11.8 Bucket Sort¶
The sorting algorithms discussed earlier are all comparison-based sorting algorithms, which sort by comparing the relative order of elements. The time complexity of such algorithms cannot beat \(O(n \log n)\). Next, we will explore several non-comparison sorting algorithms, whose time complexity can be linear.
Bucket sort is a typical application of the divide-and-conquer strategy. It works by creating a sequence of ordered buckets, each corresponding to a data range, and distributing the data evenly among them. The elements within each bucket are then sorted separately. Finally, all buckets are merged in order.
11.8.1 Algorithm Flow¶
Consider an array of length \(n\), whose elements are floating-point numbers in the range \([0, 1)\). The flow of bucket sort is shown in Figure 11-13.
- Initialize \(k\) buckets and distribute the \(n\) elements into the \(k\) buckets.
- Sort each bucket separately (here we use the built-in sorting function of the programming language).
- Merge the results in order from smallest to largest bucket.
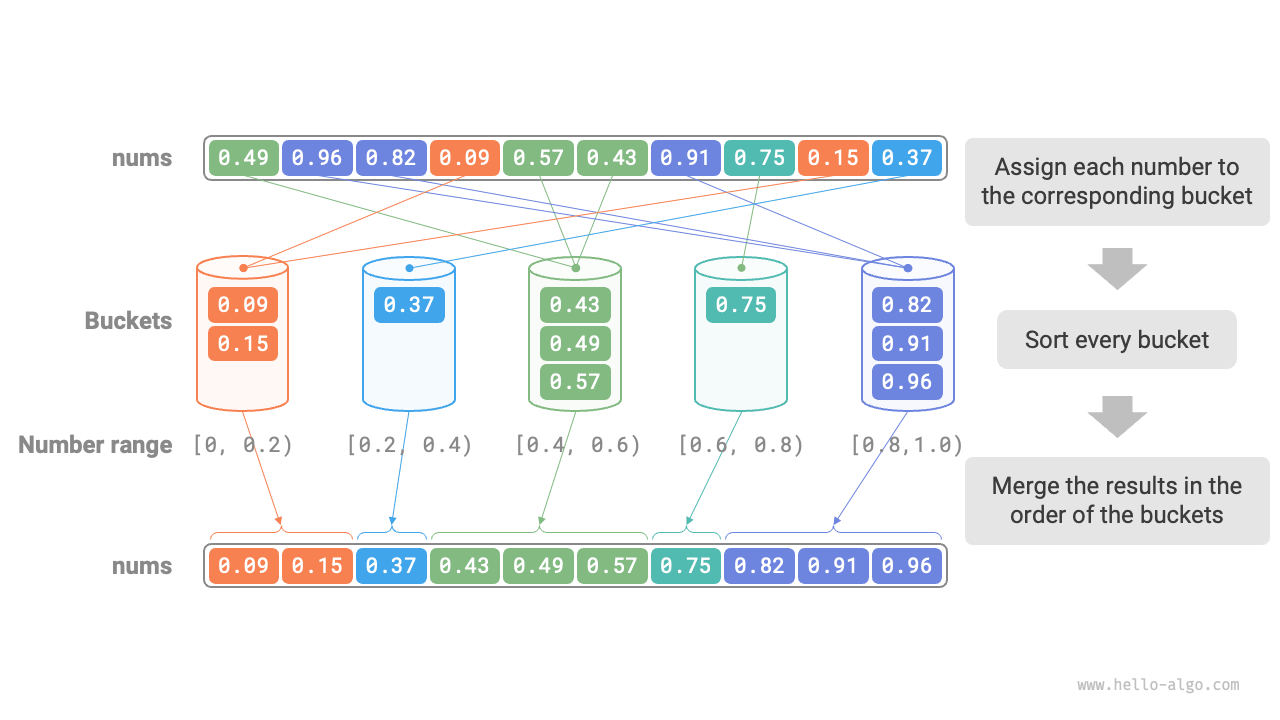
Figure 11-13 Bucket sort algorithm flow
The code is as follows:
def bucket_sort(nums: list[float]):
"""Bucket sort"""
# Initialize k = n/2 buckets, expected to allocate 2 elements per bucket
k = len(nums) // 2
buckets = [[] for _ in range(k)]
# 1. Distribute array elements into various buckets
for num in nums:
# Input data range is [0, 1), use num * k to map to index range [0, k-1]
i = int(num * k)
# Add num to bucket i
buckets[i].append(num)
# 2. Sort each bucket
for bucket in buckets:
# Use built-in sorting function, can also replace with other sorting algorithms
bucket.sort()
# 3. Traverse buckets to merge results
i = 0
for bucket in buckets:
for num in bucket:
nums[i] = num
i += 1
/* Bucket sort */
void bucketSort(vector<float> &nums) {
// Initialize k = n/2 buckets, expected to allocate 2 elements per bucket
int k = nums.size() / 2;
vector<vector<float>> buckets(k);
// 1. Distribute array elements into various buckets
for (float num : nums) {
// Input data range is [0, 1), use num * k to map to index range [0, k-1]
int i = num * k;
// Add num to bucket bucket_idx
buckets[i].push_back(num);
}
// 2. Sort each bucket
for (vector<float> &bucket : buckets) {
// Use built-in sorting function, can also replace with other sorting algorithms
sort(bucket.begin(), bucket.end());
}
// 3. Traverse buckets to merge results
int i = 0;
for (vector<float> &bucket : buckets) {
for (float num : bucket) {
nums[i++] = num;
}
}
}
/* Bucket sort */
void bucketSort(float[] nums) {
// Initialize k = n/2 buckets, expected to allocate 2 elements per bucket
int k = nums.length / 2;
List<List<Float>> buckets = new ArrayList<>();
for (int i = 0; i < k; i++) {
buckets.add(new ArrayList<>());
}
// 1. Distribute array elements into various buckets
for (float num : nums) {
// Input data range is [0, 1), use num * k to map to index range [0, k-1]
int i = (int) (num * k);
// Add num to bucket i
buckets.get(i).add(num);
}
// 2. Sort each bucket
for (List<Float> bucket : buckets) {
// Use built-in sorting function, can also replace with other sorting algorithms
Collections.sort(bucket);
}
// 3. Traverse buckets to merge results
int i = 0;
for (List<Float> bucket : buckets) {
for (float num : bucket) {
nums[i++] = num;
}
}
}
/* Bucket sort */
void BucketSort(float[] nums) {
// Initialize k = n/2 buckets, expected to allocate 2 elements per bucket
int k = nums.Length / 2;
List<List<float>> buckets = [];
for (int i = 0; i < k; i++) {
buckets.Add([]);
}
// 1. Distribute array elements into various buckets
foreach (float num in nums) {
// Input data range is [0, 1), use num * k to map to index range [0, k-1]
int i = (int)(num * k);
// Add num to bucket i
buckets[i].Add(num);
}
// 2. Sort each bucket
foreach (List<float> bucket in buckets) {
// Use built-in sorting function, can also replace with other sorting algorithms
bucket.Sort();
}
// 3. Traverse buckets to merge results
int j = 0;
foreach (List<float> bucket in buckets) {
foreach (float num in bucket) {
nums[j++] = num;
}
}
}
/* Bucket sort */
func bucketSort(nums []float64) {
// Initialize k = n/2 buckets, expected to allocate 2 elements per bucket
k := len(nums) / 2
buckets := make([][]float64, k)
for i := 0; i < k; i++ {
buckets[i] = make([]float64, 0)
}
// 1. Distribute array elements into various buckets
for _, num := range nums {
// Input data range is [0, 1), use num * k to map to index range [0, k-1]
i := int(num * float64(k))
// Add num to bucket i
buckets[i] = append(buckets[i], num)
}
// 2. Sort each bucket
for i := 0; i < k; i++ {
// Use built-in slice sorting function, can also be replaced with other sorting algorithms
sort.Float64s(buckets[i])
}
// 3. Traverse buckets to merge results
i := 0
for _, bucket := range buckets {
for _, num := range bucket {
nums[i] = num
i++
}
}
}
/* Bucket sort */
func bucketSort(nums: inout [Double]) {
// Initialize k = n/2 buckets, expected to allocate 2 elements per bucket
let k = nums.count / 2
var buckets = (0 ..< k).map { _ in [Double]() }
// 1. Distribute array elements into various buckets
for num in nums {
// Input data range is [0, 1), use num * k to map to index range [0, k-1]
let i = Int(num * Double(k))
// Add num to bucket i
buckets[i].append(num)
}
// 2. Sort each bucket
for i in buckets.indices {
// Use built-in sorting function, can also replace with other sorting algorithms
buckets[i].sort()
}
// 3. Traverse buckets to merge results
var i = nums.startIndex
for bucket in buckets {
for num in bucket {
nums[i] = num
i += 1
}
}
}
/* Bucket sort */
function bucketSort(nums) {
// Initialize k = n/2 buckets, expected to allocate 2 elements per bucket
const k = nums.length / 2;
const buckets = [];
for (let i = 0; i < k; i++) {
buckets.push([]);
}
// 1. Distribute array elements into various buckets
for (const num of nums) {
// Input data range is [0, 1), use num * k to map to index range [0, k-1]
const i = Math.floor(num * k);
// Add num to bucket i
buckets[i].push(num);
}
// 2. Sort each bucket
for (const bucket of buckets) {
// Use built-in sorting function, can also replace with other sorting algorithms
bucket.sort((a, b) => a - b);
}
// 3. Traverse buckets to merge results
let i = 0;
for (const bucket of buckets) {
for (const num of bucket) {
nums[i++] = num;
}
}
}
/* Bucket sort */
function bucketSort(nums: number[]): void {
// Initialize k = n/2 buckets, expected to allocate 2 elements per bucket
const k = nums.length / 2;
const buckets: number[][] = [];
for (let i = 0; i < k; i++) {
buckets.push([]);
}
// 1. Distribute array elements into various buckets
for (const num of nums) {
// Input data range is [0, 1), use num * k to map to index range [0, k-1]
const i = Math.floor(num * k);
// Add num to bucket i
buckets[i].push(num);
}
// 2. Sort each bucket
for (const bucket of buckets) {
// Use built-in sorting function, can also replace with other sorting algorithms
bucket.sort((a, b) => a - b);
}
// 3. Traverse buckets to merge results
let i = 0;
for (const bucket of buckets) {
for (const num of bucket) {
nums[i++] = num;
}
}
}
/* Bucket sort */
void bucketSort(List<double> nums) {
// Initialize k = n/2 buckets, expected to allocate 2 elements per bucket
int k = nums.length ~/ 2;
List<List<double>> buckets = List.generate(k, (index) => []);
// 1. Distribute array elements into various buckets
for (double _num in nums) {
// Input data range is [0, 1), use _num * k to map to index range [0, k-1]
int i = (_num * k).toInt();
// Add _num to bucket bucket_idx
buckets[i].add(_num);
}
// 2. Sort each bucket
for (List<double> bucket in buckets) {
bucket.sort();
}
// 3. Traverse buckets to merge results
int i = 0;
for (List<double> bucket in buckets) {
for (double _num in bucket) {
nums[i++] = _num;
}
}
}
/* Bucket sort */
fn bucket_sort(nums: &mut [f64]) {
// Initialize k = n/2 buckets, expected to allocate 2 elements per bucket
let k = nums.len() / 2;
let mut buckets = vec![vec![]; k];
// 1. Distribute array elements into various buckets
for &num in nums.iter() {
// Input data range is [0, 1), use num * k to map to index range [0, k-1]
let i = (num * k as f64) as usize;
// Add num to bucket i
buckets[i].push(num);
}
// 2. Sort each bucket
for bucket in &mut buckets {
// Use built-in sorting function, can also replace with other sorting algorithms
bucket.sort_by(|a, b| a.partial_cmp(b).unwrap());
}
// 3. Traverse buckets to merge results
let mut i = 0;
for bucket in buckets.iter() {
for &num in bucket.iter() {
nums[i] = num;
i += 1;
}
}
}
/* Bucket sort */
void bucketSort(float nums[], int n) {
int k = n / 2; // Initialize k = n/2 buckets
int *sizes = malloc(k * sizeof(int)); // Record each bucket's size
float **buckets = malloc(k * sizeof(float *)); // Array of dynamic arrays (buckets)
// Pre-allocate sufficient space for each bucket
for (int i = 0; i < k; ++i) {
buckets[i] = (float *)malloc(n * sizeof(float));
sizes[i] = 0;
}
// 1. Distribute array elements into various buckets
for (int i = 0; i < n; ++i) {
int idx = (int)(nums[i] * k);
buckets[idx][sizes[idx]++] = nums[i];
}
// 2. Sort each bucket
for (int i = 0; i < k; ++i) {
qsort(buckets[i], sizes[i], sizeof(float), compare);
}
// 3. Merge sorted buckets
int idx = 0;
for (int i = 0; i < k; ++i) {
for (int j = 0; j < sizes[i]; ++j) {
nums[idx++] = buckets[i][j];
}
// Free memory
free(buckets[i]);
}
}
/* Bucket sort */
fun bucketSort(nums: FloatArray) {
// Initialize k = n/2 buckets, expected to allocate 2 elements per bucket
val k = nums.size / 2
val buckets = mutableListOf<MutableList<Float>>()
for (i in 0..<k) {
buckets.add(mutableListOf())
}
// 1. Distribute array elements into various buckets
for (num in nums) {
// Input data range is [0, 1), use num * k to map to index range [0, k-1]
val i = (num * k).toInt()
// Add num to bucket i
buckets[i].add(num)
}
// 2. Sort each bucket
for (bucket in buckets) {
// Use built-in sorting function, can also replace with other sorting algorithms
bucket.sort()
}
// 3. Traverse buckets to merge results
var i = 0
for (bucket in buckets) {
for (num in bucket) {
nums[i++] = num
}
}
}
### Bucket sort ###
def bucket_sort(nums)
# Initialize k = n/2 buckets, expected to allocate 2 elements per bucket
k = nums.length / 2
buckets = Array.new(k) { [] }
# 1. Distribute array elements into various buckets
nums.each do |num|
# Input data range is [0, 1), use num * k to map to index range [0, k-1]
i = (num * k).to_i
# Add num to bucket i
buckets[i] << num
end
# 2. Sort each bucket
buckets.each do |bucket|
# Use built-in sorting function, can also replace with other sorting algorithms
bucket.sort!
end
# 3. Traverse buckets to merge results
i = 0
buckets.each do |bucket|
bucket.each do |num|
nums[i] = num
i += 1
end
end
end
11.8.2 Algorithm Characteristics¶
Bucket sort is suitable for processing very large datasets. For example, suppose the input contains 1 million elements, and limited memory prevents the system from loading all of them at once. In that case, the data can be divided into 1000 buckets, each bucket can be sorted separately, and the results can then be merged.
- Time complexity is \(O(n + k)\): Assuming the elements are evenly distributed across the buckets, each bucket contains \(\frac{n}{k}\) elements. If sorting a single bucket takes \(O(\frac{n}{k} \log\frac{n}{k})\) time, then sorting all buckets takes \(O(n \log\frac{n}{k})\) time. When the number of buckets \(k\) is relatively large, the time complexity approaches \(O(n)\). Merging the results requires traversing all buckets and elements, which takes \(O(n + k)\) time. In the worst case, all data is placed into a single bucket, and sorting that bucket takes \(O(n^2)\) time.
- Space complexity is \(O(n + k)\), and bucket sort is not in-place: It requires extra space for \(k\) buckets and a total of \(n\) elements.
- Whether bucket sort is stable depends on whether the algorithm for sorting elements within buckets is stable.
11.8.3 How to Achieve Even Distribution¶
In theory, bucket sort can achieve \(O(n)\) time complexity. The key is to distribute the elements evenly across the buckets, because real-world data is often not uniformly distributed. For example, suppose we want to divide all products on Taobao evenly into 10 buckets by price range, but the price distribution is uneven: there are many products priced below 100 yuan and very few priced above 1000 yuan. If the price range is divided evenly into 10 intervals, the numbers of products in the buckets will differ greatly.
To achieve a more even distribution, we can first choose a rough boundary and partition the data into 3 buckets. After that, buckets containing more products can be further divided into 3 buckets until the numbers of elements in all buckets are roughly equal.
As shown in Figure 11-14, this method essentially builds a recursion tree whose goal is to make the leaf nodes as balanced as possible. Of course, the data does not have to be split into 3 buckets in every round; the specific partitioning strategy can be chosen flexibly based on the characteristics of the data.
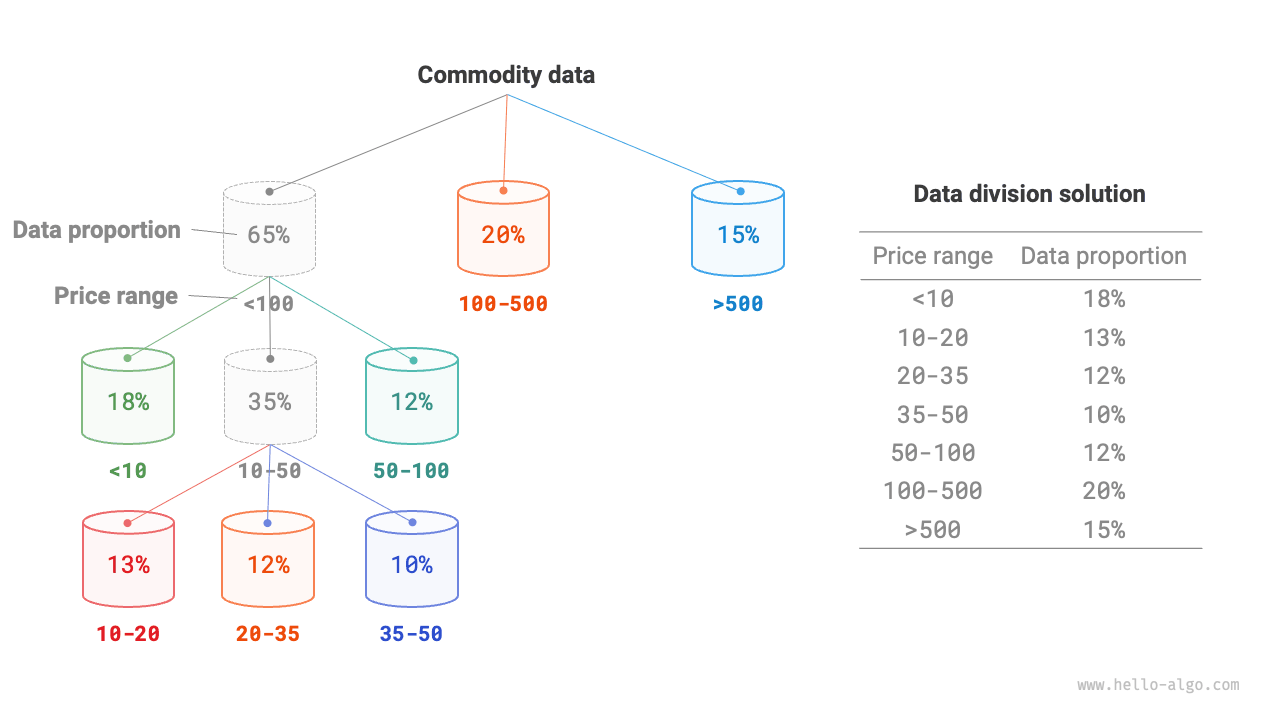
Figure 11-14 Recursively dividing buckets
If we know the probability distribution of product prices in advance, we can set the price boundaries for each bucket according to that distribution. Notably, the data distribution does not need to be measured exactly; it can also be approximated with a probability model chosen to fit the characteristics of the data.
As shown in Figure 11-15, we assume that product prices follow a normal distribution, which allows us to reasonably set price intervals to evenly distribute products to each bucket.
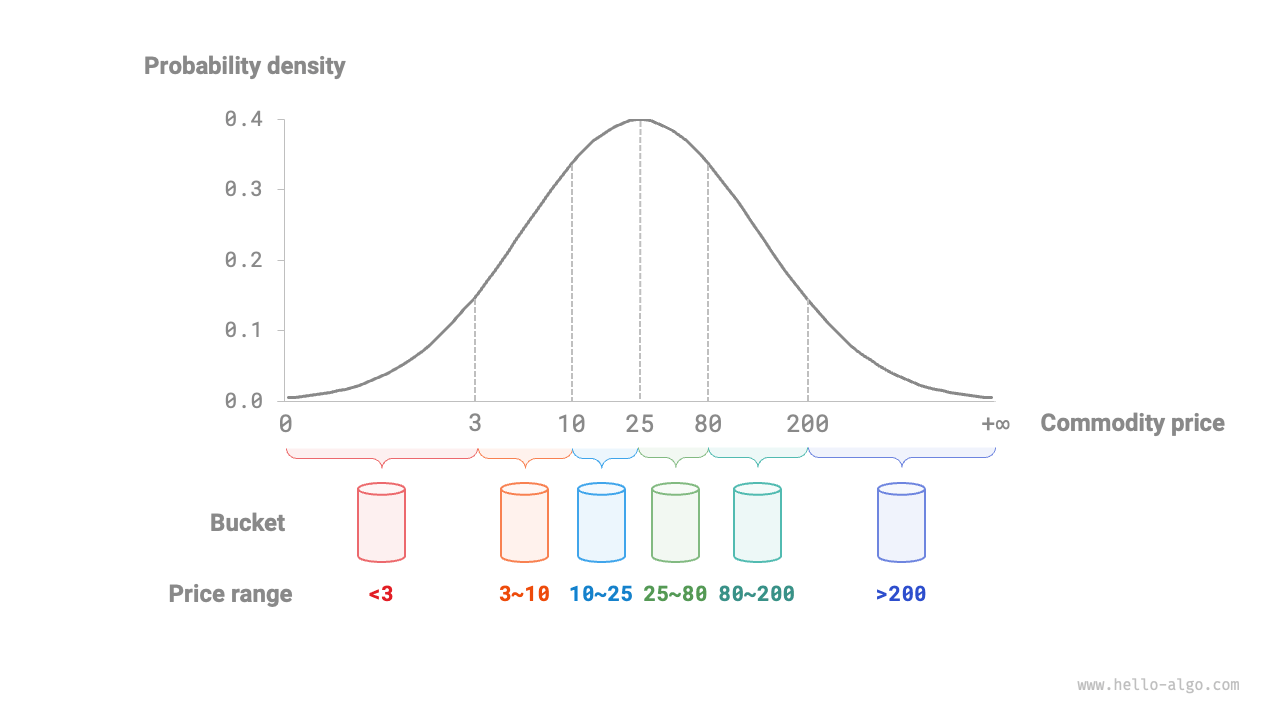
Figure 11-15 Dividing buckets based on probability distribution