 14-21 Space-optimized dynamic programming process for 0-1 knapsack
In the code implementation, we simply need to delete the first dimension \(i\) of the array dp and change the inner loop to reverse traversal:
def knapsack_dp_comp(wgt: list[int], val: list[int], cap: int) -> int:
"""0-1 knapsack: Space-optimized dynamic programming"""
n = len(wgt)
# Initialize dp table
dp = [0] * (cap + 1)
# State transition
for i in range(1, n + 1):
# Traverse in reverse order
for c in range(cap, 0, -1):
if wgt[i - 1] > c:
# If exceeds knapsack capacity, don't select item i
dp[c] = dp[c]
else:
# The larger value between not selecting and selecting item i
dp[c] = max(dp[c], dp[c - wgt[i - 1]] + val[i - 1])
return dp[cap]
/* 0-1 knapsack: Space-optimized dynamic programming */
int knapsackDPComp(vector<int> &wgt, vector<int> &val, int cap) {
int n = wgt.size();
// Initialize dp table
vector<int> dp(cap + 1, 0);
// State transition
for (int i = 1; i <= n; i++) {
// Traverse in reverse order
for (int c = cap; c >= 1; c--) {
if (wgt[i - 1] <= c) {
// The larger value between not selecting and selecting item i
dp[c] = max(dp[c], dp[c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[cap];
}
/* 0-1 knapsack: Space-optimized dynamic programming */
int knapsackDPComp(int[] wgt, int[] val, int cap) {
int n = wgt.length;
// Initialize dp table
int[] dp = new int[cap + 1];
// State transition
for (int i = 1; i <= n; i++) {
// Traverse in reverse order
for (int c = cap; c >= 1; c--) {
if (wgt[i - 1] <= c) {
// The larger value between not selecting and selecting item i
dp[c] = Math.max(dp[c], dp[c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[cap];
}
/* 0-1 knapsack: Space-optimized dynamic programming */
int KnapsackDPComp(int[] weight, int[] val, int cap) {
int n = weight.Length;
// Initialize dp table
int[] dp = new int[cap + 1];
// State transition
for (int i = 1; i <= n; i++) {
// Traverse in reverse order
for (int c = cap; c > 0; c--) {
if (weight[i - 1] > c) {
// If exceeds knapsack capacity, don't select item i
dp[c] = dp[c];
} else {
// The larger value between not selecting and selecting item i
dp[c] = Math.Max(dp[c], dp[c - weight[i - 1]] + val[i - 1]);
}
}
}
return dp[cap];
}
/* 0-1 knapsack: Space-optimized dynamic programming */
func knapsackDPComp(wgt, val []int, cap int) int {
n := len(wgt)
// Initialize dp table
dp := make([]int, cap+1)
// State transition
for i := 1; i <= n; i++ {
// Traverse in reverse order
for c := cap; c >= 1; c-- {
if wgt[i-1] <= c {
// The larger value between not selecting and selecting item i
dp[c] = int(math.Max(float64(dp[c]), float64(dp[c-wgt[i-1]]+val[i-1])))
}
}
}
return dp[cap]
}
/* 0-1 knapsack: Space-optimized dynamic programming */
func knapsackDPComp(wgt: [Int], val: [Int], cap: Int) -> Int {
let n = wgt.count
// Initialize dp table
var dp = Array(repeating: 0, count: cap + 1)
// State transition
for i in 1 ... n {
// Traverse in reverse order
for c in (1 ... cap).reversed() {
if wgt[i - 1] <= c {
// The larger value between not selecting and selecting item i
dp[c] = max(dp[c], dp[c - wgt[i - 1]] + val[i - 1])
}
}
}
return dp[cap]
}
/* 0-1 knapsack: Space-optimized dynamic programming */
function knapsackDPComp(wgt, val, cap) {
const n = wgt.length;
// Initialize dp table
const dp = Array(cap + 1).fill(0);
// State transition
for (let i = 1; i <= n; i++) {
// Traverse in reverse order
for (let c = cap; c >= 1; c--) {
if (wgt[i - 1] <= c) {
// The larger value between not selecting and selecting item i
dp[c] = Math.max(dp[c], dp[c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[cap];
}
/* 0-1 knapsack: Space-optimized dynamic programming */
function knapsackDPComp(
wgt: Array<number>,
val: Array<number>,
cap: number
): number {
const n = wgt.length;
// Initialize dp table
const dp = Array(cap + 1).fill(0);
// State transition
for (let i = 1; i <= n; i++) {
// Traverse in reverse order
for (let c = cap; c >= 1; c--) {
if (wgt[i - 1] <= c) {
// The larger value between not selecting and selecting item i
dp[c] = Math.max(dp[c], dp[c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[cap];
}
/* 0-1 knapsack: Space-optimized dynamic programming */
int knapsackDPComp(List<int> wgt, List<int> val, int cap) {
int n = wgt.length;
// Initialize dp table
List<int> dp = List.filled(cap + 1, 0);
// State transition
for (int i = 1; i <= n; i++) {
// Traverse in reverse order
for (int c = cap; c >= 1; c--) {
if (wgt[i - 1] <= c) {
// The larger value between not selecting and selecting item i
dp[c] = max(dp[c], dp[c - wgt[i - 1]] + val[i - 1]);
}
}
}
return dp[cap];
}
/* 0-1 knapsack: Space-optimized dynamic programming */
fn knapsack_dp_comp(wgt: &[i32], val: &[i32], cap: usize) -> i32 {
let n = wgt.len();
// Initialize dp table
let mut dp = vec![0; cap + 1];
// State transition
for i in 1..=n {
// Traverse in reverse order
for c in (1..=cap).rev() {
if wgt[i - 1] <= c as i32 {
// The larger value between not selecting and selecting item i
dp[c] = std::cmp::max(dp[c], dp[c - wgt[i - 1] as usize] + val[i - 1]);
}
}
}
dp[cap]
}
/* 0-1 knapsack: Space-optimized dynamic programming */
int knapsackDPComp(int wgt[], int val[], int cap, int wgtSize) {
int n = wgtSize;
// Initialize dp table
int *dp = calloc(cap + 1, sizeof(int));
// State transition
for (int i = 1; i <= n; i++) {
// Traverse in reverse order
for (int c = cap; c >= 1; c--) {
if (wgt[i - 1] <= c) {
// The larger value between not selecting and selecting item i
dp[c] = myMax(dp[c], dp[c - wgt[i - 1]] + val[i - 1]);
}
}
}
int res = dp[cap];
// Free memory
free(dp);
return res;
}
/* 0-1 knapsack: Space-optimized dynamic programming */
fun knapsackDPComp(wgt: IntArray, _val: IntArray, cap: Int): Int {
val n = wgt.size
// Initialize dp table
val dp = IntArray(cap + 1)
// State transition
for (i in 1..n) {
// Traverse in reverse order
for (c in cap downTo 1) {
if (wgt[i - 1] <= c) {
// The larger value between not selecting and selecting item i
dp[c] = max(dp[c], dp[c - wgt[i - 1]] + _val[i - 1])
}
}
}
return dp[cap]
}
### 0-1 knapsack: space-optimized DP ###
def knapsack_dp_comp(wgt, val, cap)
n = wgt.length
# Initialize dp table
dp = Array.new(cap + 1, 0)
# State transition
for i in 1...(n + 1)
# Traverse in reverse order
for c in cap.downto(1)
if wgt[i - 1] > c
# If exceeds knapsack capacity, don't select item i
dp[c] = dp[c]
else
# The larger value between not selecting and selecting item i
dp[c] = [dp[c], dp[c - wgt[i - 1]] + val[i - 1]].max
end
end
end
dp[cap]
end