6.2 Hash Collision¶
The previous section mentioned that, in most cases, the input space of a hash function is much larger than the output space, so theoretically, hash collisions are inevitable. For example, if the input space is all integers and the output space is the array capacity size, then multiple integers will inevitably be mapped to the same bucket index.
Hash collisions can lead to incorrect query results, severely impacting the usability of the hash table. To address this issue, whenever a hash collision occurs, we can perform hash table expansion until the collision disappears. This approach is simple, straightforward, and effective, but it is very inefficient because hash table expansion involves a large amount of data migration and hash value recalculation. To improve efficiency, we can adopt the following strategies:
- Improve the hash table data structure so that the hash table can function normally when hash collisions occur.
- Only expand when necessary, that is, only when hash collisions are severe.
The main approaches to improving a hash table's structure are separate chaining and open addressing.
6.2.1 Separate Chaining¶
In the original hash table, each bucket can store only one key-value pair. Separate chaining replaces the single element in each bucket with a linked list, treating each key-value pair as a node and storing all colliding key-value pairs in the same list. Figure 6-5 shows an example of a separate chaining hash table.
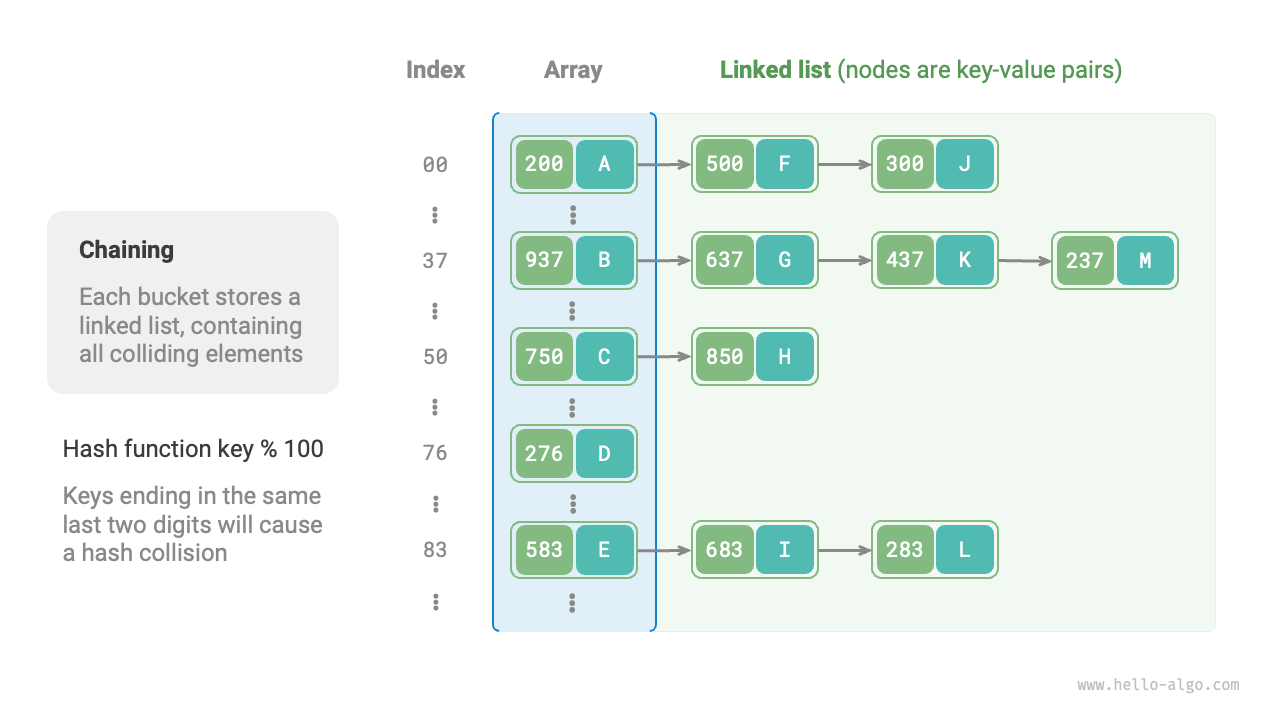
Figure 6-5 Separate chaining hash table
In a hash table implemented with separate chaining, the basic operations work as follows:
- Querying elements: Input
key, compute the bucket index using the hash function, access the head of the corresponding linked list, and traverse the list while comparing keys until the target key-value pair is found. - Adding elements: First use the hash function to locate the corresponding linked list, then insert the node (key-value pair) into the list.
- Deleting elements: Use the hash function to locate the corresponding linked list, then traverse it to find and delete the target node.
Separate chaining has the following limitations:
- Increased Space Usage: The linked list contains node pointers, which consume more memory space than arrays.
- Reduced Query Efficiency: This is because linear traversal of the linked list is required to find the corresponding element.
The code below provides a simple implementation of a separate chaining hash table, with two things to note:
- Lists (dynamic arrays) are used instead of linked lists to simplify the code. In this setup, the hash table (array) contains multiple buckets, each of which is a list.
- This implementation includes a hash table expansion method. When the load factor exceeds \(\frac{2}{3}\), we expand the hash table to \(2\) times its original size.
class HashMapChaining:
"""Hash table with separate chaining"""
def __init__(self):
"""Constructor"""
self.size = 0 # Number of key-value pairs
self.capacity = 4 # Hash table capacity
self.load_thres = 2.0 / 3.0 # Load factor threshold for triggering expansion
self.extend_ratio = 2 # Expansion multiplier
self.buckets = [[] for _ in range(self.capacity)] # Bucket array
def hash_func(self, key: int) -> int:
"""Hash function"""
return key % self.capacity
def load_factor(self) -> float:
"""Load factor"""
return self.size / self.capacity
def get(self, key: int) -> str | None:
"""Query operation"""
index = self.hash_func(key)
bucket = self.buckets[index]
# Traverse bucket, if key is found, return corresponding val
for pair in bucket:
if pair.key == key:
return pair.val
# If key is not found, return None
return None
def put(self, key: int, val: str):
"""Add operation"""
# When load factor exceeds threshold, perform expansion
if self.load_factor() > self.load_thres:
self.extend()
index = self.hash_func(key)
bucket = self.buckets[index]
# Traverse bucket, if specified key is encountered, update corresponding val and return
for pair in bucket:
if pair.key == key:
pair.val = val
return
# If key does not exist, append key-value pair to the end
pair = Pair(key, val)
bucket.append(pair)
self.size += 1
def remove(self, key: int):
"""Remove operation"""
index = self.hash_func(key)
bucket = self.buckets[index]
# Traverse bucket and remove key-value pair from it
for pair in bucket:
if pair.key == key:
bucket.remove(pair)
self.size -= 1
break
def extend(self):
"""Expand hash table"""
# Temporarily store the original hash table
buckets = self.buckets
# Initialize expanded new hash table
self.capacity *= self.extend_ratio
self.buckets = [[] for _ in range(self.capacity)]
self.size = 0
# Move key-value pairs from original hash table to new hash table
for bucket in buckets:
for pair in bucket:
self.put(pair.key, pair.val)
def print(self):
"""Print hash table"""
for bucket in self.buckets:
res = []
for pair in bucket:
res.append(str(pair.key) + " -> " + pair.val)
print(res)
/* Hash table with separate chaining */
class HashMapChaining {
private:
int size; // Number of key-value pairs
int capacity; // Hash table capacity
double loadThres; // Load factor threshold for triggering expansion
int extendRatio; // Expansion multiplier
vector<vector<Pair *>> buckets; // Bucket array
public:
/* Constructor */
HashMapChaining() : size(0), capacity(4), loadThres(2.0 / 3.0), extendRatio(2) {
buckets.resize(capacity);
}
/* Destructor */
~HashMapChaining() {
for (auto &bucket : buckets) {
for (Pair *pair : bucket) {
// Free memory
delete pair;
}
}
}
/* Hash function */
int hashFunc(int key) {
return key % capacity;
}
/* Load factor */
double loadFactor() {
return (double)size / (double)capacity;
}
/* Query operation */
string get(int key) {
int index = hashFunc(key);
// Traverse bucket, if key is found, return corresponding val
for (Pair *pair : buckets[index]) {
if (pair->key == key) {
return pair->val;
}
}
// Return empty string if key not found
return "";
}
/* Add operation */
void put(int key, string val) {
// When load factor exceeds threshold, perform expansion
if (loadFactor() > loadThres) {
extend();
}
int index = hashFunc(key);
// Traverse bucket, if specified key is encountered, update corresponding val and return
for (Pair *pair : buckets[index]) {
if (pair->key == key) {
pair->val = val;
return;
}
}
// If key does not exist, append key-value pair to the end
buckets[index].push_back(new Pair(key, val));
size++;
}
/* Remove operation */
void remove(int key) {
int index = hashFunc(key);
auto &bucket = buckets[index];
// Traverse bucket and remove key-value pair from it
for (int i = 0; i < bucket.size(); i++) {
if (bucket[i]->key == key) {
Pair *tmp = bucket[i];
bucket.erase(bucket.begin() + i); // Remove key-value pair from it
delete tmp; // Free memory
size--;
return;
}
}
}
/* Expand hash table */
void extend() {
// Temporarily store the original hash table
vector<vector<Pair *>> bucketsTmp = buckets;
// Initialize expanded new hash table
capacity *= extendRatio;
buckets.clear();
buckets.resize(capacity);
size = 0;
// Move key-value pairs from original hash table to new hash table
for (auto &bucket : bucketsTmp) {
for (Pair *pair : bucket) {
put(pair->key, pair->val);
// Free memory
delete pair;
}
}
}
/* Print hash table */
void print() {
for (auto &bucket : buckets) {
cout << "[";
for (Pair *pair : bucket) {
cout << pair->key << " -> " << pair->val << ", ";
}
cout << "]\n";
}
}
};
/* Hash table with separate chaining */
class HashMapChaining {
int size; // Number of key-value pairs
int capacity; // Hash table capacity
double loadThres; // Load factor threshold for triggering expansion
int extendRatio; // Expansion multiplier
List<List<Pair>> buckets; // Bucket array
/* Constructor */
public HashMapChaining() {
size = 0;
capacity = 4;
loadThres = 2.0 / 3.0;
extendRatio = 2;
buckets = new ArrayList<>(capacity);
for (int i = 0; i < capacity; i++) {
buckets.add(new ArrayList<>());
}
}
/* Hash function */
int hashFunc(int key) {
return key % capacity;
}
/* Load factor */
double loadFactor() {
return (double) size / capacity;
}
/* Query operation */
String get(int key) {
int index = hashFunc(key);
List<Pair> bucket = buckets.get(index);
// Traverse bucket, if key is found, return corresponding val
for (Pair pair : bucket) {
if (pair.key == key) {
return pair.val;
}
}
// If key is not found, return null
return null;
}
/* Add operation */
void put(int key, String val) {
// When load factor exceeds threshold, perform expansion
if (loadFactor() > loadThres) {
extend();
}
int index = hashFunc(key);
List<Pair> bucket = buckets.get(index);
// Traverse bucket, if specified key is encountered, update corresponding val and return
for (Pair pair : bucket) {
if (pair.key == key) {
pair.val = val;
return;
}
}
// If key does not exist, append key-value pair to the end
Pair pair = new Pair(key, val);
bucket.add(pair);
size++;
}
/* Remove operation */
void remove(int key) {
int index = hashFunc(key);
List<Pair> bucket = buckets.get(index);
// Traverse bucket and remove key-value pair from it
for (Pair pair : bucket) {
if (pair.key == key) {
bucket.remove(pair);
size--;
break;
}
}
}
/* Expand hash table */
void extend() {
// Temporarily store the original hash table
List<List<Pair>> bucketsTmp = buckets;
// Initialize expanded new hash table
capacity *= extendRatio;
buckets = new ArrayList<>(capacity);
for (int i = 0; i < capacity; i++) {
buckets.add(new ArrayList<>());
}
size = 0;
// Move key-value pairs from original hash table to new hash table
for (List<Pair> bucket : bucketsTmp) {
for (Pair pair : bucket) {
put(pair.key, pair.val);
}
}
}
/* Print hash table */
void print() {
for (List<Pair> bucket : buckets) {
List<String> res = new ArrayList<>();
for (Pair pair : bucket) {
res.add(pair.key + " -> " + pair.val);
}
System.out.println(res);
}
}
}
/* Hash table with separate chaining */
class HashMapChaining {
int size; // Number of key-value pairs
int capacity; // Hash table capacity
double loadThres; // Load factor threshold for triggering expansion
int extendRatio; // Expansion multiplier
List<List<Pair>> buckets; // Bucket array
/* Constructor */
public HashMapChaining() {
size = 0;
capacity = 4;
loadThres = 2.0 / 3.0;
extendRatio = 2;
buckets = new List<List<Pair>>(capacity);
for (int i = 0; i < capacity; i++) {
buckets.Add([]);
}
}
/* Hash function */
int HashFunc(int key) {
return key % capacity;
}
/* Load factor */
double LoadFactor() {
return (double)size / capacity;
}
/* Query operation */
public string? Get(int key) {
int index = HashFunc(key);
// Traverse bucket, if key is found, return corresponding val
foreach (Pair pair in buckets[index]) {
if (pair.key == key) {
return pair.val;
}
}
// If key is not found, return null
return null;
}
/* Add operation */
public void Put(int key, string val) {
// When load factor exceeds threshold, perform expansion
if (LoadFactor() > loadThres) {
Extend();
}
int index = HashFunc(key);
// Traverse bucket, if specified key is encountered, update corresponding val and return
foreach (Pair pair in buckets[index]) {
if (pair.key == key) {
pair.val = val;
return;
}
}
// If key does not exist, append key-value pair to the end
buckets[index].Add(new Pair(key, val));
size++;
}
/* Remove operation */
public void Remove(int key) {
int index = HashFunc(key);
// Traverse bucket and remove key-value pair from it
foreach (Pair pair in buckets[index].ToList()) {
if (pair.key == key) {
buckets[index].Remove(pair);
size--;
break;
}
}
}
/* Expand hash table */
void Extend() {
// Temporarily store the original hash table
List<List<Pair>> bucketsTmp = buckets;
// Initialize expanded new hash table
capacity *= extendRatio;
buckets = new List<List<Pair>>(capacity);
for (int i = 0; i < capacity; i++) {
buckets.Add([]);
}
size = 0;
// Move key-value pairs from original hash table to new hash table
foreach (List<Pair> bucket in bucketsTmp) {
foreach (Pair pair in bucket) {
Put(pair.key, pair.val);
}
}
}
/* Print hash table */
public void Print() {
foreach (List<Pair> bucket in buckets) {
List<string> res = [];
foreach (Pair pair in bucket) {
res.Add(pair.key + " -> " + pair.val);
}
foreach (string kv in res) {
Console.WriteLine(kv);
}
}
}
}
/* Hash table with separate chaining */
type hashMapChaining struct {
size int // Number of key-value pairs
capacity int // Hash table capacity
loadThres float64 // Load factor threshold for triggering expansion
extendRatio int // Expansion multiplier
buckets [][]pair // Bucket array
}
/* Constructor */
func newHashMapChaining() *hashMapChaining {
buckets := make([][]pair, 4)
for i := 0; i < 4; i++ {
buckets[i] = make([]pair, 0)
}
return &hashMapChaining{
size: 0,
capacity: 4,
loadThres: 2.0 / 3.0,
extendRatio: 2,
buckets: buckets,
}
}
/* Hash function */
func (m *hashMapChaining) hashFunc(key int) int {
return key % m.capacity
}
/* Load factor */
func (m *hashMapChaining) loadFactor() float64 {
return float64(m.size) / float64(m.capacity)
}
/* Query operation */
func (m *hashMapChaining) get(key int) string {
idx := m.hashFunc(key)
bucket := m.buckets[idx]
// Traverse bucket, if key is found, return corresponding val
for _, p := range bucket {
if p.key == key {
return p.val
}
}
// Return empty string if key not found
return ""
}
/* Add operation */
func (m *hashMapChaining) put(key int, val string) {
// When load factor exceeds threshold, perform expansion
if m.loadFactor() > m.loadThres {
m.extend()
}
idx := m.hashFunc(key)
// Traverse bucket, if specified key is encountered, update corresponding val and return
for i := range m.buckets[idx] {
if m.buckets[idx][i].key == key {
m.buckets[idx][i].val = val
return
}
}
// If key does not exist, append key-value pair to the end
p := pair{
key: key,
val: val,
}
m.buckets[idx] = append(m.buckets[idx], p)
m.size += 1
}
/* Remove operation */
func (m *hashMapChaining) remove(key int) {
idx := m.hashFunc(key)
// Traverse bucket and remove key-value pair from it
for i, p := range m.buckets[idx] {
if p.key == key {
// Slice deletion
m.buckets[idx] = append(m.buckets[idx][:i], m.buckets[idx][i+1:]...)
m.size -= 1
break
}
}
}
/* Expand hash table */
func (m *hashMapChaining) extend() {
// Temporarily store the original hash table
tmpBuckets := make([][]pair, len(m.buckets))
for i := 0; i < len(m.buckets); i++ {
tmpBuckets[i] = make([]pair, len(m.buckets[i]))
copy(tmpBuckets[i], m.buckets[i])
}
// Initialize expanded new hash table
m.capacity *= m.extendRatio
m.buckets = make([][]pair, m.capacity)
for i := 0; i < m.capacity; i++ {
m.buckets[i] = make([]pair, 0)
}
m.size = 0
// Move key-value pairs from original hash table to new hash table
for _, bucket := range tmpBuckets {
for _, p := range bucket {
m.put(p.key, p.val)
}
}
}
/* Print hash table */
func (m *hashMapChaining) print() {
var builder strings.Builder
for _, bucket := range m.buckets {
builder.WriteString("[")
for _, p := range bucket {
builder.WriteString(strconv.Itoa(p.key) + " -> " + p.val + " ")
}
builder.WriteString("]")
fmt.Println(builder.String())
builder.Reset()
}
}
/* Hash table with separate chaining */
class HashMapChaining {
var size: Int // Number of key-value pairs
var capacity: Int // Hash table capacity
var loadThres: Double // Load factor threshold for triggering expansion
var extendRatio: Int // Expansion multiplier
var buckets: [[Pair]] // Bucket array
/* Constructor */
init() {
size = 0
capacity = 4
loadThres = 2.0 / 3.0
extendRatio = 2
buckets = Array(repeating: [], count: capacity)
}
/* Hash function */
func hashFunc(key: Int) -> Int {
key % capacity
}
/* Load factor */
func loadFactor() -> Double {
Double(size) / Double(capacity)
}
/* Query operation */
func get(key: Int) -> String? {
let index = hashFunc(key: key)
let bucket = buckets[index]
// Traverse bucket, if key is found, return corresponding val
for pair in bucket {
if pair.key == key {
return pair.val
}
}
// Return nil if key not found
return nil
}
/* Add operation */
func put(key: Int, val: String) {
// When load factor exceeds threshold, perform expansion
if loadFactor() > loadThres {
extend()
}
let index = hashFunc(key: key)
let bucket = buckets[index]
// Traverse bucket, if specified key is encountered, update corresponding val and return
for pair in bucket {
if pair.key == key {
pair.val = val
return
}
}
// If key does not exist, append key-value pair to the end
let pair = Pair(key: key, val: val)
buckets[index].append(pair)
size += 1
}
/* Remove operation */
func remove(key: Int) {
let index = hashFunc(key: key)
let bucket = buckets[index]
// Traverse bucket and remove key-value pair from it
for (pairIndex, pair) in bucket.enumerated() {
if pair.key == key {
buckets[index].remove(at: pairIndex)
size -= 1
break
}
}
}
/* Expand hash table */
func extend() {
// Temporarily store the original hash table
let bucketsTmp = buckets
// Initialize expanded new hash table
capacity *= extendRatio
buckets = Array(repeating: [], count: capacity)
size = 0
// Move key-value pairs from original hash table to new hash table
for bucket in bucketsTmp {
for pair in bucket {
put(key: pair.key, val: pair.val)
}
}
}
/* Print hash table */
func print() {
for bucket in buckets {
let res = bucket.map { "\($0.key) -> \($0.val)" }
Swift.print(res)
}
}
}
/* Hash table with separate chaining */
class HashMapChaining {
#size; // Number of key-value pairs
#capacity; // Hash table capacity
#loadThres; // Load factor threshold for triggering expansion
#extendRatio; // Expansion multiplier
#buckets; // Bucket array
/* Constructor */
constructor() {
this.#size = 0;
this.#capacity = 4;
this.#loadThres = 2.0 / 3.0;
this.#extendRatio = 2;
this.#buckets = new Array(this.#capacity).fill(null).map((x) => []);
}
/* Hash function */
#hashFunc(key) {
return key % this.#capacity;
}
/* Load factor */
#loadFactor() {
return this.#size / this.#capacity;
}
/* Query operation */
get(key) {
const index = this.#hashFunc(key);
const bucket = this.#buckets[index];
// Traverse bucket, if key is found, return corresponding val
for (const pair of bucket) {
if (pair.key === key) {
return pair.val;
}
}
// If key is not found, return null
return null;
}
/* Add operation */
put(key, val) {
// When load factor exceeds threshold, perform expansion
if (this.#loadFactor() > this.#loadThres) {
this.#extend();
}
const index = this.#hashFunc(key);
const bucket = this.#buckets[index];
// Traverse bucket, if specified key is encountered, update corresponding val and return
for (const pair of bucket) {
if (pair.key === key) {
pair.val = val;
return;
}
}
// If key does not exist, append key-value pair to the end
const pair = new Pair(key, val);
bucket.push(pair);
this.#size++;
}
/* Remove operation */
remove(key) {
const index = this.#hashFunc(key);
let bucket = this.#buckets[index];
// Traverse bucket and remove key-value pair from it
for (let i = 0; i < bucket.length; i++) {
if (bucket[i].key === key) {
bucket.splice(i, 1);
this.#size--;
break;
}
}
}
/* Expand hash table */
#extend() {
// Temporarily store the original hash table
const bucketsTmp = this.#buckets;
// Initialize expanded new hash table
this.#capacity *= this.#extendRatio;
this.#buckets = new Array(this.#capacity).fill(null).map((x) => []);
this.#size = 0;
// Move key-value pairs from original hash table to new hash table
for (const bucket of bucketsTmp) {
for (const pair of bucket) {
this.put(pair.key, pair.val);
}
}
}
/* Print hash table */
print() {
for (const bucket of this.#buckets) {
let res = [];
for (const pair of bucket) {
res.push(pair.key + ' -> ' + pair.val);
}
console.log(res);
}
}
}
/* Hash table with separate chaining */
class HashMapChaining {
#size: number; // Number of key-value pairs
#capacity: number; // Hash table capacity
#loadThres: number; // Load factor threshold for triggering expansion
#extendRatio: number; // Expansion multiplier
#buckets: Pair[][]; // Bucket array
/* Constructor */
constructor() {
this.#size = 0;
this.#capacity = 4;
this.#loadThres = 2.0 / 3.0;
this.#extendRatio = 2;
this.#buckets = new Array(this.#capacity).fill(null).map((x) => []);
}
/* Hash function */
#hashFunc(key: number): number {
return key % this.#capacity;
}
/* Load factor */
#loadFactor(): number {
return this.#size / this.#capacity;
}
/* Query operation */
get(key: number): string | null {
const index = this.#hashFunc(key);
const bucket = this.#buckets[index];
// Traverse bucket, if key is found, return corresponding val
for (const pair of bucket) {
if (pair.key === key) {
return pair.val;
}
}
// If key is not found, return null
return null;
}
/* Add operation */
put(key: number, val: string): void {
// When load factor exceeds threshold, perform expansion
if (this.#loadFactor() > this.#loadThres) {
this.#extend();
}
const index = this.#hashFunc(key);
const bucket = this.#buckets[index];
// Traverse bucket, if specified key is encountered, update corresponding val and return
for (const pair of bucket) {
if (pair.key === key) {
pair.val = val;
return;
}
}
// If key does not exist, append key-value pair to the end
const pair = new Pair(key, val);
bucket.push(pair);
this.#size++;
}
/* Remove operation */
remove(key: number): void {
const index = this.#hashFunc(key);
let bucket = this.#buckets[index];
// Traverse bucket and remove key-value pair from it
for (let i = 0; i < bucket.length; i++) {
if (bucket[i].key === key) {
bucket.splice(i, 1);
this.#size--;
break;
}
}
}
/* Expand hash table */
#extend(): void {
// Temporarily store the original hash table
const bucketsTmp = this.#buckets;
// Initialize expanded new hash table
this.#capacity *= this.#extendRatio;
this.#buckets = new Array(this.#capacity).fill(null).map((x) => []);
this.#size = 0;
// Move key-value pairs from original hash table to new hash table
for (const bucket of bucketsTmp) {
for (const pair of bucket) {
this.put(pair.key, pair.val);
}
}
}
/* Print hash table */
print(): void {
for (const bucket of this.#buckets) {
let res = [];
for (const pair of bucket) {
res.push(pair.key + ' -> ' + pair.val);
}
console.log(res);
}
}
}
/* Hash table with separate chaining */
class HashMapChaining {
late int size; // Number of key-value pairs
late int capacity; // Hash table capacity
late double loadThres; // Load factor threshold for triggering expansion
late int extendRatio; // Expansion multiplier
late List<List<Pair>> buckets; // Bucket array
/* Constructor */
HashMapChaining() {
size = 0;
capacity = 4;
loadThres = 2.0 / 3.0;
extendRatio = 2;
buckets = List.generate(capacity, (_) => []);
}
/* Hash function */
int hashFunc(int key) {
return key % capacity;
}
/* Load factor */
double loadFactor() {
return size / capacity;
}
/* Query operation */
String? get(int key) {
int index = hashFunc(key);
List<Pair> bucket = buckets[index];
// Traverse bucket, if key is found, return corresponding val
for (Pair pair in bucket) {
if (pair.key == key) {
return pair.val;
}
}
// If key is not found, return null
return null;
}
/* Add operation */
void put(int key, String val) {
// When load factor exceeds threshold, perform expansion
if (loadFactor() > loadThres) {
extend();
}
int index = hashFunc(key);
List<Pair> bucket = buckets[index];
// Traverse bucket, if specified key is encountered, update corresponding val and return
for (Pair pair in bucket) {
if (pair.key == key) {
pair.val = val;
return;
}
}
// If key does not exist, append key-value pair to the end
Pair pair = Pair(key, val);
bucket.add(pair);
size++;
}
/* Remove operation */
void remove(int key) {
int index = hashFunc(key);
List<Pair> bucket = buckets[index];
// Traverse bucket and remove key-value pair from it
for (Pair pair in bucket) {
if (pair.key == key) {
bucket.remove(pair);
size--;
break;
}
}
}
/* Expand hash table */
void extend() {
// Temporarily store the original hash table
List<List<Pair>> bucketsTmp = buckets;
// Initialize expanded new hash table
capacity *= extendRatio;
buckets = List.generate(capacity, (_) => []);
size = 0;
// Move key-value pairs from original hash table to new hash table
for (List<Pair> bucket in bucketsTmp) {
for (Pair pair in bucket) {
put(pair.key, pair.val);
}
}
}
/* Print hash table */
void printHashMap() {
for (List<Pair> bucket in buckets) {
List<String> res = [];
for (Pair pair in bucket) {
res.add("${pair.key} -> ${pair.val}");
}
print(res);
}
}
}
/* Hash table with separate chaining */
struct HashMapChaining {
size: usize,
capacity: usize,
load_thres: f32,
extend_ratio: usize,
buckets: Vec<Vec<Pair>>,
}
impl HashMapChaining {
/* Constructor */
fn new() -> Self {
Self {
size: 0,
capacity: 4,
load_thres: 2.0 / 3.0,
extend_ratio: 2,
buckets: vec![vec![]; 4],
}
}
/* Hash function */
fn hash_func(&self, key: i32) -> usize {
key as usize % self.capacity
}
/* Load factor */
fn load_factor(&self) -> f32 {
self.size as f32 / self.capacity as f32
}
/* Remove operation */
fn remove(&mut self, key: i32) -> Option<String> {
let index = self.hash_func(key);
// Traverse bucket and remove key-value pair from it
for (i, p) in self.buckets[index].iter_mut().enumerate() {
if p.key == key {
let pair = self.buckets[index].remove(i);
self.size -= 1;
return Some(pair.val);
}
}
// If key is not found, return None
None
}
/* Expand hash table */
fn extend(&mut self) {
// Temporarily store the original hash table
let buckets_tmp = std::mem::take(&mut self.buckets);
// Initialize expanded new hash table
self.capacity *= self.extend_ratio;
self.buckets = vec![Vec::new(); self.capacity as usize];
self.size = 0;
// Move key-value pairs from original hash table to new hash table
for bucket in buckets_tmp {
for pair in bucket {
self.put(pair.key, pair.val);
}
}
}
/* Print hash table */
fn print(&self) {
for bucket in &self.buckets {
let mut res = Vec::new();
for pair in bucket {
res.push(format!("{} -> {}", pair.key, pair.val));
}
println!("{:?}", res);
}
}
/* Add operation */
fn put(&mut self, key: i32, val: String) {
// When load factor exceeds threshold, perform expansion
if self.load_factor() > self.load_thres {
self.extend();
}
let index = self.hash_func(key);
// Traverse bucket, if specified key is encountered, update corresponding val and return
for pair in self.buckets[index].iter_mut() {
if pair.key == key {
pair.val = val;
return;
}
}
// If key does not exist, append key-value pair to the end
let pair = Pair { key, val };
self.buckets[index].push(pair);
self.size += 1;
}
/* Query operation */
fn get(&self, key: i32) -> Option<&str> {
let index = self.hash_func(key);
// Traverse bucket, if key is found, return corresponding val
for pair in self.buckets[index].iter() {
if pair.key == key {
return Some(&pair.val);
}
}
// If key is not found, return None
None
}
}
/* Linked list node */
typedef struct Node {
Pair *pair;
struct Node *next;
} Node;
/* Hash table with separate chaining */
typedef struct {
int size; // Number of key-value pairs
int capacity; // Hash table capacity
double loadThres; // Load factor threshold for triggering expansion
int extendRatio; // Expansion multiplier
Node **buckets; // Bucket array
} HashMapChaining;
/* Constructor */
HashMapChaining *newHashMapChaining() {
HashMapChaining *hashMap = (HashMapChaining *)malloc(sizeof(HashMapChaining));
hashMap->size = 0;
hashMap->capacity = 4;
hashMap->loadThres = 2.0 / 3.0;
hashMap->extendRatio = 2;
hashMap->buckets = (Node **)malloc(hashMap->capacity * sizeof(Node *));
for (int i = 0; i < hashMap->capacity; i++) {
hashMap->buckets[i] = NULL;
}
return hashMap;
}
/* Destructor */
void delHashMapChaining(HashMapChaining *hashMap) {
for (int i = 0; i < hashMap->capacity; i++) {
Node *cur = hashMap->buckets[i];
while (cur) {
Node *tmp = cur;
cur = cur->next;
free(tmp->pair);
free(tmp);
}
}
free(hashMap->buckets);
free(hashMap);
}
/* Hash function */
int hashFunc(HashMapChaining *hashMap, int key) {
return key % hashMap->capacity;
}
/* Load factor */
double loadFactor(HashMapChaining *hashMap) {
return (double)hashMap->size / (double)hashMap->capacity;
}
/* Query operation */
char *get(HashMapChaining *hashMap, int key) {
int index = hashFunc(hashMap, key);
// Traverse bucket, if key is found, return corresponding val
Node *cur = hashMap->buckets[index];
while (cur) {
if (cur->pair->key == key) {
return cur->pair->val;
}
cur = cur->next;
}
return ""; // Return empty string if key not found
}
/* Add operation */
void put(HashMapChaining *hashMap, int key, const char *val) {
// When load factor exceeds threshold, perform expansion
if (loadFactor(hashMap) > hashMap->loadThres) {
extend(hashMap);
}
int index = hashFunc(hashMap, key);
// Traverse bucket, if specified key is encountered, update corresponding val and return
Node *cur = hashMap->buckets[index];
while (cur) {
if (cur->pair->key == key) {
strcpy(cur->pair->val, val); // If specified key is found, update corresponding val and return
return;
}
cur = cur->next;
}
// If key not found, add key-value pair to list head
Pair *newPair = (Pair *)malloc(sizeof(Pair));
newPair->key = key;
strcpy(newPair->val, val);
Node *newNode = (Node *)malloc(sizeof(Node));
newNode->pair = newPair;
newNode->next = hashMap->buckets[index];
hashMap->buckets[index] = newNode;
hashMap->size++;
}
/* Expand hash table */
void extend(HashMapChaining *hashMap) {
// Temporarily store the original hash table
int oldCapacity = hashMap->capacity;
Node **oldBuckets = hashMap->buckets;
// Initialize expanded new hash table
hashMap->capacity *= hashMap->extendRatio;
hashMap->buckets = (Node **)malloc(hashMap->capacity * sizeof(Node *));
for (int i = 0; i < hashMap->capacity; i++) {
hashMap->buckets[i] = NULL;
}
hashMap->size = 0;
// Move key-value pairs from original hash table to new hash table
for (int i = 0; i < oldCapacity; i++) {
Node *cur = oldBuckets[i];
while (cur) {
put(hashMap, cur->pair->key, cur->pair->val);
Node *temp = cur;
cur = cur->next;
// Free memory
free(temp->pair);
free(temp);
}
}
free(oldBuckets);
}
/* Remove operation */
void removeItem(HashMapChaining *hashMap, int key) {
int index = hashFunc(hashMap, key);
Node *cur = hashMap->buckets[index];
Node *pre = NULL;
while (cur) {
if (cur->pair->key == key) {
// Remove key-value pair from it
if (pre) {
pre->next = cur->next;
} else {
hashMap->buckets[index] = cur->next;
}
// Free memory
free(cur->pair);
free(cur);
hashMap->size--;
return;
}
pre = cur;
cur = cur->next;
}
}
/* Print hash table */
void print(HashMapChaining *hashMap) {
for (int i = 0; i < hashMap->capacity; i++) {
Node *cur = hashMap->buckets[i];
printf("[");
while (cur) {
printf("%d -> %s, ", cur->pair->key, cur->pair->val);
cur = cur->next;
}
printf("]\n");
}
}
/* Hash table with separate chaining */
class HashMapChaining {
var size: Int // Number of key-value pairs
var capacity: Int // Hash table capacity
val loadThres: Double // Load factor threshold for triggering expansion
val extendRatio: Int // Expansion multiplier
var buckets: MutableList<MutableList<Pair>> // Bucket array
/* Constructor */
init {
size = 0
capacity = 4
loadThres = 2.0 / 3.0
extendRatio = 2
buckets = mutableListOf()
for (i in 0..<capacity) {
buckets.add(mutableListOf())
}
}
/* Hash function */
fun hashFunc(key: Int): Int {
return key % capacity
}
/* Load factor */
fun loadFactor(): Double {
return (size / capacity).toDouble()
}
/* Query operation */
fun get(key: Int): String? {
val index = hashFunc(key)
val bucket = buckets[index]
// Traverse bucket, if key is found, return corresponding val
for (pair in bucket) {
if (pair.key == key) return pair._val
}
// If key is not found, return null
return null
}
/* Add operation */
fun put(key: Int, _val: String) {
// When load factor exceeds threshold, perform expansion
if (loadFactor() > loadThres) {
extend()
}
val index = hashFunc(key)
val bucket = buckets[index]
// Traverse bucket, if specified key is encountered, update corresponding val and return
for (pair in bucket) {
if (pair.key == key) {
pair._val = _val
return
}
}
// If key does not exist, append key-value pair to the end
val pair = Pair(key, _val)
bucket.add(pair)
size++
}
/* Remove operation */
fun remove(key: Int) {
val index = hashFunc(key)
val bucket = buckets[index]
// Traverse bucket and remove key-value pair from it
for (pair in bucket) {
if (pair.key == key) {
bucket.remove(pair)
size--
break
}
}
}
/* Expand hash table */
fun extend() {
// Temporarily store the original hash table
val bucketsTmp = buckets
// Initialize expanded new hash table
capacity *= extendRatio
// mutablelist has no fixed size
buckets = mutableListOf()
for (i in 0..<capacity) {
buckets.add(mutableListOf())
}
size = 0
// Move key-value pairs from original hash table to new hash table
for (bucket in bucketsTmp) {
for (pair in bucket) {
put(pair.key, pair._val)
}
}
}
/* Print hash table */
fun print() {
for (bucket in buckets) {
val res = mutableListOf<String>()
for (pair in bucket) {
val k = pair.key
val v = pair._val
res.add("$k -> $v")
}
println(res)
}
}
}
### Hash map with chaining ###
class HashMapChaining
### Constructor ###
def initialize
@size = 0 # Number of key-value pairs
@capacity = 4 # Hash table capacity
@load_thres = 2.0 / 3.0 # Load factor threshold for triggering expansion
@extend_ratio = 2 # Expansion multiplier
@buckets = Array.new(@capacity) { [] } # Bucket array
end
### Hash function ###
def hash_func(key)
key % @capacity
end
### Load factor ###
def load_factor
@size / @capacity
end
### Query operation ###
def get(key)
index = hash_func(key)
bucket = @buckets[index]
# Traverse bucket, if key is found, return corresponding val
for pair in bucket
return pair.val if pair.key == key
end
# Return nil if key not found
nil
end
### Add operation ###
def put(key, val)
# When load factor exceeds threshold, perform expansion
extend if load_factor > @load_thres
index = hash_func(key)
bucket = @buckets[index]
# Traverse bucket, if specified key is encountered, update corresponding val and return
for pair in bucket
if pair.key == key
pair.val = val
return
end
end
# If key does not exist, append key-value pair to the end
pair = Pair.new(key, val)
bucket << pair
@size += 1
end
### Delete operation ###
def remove(key)
index = hash_func(key)
bucket = @buckets[index]
# Traverse bucket and remove key-value pair from it
for pair in bucket
if pair.key == key
bucket.delete(pair)
@size -= 1
break
end
end
end
### Expand hash table ###
def extend
# Temporarily store original hash table
buckets = @buckets
# Initialize expanded new hash table
@capacity *= @extend_ratio
@buckets = Array.new(@capacity) { [] }
@size = 0
# Move key-value pairs from original hash table to new hash table
for bucket in buckets
for pair in bucket
put(pair.key, pair.val)
end
end
end
### Print hash table ###
def print
for bucket in @buckets
res = []
for pair in bucket
res << "#{pair.key} -> #{pair.val}"
end
pp res
end
end
end
It's worth noting that when the linked list becomes very long, the query time \(O(n)\) is poor. In this case, the linked list can be converted into an AVL tree or a red-black tree, reducing the time complexity of lookups to \(O(\log n)\).
6.2.2 Open Addressing¶
Open addressing does not introduce additional data structures. Instead, it handles hash collisions through repeated probing. Common probing strategies include linear probing, quadratic probing, and multiple hashing.
Let's use linear probing as an example to introduce the mechanism of open addressing hash tables.
1. Linear Probing¶
Linear probing uses a fixed step size to probe sequentially, so its operations differ somewhat from those of an ordinary hash table.
- Inserting elements: Compute the bucket index using the hash function. If the bucket is already occupied, continue probing forward from the collision position with a fixed step size (usually \(1\)) until an empty bucket is found, then insert the element there.
- Searching for elements: If a collision occurs, continue probing forward with the same step size until the corresponding element is found and return its
value; if an empty bucket is encountered, the target element is not in the hash table, so returnNone.
Figure 6-6 shows the distribution of key-value pairs in an open-addressing hash table that uses linear probing. Under this hash function, keys with the same last two digits are mapped to the same bucket. Linear probing then places them in that bucket and the subsequent buckets.

Figure 6-6 Distribution of key-value pairs in open addressing (linear probing) hash table
However, linear probing is prone to clustering. Specifically, the longer a contiguous occupied region in the array becomes, the more likely new collisions are to occur within that region. This in turn makes the cluster grow even further, creating a vicious cycle that gradually degrades the efficiency of insertion, deletion, lookup, and update operations.
It's important to note that we cannot directly delete elements from an open-addressing hash table. Deleting an element creates an empty bucket None in the array. During lookup, once linear probing reaches that empty bucket, it stops, which means any elements stored farther along the probe sequence become unreachable. As a result, the program may incorrectly conclude that those elements do not exist, as shown in Figure 6-7.

Figure 6-7 Query issues caused by deletion in open addressing
To solve this problem, we can adopt lazy deletion: instead of directly removing an element from the hash table, use a constant TOMBSTONE to mark the bucket. Under this mechanism, both None and TOMBSTONE denote buckets that can accept key-value pairs. The difference is that when linear probing encounters TOMBSTONE, it must continue probing, because key-value pairs may still exist farther along the sequence.
However, lazy deletion may accelerate hash-table performance degradation. Each deletion leaves behind a marker, and as the number of TOMBSTONE entries grows, search time increases as well, because linear probing may need to skip over multiple tombstones before finding the target element.
To address this, we can record the index of the first TOMBSTONE encountered during linear probing and swap the found target element into that position. The benefit is that each query or insertion can move elements closer to their ideal positions, that is, closer to where probing begins, which improves lookup efficiency.
The code below implements an open addressing (linear probing) hash table with lazy deletion. To make better use of the hash table space, we treat the hash table as a "circular array". When going beyond the end of the array, we return to the beginning and continue traversing.
class HashMapOpenAddressing:
"""Hash table with open addressing"""
def __init__(self):
"""Constructor"""
self.size = 0 # Number of key-value pairs
self.capacity = 4 # Hash table capacity
self.load_thres = 2.0 / 3.0 # Load factor threshold for triggering expansion
self.extend_ratio = 2 # Expansion multiplier
self.buckets: list[Pair | None] = [None] * self.capacity # Bucket array
self.TOMBSTONE = Pair(-1, "-1") # Removal marker
def hash_func(self, key: int) -> int:
"""Hash function"""
return key % self.capacity
def load_factor(self) -> float:
"""Load factor"""
return self.size / self.capacity
def find_bucket(self, key: int) -> int:
"""Search for bucket index corresponding to key"""
index = self.hash_func(key)
first_tombstone = -1
# Linear probing, break when encountering an empty bucket
while self.buckets[index] is not None:
# If key is encountered, return the corresponding bucket index
if self.buckets[index].key == key:
# If a removal marker was encountered before, move the key-value pair to that index
if first_tombstone != -1:
self.buckets[first_tombstone] = self.buckets[index]
self.buckets[index] = self.TOMBSTONE
return first_tombstone # Return the moved bucket index
return index # Return bucket index
# Record the first removal marker encountered
if first_tombstone == -1 and self.buckets[index] is self.TOMBSTONE:
first_tombstone = index
# Calculate bucket index, wrap around to the head if past the tail
index = (index + 1) % self.capacity
# If key does not exist, return the index for insertion
return index if first_tombstone == -1 else first_tombstone
def get(self, key: int) -> str:
"""Query operation"""
# Search for bucket index corresponding to key
index = self.find_bucket(key)
# If key-value pair is found, return corresponding val
if self.buckets[index] not in [None, self.TOMBSTONE]:
return self.buckets[index].val
# If key-value pair does not exist, return None
return None
def put(self, key: int, val: str):
"""Add operation"""
# When load factor exceeds threshold, perform expansion
if self.load_factor() > self.load_thres:
self.extend()
# Search for bucket index corresponding to key
index = self.find_bucket(key)
# If key-value pair is found, overwrite val and return
if self.buckets[index] not in [None, self.TOMBSTONE]:
self.buckets[index].val = val
return
# If key-value pair does not exist, add the key-value pair
self.buckets[index] = Pair(key, val)
self.size += 1
def remove(self, key: int):
"""Remove operation"""
# Search for bucket index corresponding to key
index = self.find_bucket(key)
# If key-value pair is found, overwrite it with removal marker
if self.buckets[index] not in [None, self.TOMBSTONE]:
self.buckets[index] = self.TOMBSTONE
self.size -= 1
def extend(self):
"""Expand hash table"""
# Temporarily store the original hash table
buckets_tmp = self.buckets
# Initialize expanded new hash table
self.capacity *= self.extend_ratio
self.buckets = [None] * self.capacity
self.size = 0
# Move key-value pairs from original hash table to new hash table
for pair in buckets_tmp:
if pair not in [None, self.TOMBSTONE]:
self.put(pair.key, pair.val)
def print(self):
"""Print hash table"""
for pair in self.buckets:
if pair is None:
print("None")
elif pair is self.TOMBSTONE:
print("TOMBSTONE")
else:
print(pair.key, "->", pair.val)
/* Hash table with open addressing */
class HashMapOpenAddressing {
private:
int size; // Number of key-value pairs
int capacity = 4; // Hash table capacity
const double loadThres = 2.0 / 3.0; // Load factor threshold for triggering expansion
const int extendRatio = 2; // Expansion multiplier
vector<Pair *> buckets; // Bucket array
Pair *TOMBSTONE = new Pair(-1, "-1"); // Removal marker
public:
/* Constructor */
HashMapOpenAddressing() : size(0), buckets(capacity, nullptr) {
}
/* Destructor */
~HashMapOpenAddressing() {
for (Pair *pair : buckets) {
if (pair != nullptr && pair != TOMBSTONE) {
delete pair;
}
}
delete TOMBSTONE;
}
/* Hash function */
int hashFunc(int key) {
return key % capacity;
}
/* Load factor */
double loadFactor() {
return (double)size / capacity;
}
/* Search for bucket index corresponding to key */
int findBucket(int key) {
int index = hashFunc(key);
int firstTombstone = -1;
// Linear probing, break when encountering an empty bucket
while (buckets[index] != nullptr) {
// If key is encountered, return the corresponding bucket index
if (buckets[index]->key == key) {
// If a removal marker was encountered before, move the key-value pair to that index
if (firstTombstone != -1) {
buckets[firstTombstone] = buckets[index];
buckets[index] = TOMBSTONE;
return firstTombstone; // Return the moved bucket index
}
return index; // Return bucket index
}
// Record the first removal marker encountered
if (firstTombstone == -1 && buckets[index] == TOMBSTONE) {
firstTombstone = index;
}
// Calculate bucket index, wrap around to the head if past the tail
index = (index + 1) % capacity;
}
// If key does not exist, return the index for insertion
return firstTombstone == -1 ? index : firstTombstone;
}
/* Query operation */
string get(int key) {
// Search for bucket index corresponding to key
int index = findBucket(key);
// If key-value pair is found, return corresponding val
if (buckets[index] != nullptr && buckets[index] != TOMBSTONE) {
return buckets[index]->val;
}
// Return empty string if key-value pair does not exist
return "";
}
/* Add operation */
void put(int key, string val) {
// When load factor exceeds threshold, perform expansion
if (loadFactor() > loadThres) {
extend();
}
// Search for bucket index corresponding to key
int index = findBucket(key);
// If key-value pair is found, overwrite val and return
if (buckets[index] != nullptr && buckets[index] != TOMBSTONE) {
buckets[index]->val = val;
return;
}
// If key-value pair does not exist, add the key-value pair
buckets[index] = new Pair(key, val);
size++;
}
/* Remove operation */
void remove(int key) {
// Search for bucket index corresponding to key
int index = findBucket(key);
// If key-value pair is found, overwrite it with removal marker
if (buckets[index] != nullptr && buckets[index] != TOMBSTONE) {
delete buckets[index];
buckets[index] = TOMBSTONE;
size--;
}
}
/* Expand hash table */
void extend() {
// Temporarily store the original hash table
vector<Pair *> bucketsTmp = buckets;
// Initialize expanded new hash table
capacity *= extendRatio;
buckets = vector<Pair *>(capacity, nullptr);
size = 0;
// Move key-value pairs from original hash table to new hash table
for (Pair *pair : bucketsTmp) {
if (pair != nullptr && pair != TOMBSTONE) {
put(pair->key, pair->val);
delete pair;
}
}
}
/* Print hash table */
void print() {
for (Pair *pair : buckets) {
if (pair == nullptr) {
cout << "nullptr" << endl;
} else if (pair == TOMBSTONE) {
cout << "TOMBSTONE" << endl;
} else {
cout << pair->key << " -> " << pair->val << endl;
}
}
}
};
/* Hash table with open addressing */
class HashMapOpenAddressing {
private int size; // Number of key-value pairs
private int capacity = 4; // Hash table capacity
private final double loadThres = 2.0 / 3.0; // Load factor threshold for triggering expansion
private final int extendRatio = 2; // Expansion multiplier
private Pair[] buckets; // Bucket array
private final Pair TOMBSTONE = new Pair(-1, "-1"); // Removal marker
/* Constructor */
public HashMapOpenAddressing() {
size = 0;
buckets = new Pair[capacity];
}
/* Hash function */
private int hashFunc(int key) {
return key % capacity;
}
/* Load factor */
private double loadFactor() {
return (double) size / capacity;
}
/* Search for bucket index corresponding to key */
private int findBucket(int key) {
int index = hashFunc(key);
int firstTombstone = -1;
// Linear probing, break when encountering an empty bucket
while (buckets[index] != null) {
// If key is encountered, return the corresponding bucket index
if (buckets[index].key == key) {
// If a removal marker was encountered before, move the key-value pair to that index
if (firstTombstone != -1) {
buckets[firstTombstone] = buckets[index];
buckets[index] = TOMBSTONE;
return firstTombstone; // Return the moved bucket index
}
return index; // Return bucket index
}
// Record the first removal marker encountered
if (firstTombstone == -1 && buckets[index] == TOMBSTONE) {
firstTombstone = index;
}
// Calculate bucket index, wrap around to the head if past the tail
index = (index + 1) % capacity;
}
// If key does not exist, return the index for insertion
return firstTombstone == -1 ? index : firstTombstone;
}
/* Query operation */
public String get(int key) {
// Search for bucket index corresponding to key
int index = findBucket(key);
// If key-value pair is found, return corresponding val
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
return buckets[index].val;
}
// If key-value pair does not exist, return null
return null;
}
/* Add operation */
public void put(int key, String val) {
// When load factor exceeds threshold, perform expansion
if (loadFactor() > loadThres) {
extend();
}
// Search for bucket index corresponding to key
int index = findBucket(key);
// If key-value pair is found, overwrite val and return
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index].val = val;
return;
}
// If key-value pair does not exist, add the key-value pair
buckets[index] = new Pair(key, val);
size++;
}
/* Remove operation */
public void remove(int key) {
// Search for bucket index corresponding to key
int index = findBucket(key);
// If key-value pair is found, overwrite it with removal marker
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index] = TOMBSTONE;
size--;
}
}
/* Expand hash table */
private void extend() {
// Temporarily store the original hash table
Pair[] bucketsTmp = buckets;
// Initialize expanded new hash table
capacity *= extendRatio;
buckets = new Pair[capacity];
size = 0;
// Move key-value pairs from original hash table to new hash table
for (Pair pair : bucketsTmp) {
if (pair != null && pair != TOMBSTONE) {
put(pair.key, pair.val);
}
}
}
/* Print hash table */
public void print() {
for (Pair pair : buckets) {
if (pair == null) {
System.out.println("null");
} else if (pair == TOMBSTONE) {
System.out.println("TOMBSTONE");
} else {
System.out.println(pair.key + " -> " + pair.val);
}
}
}
}
/* Hash table with open addressing */
class HashMapOpenAddressing {
int size; // Number of key-value pairs
int capacity = 4; // Hash table capacity
double loadThres = 2.0 / 3.0; // Load factor threshold for triggering expansion
int extendRatio = 2; // Expansion multiplier
Pair[] buckets; // Bucket array
Pair TOMBSTONE = new(-1, "-1"); // Removal marker
/* Constructor */
public HashMapOpenAddressing() {
size = 0;
buckets = new Pair[capacity];
}
/* Hash function */
int HashFunc(int key) {
return key % capacity;
}
/* Load factor */
double LoadFactor() {
return (double)size / capacity;
}
/* Search for bucket index corresponding to key */
int FindBucket(int key) {
int index = HashFunc(key);
int firstTombstone = -1;
// Linear probing, break when encountering an empty bucket
while (buckets[index] != null) {
// If key is encountered, return the corresponding bucket index
if (buckets[index].key == key) {
// If a removal marker was encountered before, move the key-value pair to that index
if (firstTombstone != -1) {
buckets[firstTombstone] = buckets[index];
buckets[index] = TOMBSTONE;
return firstTombstone; // Return the moved bucket index
}
return index; // Return bucket index
}
// Record the first removal marker encountered
if (firstTombstone == -1 && buckets[index] == TOMBSTONE) {
firstTombstone = index;
}
// Calculate bucket index, wrap around to the head if past the tail
index = (index + 1) % capacity;
}
// If key does not exist, return the index for insertion
return firstTombstone == -1 ? index : firstTombstone;
}
/* Query operation */
public string? Get(int key) {
// Search for bucket index corresponding to key
int index = FindBucket(key);
// If key-value pair is found, return corresponding val
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
return buckets[index].val;
}
// If key-value pair does not exist, return null
return null;
}
/* Add operation */
public void Put(int key, string val) {
// When load factor exceeds threshold, perform expansion
if (LoadFactor() > loadThres) {
Extend();
}
// Search for bucket index corresponding to key
int index = FindBucket(key);
// If key-value pair is found, overwrite val and return
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index].val = val;
return;
}
// If key-value pair does not exist, add the key-value pair
buckets[index] = new Pair(key, val);
size++;
}
/* Remove operation */
public void Remove(int key) {
// Search for bucket index corresponding to key
int index = FindBucket(key);
// If key-value pair is found, overwrite it with removal marker
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index] = TOMBSTONE;
size--;
}
}
/* Expand hash table */
void Extend() {
// Temporarily store the original hash table
Pair[] bucketsTmp = buckets;
// Initialize expanded new hash table
capacity *= extendRatio;
buckets = new Pair[capacity];
size = 0;
// Move key-value pairs from original hash table to new hash table
foreach (Pair pair in bucketsTmp) {
if (pair != null && pair != TOMBSTONE) {
Put(pair.key, pair.val);
}
}
}
/* Print hash table */
public void Print() {
foreach (Pair pair in buckets) {
if (pair == null) {
Console.WriteLine("null");
} else if (pair == TOMBSTONE) {
Console.WriteLine("TOMBSTONE");
} else {
Console.WriteLine(pair.key + " -> " + pair.val);
}
}
}
}
/* Hash table with open addressing */
type hashMapOpenAddressing struct {
size int // Number of key-value pairs
capacity int // Hash table capacity
loadThres float64 // Load factor threshold for triggering expansion
extendRatio int // Expansion multiplier
buckets []*pair // Bucket array
TOMBSTONE *pair // Removal marker
}
/* Constructor */
func newHashMapOpenAddressing() *hashMapOpenAddressing {
return &hashMapOpenAddressing{
size: 0,
capacity: 4,
loadThres: 2.0 / 3.0,
extendRatio: 2,
buckets: make([]*pair, 4),
TOMBSTONE: &pair{-1, "-1"},
}
}
/* Hash function */
func (h *hashMapOpenAddressing) hashFunc(key int) int {
return key % h.capacity // Calculate hash value based on key
}
/* Load factor */
func (h *hashMapOpenAddressing) loadFactor() float64 {
return float64(h.size) / float64(h.capacity) // Calculate current load factor
}
/* Search for bucket index corresponding to key */
func (h *hashMapOpenAddressing) findBucket(key int) int {
index := h.hashFunc(key) // Get initial index
firstTombstone := -1 // Record position of first TOMBSTONE encountered
for h.buckets[index] != nil {
if h.buckets[index].key == key {
if firstTombstone != -1 {
// If a removal marker was encountered before, move the key-value pair to that index
h.buckets[firstTombstone] = h.buckets[index]
h.buckets[index] = h.TOMBSTONE
return firstTombstone // Return the moved bucket index
}
return index // Return found index
}
if firstTombstone == -1 && h.buckets[index] == h.TOMBSTONE {
firstTombstone = index // Record position of first deletion marker encountered
}
index = (index + 1) % h.capacity // Linear probing, wrap around to head if past tail
}
// If key does not exist, return the index for insertion
if firstTombstone != -1 {
return firstTombstone
}
return index
}
/* Query operation */
func (h *hashMapOpenAddressing) get(key int) string {
index := h.findBucket(key) // Search for bucket index corresponding to key
if h.buckets[index] != nil && h.buckets[index] != h.TOMBSTONE {
return h.buckets[index].val // If key-value pair is found, return corresponding val
}
return "" // Return "" if key-value pair does not exist
}
/* Add operation */
func (h *hashMapOpenAddressing) put(key int, val string) {
if h.loadFactor() > h.loadThres {
h.extend() // When load factor exceeds threshold, perform expansion
}
index := h.findBucket(key) // Search for bucket index corresponding to key
if h.buckets[index] == nil || h.buckets[index] == h.TOMBSTONE {
h.buckets[index] = &pair{key, val} // If key-value pair does not exist, add the key-value pair
h.size++
} else {
h.buckets[index].val = val // If key-value pair found, overwrite val
}
}
/* Remove operation */
func (h *hashMapOpenAddressing) remove(key int) {
index := h.findBucket(key) // Search for bucket index corresponding to key
if h.buckets[index] != nil && h.buckets[index] != h.TOMBSTONE {
h.buckets[index] = h.TOMBSTONE // If key-value pair is found, overwrite it with removal marker
h.size--
}
}
/* Expand hash table */
func (h *hashMapOpenAddressing) extend() {
oldBuckets := h.buckets // Temporarily store the original hash table
h.capacity *= h.extendRatio // Update capacity
h.buckets = make([]*pair, h.capacity) // Initialize expanded new hash table
h.size = 0 // Reset size
// Move key-value pairs from original hash table to new hash table
for _, pair := range oldBuckets {
if pair != nil && pair != h.TOMBSTONE {
h.put(pair.key, pair.val)
}
}
}
/* Print hash table */
func (h *hashMapOpenAddressing) print() {
for _, pair := range h.buckets {
if pair == nil {
fmt.Println("nil")
} else if pair == h.TOMBSTONE {
fmt.Println("TOMBSTONE")
} else {
fmt.Printf("%d -> %s\n", pair.key, pair.val)
}
}
}
/* Hash table with open addressing */
class HashMapOpenAddressing {
var size: Int // Number of key-value pairs
var capacity: Int // Hash table capacity
var loadThres: Double // Load factor threshold for triggering expansion
var extendRatio: Int // Expansion multiplier
var buckets: [Pair?] // Bucket array
var TOMBSTONE: Pair // Removal marker
/* Constructor */
init() {
size = 0
capacity = 4
loadThres = 2.0 / 3.0
extendRatio = 2
buckets = Array(repeating: nil, count: capacity)
TOMBSTONE = Pair(key: -1, val: "-1")
}
/* Hash function */
func hashFunc(key: Int) -> Int {
key % capacity
}
/* Load factor */
func loadFactor() -> Double {
Double(size) / Double(capacity)
}
/* Search for bucket index corresponding to key */
func findBucket(key: Int) -> Int {
var index = hashFunc(key: key)
var firstTombstone = -1
// Linear probing, break when encountering an empty bucket
while buckets[index] != nil {
// If key is encountered, return the corresponding bucket index
if buckets[index]!.key == key {
// If a removal marker was encountered before, move the key-value pair to that index
if firstTombstone != -1 {
buckets[firstTombstone] = buckets[index]
buckets[index] = TOMBSTONE
return firstTombstone // Return the moved bucket index
}
return index // Return bucket index
}
// Record the first removal marker encountered
if firstTombstone == -1 && buckets[index] == TOMBSTONE {
firstTombstone = index
}
// Calculate bucket index, wrap around to the head if past the tail
index = (index + 1) % capacity
}
// If key does not exist, return the index for insertion
return firstTombstone == -1 ? index : firstTombstone
}
/* Query operation */
func get(key: Int) -> String? {
// Search for bucket index corresponding to key
let index = findBucket(key: key)
// If key-value pair is found, return corresponding val
if buckets[index] != nil, buckets[index] != TOMBSTONE {
return buckets[index]!.val
}
// If key-value pair does not exist, return null
return nil
}
/* Add operation */
func put(key: Int, val: String) {
// When load factor exceeds threshold, perform expansion
if loadFactor() > loadThres {
extend()
}
// Search for bucket index corresponding to key
let index = findBucket(key: key)
// If key-value pair is found, overwrite val and return
if buckets[index] != nil, buckets[index] != TOMBSTONE {
buckets[index]!.val = val
return
}
// If key-value pair does not exist, add the key-value pair
buckets[index] = Pair(key: key, val: val)
size += 1
}
/* Remove operation */
func remove(key: Int) {
// Search for bucket index corresponding to key
let index = findBucket(key: key)
// If key-value pair is found, overwrite it with removal marker
if buckets[index] != nil, buckets[index] != TOMBSTONE {
buckets[index] = TOMBSTONE
size -= 1
}
}
/* Expand hash table */
func extend() {
// Temporarily store the original hash table
let bucketsTmp = buckets
// Initialize expanded new hash table
capacity *= extendRatio
buckets = Array(repeating: nil, count: capacity)
size = 0
// Move key-value pairs from original hash table to new hash table
for pair in bucketsTmp {
if let pair, pair != TOMBSTONE {
put(key: pair.key, val: pair.val)
}
}
}
/* Print hash table */
func print() {
for pair in buckets {
if pair == nil {
Swift.print("null")
} else if pair == TOMBSTONE {
Swift.print("TOMBSTONE")
} else {
Swift.print("\(pair!.key) -> \(pair!.val)")
}
}
}
}
/* Hash table with open addressing */
class HashMapOpenAddressing {
#size; // Number of key-value pairs
#capacity; // Hash table capacity
#loadThres; // Load factor threshold for triggering expansion
#extendRatio; // Expansion multiplier
#buckets; // Bucket array
#TOMBSTONE; // Removal marker
/* Constructor */
constructor() {
this.#size = 0; // Number of key-value pairs
this.#capacity = 4; // Hash table capacity
this.#loadThres = 2.0 / 3.0; // Load factor threshold for triggering expansion
this.#extendRatio = 2; // Expansion multiplier
this.#buckets = Array(this.#capacity).fill(null); // Bucket array
this.#TOMBSTONE = new Pair(-1, '-1'); // Removal marker
}
/* Hash function */
#hashFunc(key) {
return key % this.#capacity;
}
/* Load factor */
#loadFactor() {
return this.#size / this.#capacity;
}
/* Search for bucket index corresponding to key */
#findBucket(key) {
let index = this.#hashFunc(key);
let firstTombstone = -1;
// Linear probing, break when encountering an empty bucket
while (this.#buckets[index] !== null) {
// If key is encountered, return the corresponding bucket index
if (this.#buckets[index].key === key) {
// If a removal marker was encountered before, move the key-value pair to that index
if (firstTombstone !== -1) {
this.#buckets[firstTombstone] = this.#buckets[index];
this.#buckets[index] = this.#TOMBSTONE;
return firstTombstone; // Return the moved bucket index
}
return index; // Return bucket index
}
// Record the first removal marker encountered
if (
firstTombstone === -1 &&
this.#buckets[index] === this.#TOMBSTONE
) {
firstTombstone = index;
}
// Calculate bucket index, wrap around to the head if past the tail
index = (index + 1) % this.#capacity;
}
// If key does not exist, return the index for insertion
return firstTombstone === -1 ? index : firstTombstone;
}
/* Query operation */
get(key) {
// Search for bucket index corresponding to key
const index = this.#findBucket(key);
// If key-value pair is found, return corresponding val
if (
this.#buckets[index] !== null &&
this.#buckets[index] !== this.#TOMBSTONE
) {
return this.#buckets[index].val;
}
// If key-value pair does not exist, return null
return null;
}
/* Add operation */
put(key, val) {
// When load factor exceeds threshold, perform expansion
if (this.#loadFactor() > this.#loadThres) {
this.#extend();
}
// Search for bucket index corresponding to key
const index = this.#findBucket(key);
// If key-value pair is found, overwrite val and return
if (
this.#buckets[index] !== null &&
this.#buckets[index] !== this.#TOMBSTONE
) {
this.#buckets[index].val = val;
return;
}
// If key-value pair does not exist, add the key-value pair
this.#buckets[index] = new Pair(key, val);
this.#size++;
}
/* Remove operation */
remove(key) {
// Search for bucket index corresponding to key
const index = this.#findBucket(key);
// If key-value pair is found, overwrite it with removal marker
if (
this.#buckets[index] !== null &&
this.#buckets[index] !== this.#TOMBSTONE
) {
this.#buckets[index] = this.#TOMBSTONE;
this.#size--;
}
}
/* Expand hash table */
#extend() {
// Temporarily store the original hash table
const bucketsTmp = this.#buckets;
// Initialize expanded new hash table
this.#capacity *= this.#extendRatio;
this.#buckets = Array(this.#capacity).fill(null);
this.#size = 0;
// Move key-value pairs from original hash table to new hash table
for (const pair of bucketsTmp) {
if (pair !== null && pair !== this.#TOMBSTONE) {
this.put(pair.key, pair.val);
}
}
}
/* Print hash table */
print() {
for (const pair of this.#buckets) {
if (pair === null) {
console.log('null');
} else if (pair === this.#TOMBSTONE) {
console.log('TOMBSTONE');
} else {
console.log(pair.key + ' -> ' + pair.val);
}
}
}
}
/* Hash table with open addressing */
class HashMapOpenAddressing {
private size: number; // Number of key-value pairs
private capacity: number; // Hash table capacity
private loadThres: number; // Load factor threshold for triggering expansion
private extendRatio: number; // Expansion multiplier
private buckets: Array<Pair | null>; // Bucket array
private TOMBSTONE: Pair; // Removal marker
/* Constructor */
constructor() {
this.size = 0; // Number of key-value pairs
this.capacity = 4; // Hash table capacity
this.loadThres = 2.0 / 3.0; // Load factor threshold for triggering expansion
this.extendRatio = 2; // Expansion multiplier
this.buckets = Array(this.capacity).fill(null); // Bucket array
this.TOMBSTONE = new Pair(-1, '-1'); // Removal marker
}
/* Hash function */
private hashFunc(key: number): number {
return key % this.capacity;
}
/* Load factor */
private loadFactor(): number {
return this.size / this.capacity;
}
/* Search for bucket index corresponding to key */
private findBucket(key: number): number {
let index = this.hashFunc(key);
let firstTombstone = -1;
// Linear probing, break when encountering an empty bucket
while (this.buckets[index] !== null) {
// If key is encountered, return the corresponding bucket index
if (this.buckets[index]!.key === key) {
// If a removal marker was encountered before, move the key-value pair to that index
if (firstTombstone !== -1) {
this.buckets[firstTombstone] = this.buckets[index];
this.buckets[index] = this.TOMBSTONE;
return firstTombstone; // Return the moved bucket index
}
return index; // Return bucket index
}
// Record the first removal marker encountered
if (
firstTombstone === -1 &&
this.buckets[index] === this.TOMBSTONE
) {
firstTombstone = index;
}
// Calculate bucket index, wrap around to the head if past the tail
index = (index + 1) % this.capacity;
}
// If key does not exist, return the index for insertion
return firstTombstone === -1 ? index : firstTombstone;
}
/* Query operation */
get(key: number): string | null {
// Search for bucket index corresponding to key
const index = this.findBucket(key);
// If key-value pair is found, return corresponding val
if (
this.buckets[index] !== null &&
this.buckets[index] !== this.TOMBSTONE
) {
return this.buckets[index]!.val;
}
// If key-value pair does not exist, return null
return null;
}
/* Add operation */
put(key: number, val: string): void {
// When load factor exceeds threshold, perform expansion
if (this.loadFactor() > this.loadThres) {
this.extend();
}
// Search for bucket index corresponding to key
const index = this.findBucket(key);
// If key-value pair is found, overwrite val and return
if (
this.buckets[index] !== null &&
this.buckets[index] !== this.TOMBSTONE
) {
this.buckets[index]!.val = val;
return;
}
// If key-value pair does not exist, add the key-value pair
this.buckets[index] = new Pair(key, val);
this.size++;
}
/* Remove operation */
remove(key: number): void {
// Search for bucket index corresponding to key
const index = this.findBucket(key);
// If key-value pair is found, overwrite it with removal marker
if (
this.buckets[index] !== null &&
this.buckets[index] !== this.TOMBSTONE
) {
this.buckets[index] = this.TOMBSTONE;
this.size--;
}
}
/* Expand hash table */
private extend(): void {
// Temporarily store the original hash table
const bucketsTmp = this.buckets;
// Initialize expanded new hash table
this.capacity *= this.extendRatio;
this.buckets = Array(this.capacity).fill(null);
this.size = 0;
// Move key-value pairs from original hash table to new hash table
for (const pair of bucketsTmp) {
if (pair !== null && pair !== this.TOMBSTONE) {
this.put(pair.key, pair.val);
}
}
}
/* Print hash table */
print(): void {
for (const pair of this.buckets) {
if (pair === null) {
console.log('null');
} else if (pair === this.TOMBSTONE) {
console.log('TOMBSTONE');
} else {
console.log(pair.key + ' -> ' + pair.val);
}
}
}
}
/* Hash table with open addressing */
class HashMapOpenAddressing {
late int _size; // Number of key-value pairs
int _capacity = 4; // Hash table capacity
double _loadThres = 2.0 / 3.0; // Load factor threshold for triggering expansion
int _extendRatio = 2; // Expansion multiplier
late List<Pair?> _buckets; // Bucket array
Pair _TOMBSTONE = Pair(-1, "-1"); // Removal marker
/* Constructor */
HashMapOpenAddressing() {
_size = 0;
_buckets = List.generate(_capacity, (index) => null);
}
/* Hash function */
int hashFunc(int key) {
return key % _capacity;
}
/* Load factor */
double loadFactor() {
return _size / _capacity;
}
/* Search for bucket index corresponding to key */
int findBucket(int key) {
int index = hashFunc(key);
int firstTombstone = -1;
// Linear probing, break when encountering an empty bucket
while (_buckets[index] != null) {
// If key is encountered, return the corresponding bucket index
if (_buckets[index]!.key == key) {
// If a removal marker was encountered before, move the key-value pair to that index
if (firstTombstone != -1) {
_buckets[firstTombstone] = _buckets[index];
_buckets[index] = _TOMBSTONE;
return firstTombstone; // Return the moved bucket index
}
return index; // Return bucket index
}
// Record the first removal marker encountered
if (firstTombstone == -1 && _buckets[index] == _TOMBSTONE) {
firstTombstone = index;
}
// Calculate bucket index, wrap around to the head if past the tail
index = (index + 1) % _capacity;
}
// If key does not exist, return the index for insertion
return firstTombstone == -1 ? index : firstTombstone;
}
/* Query operation */
String? get(int key) {
// Search for bucket index corresponding to key
int index = findBucket(key);
// If key-value pair is found, return corresponding val
if (_buckets[index] != null && _buckets[index] != _TOMBSTONE) {
return _buckets[index]!.val;
}
// If key-value pair does not exist, return null
return null;
}
/* Add operation */
void put(int key, String val) {
// When load factor exceeds threshold, perform expansion
if (loadFactor() > _loadThres) {
extend();
}
// Search for bucket index corresponding to key
int index = findBucket(key);
// If key-value pair is found, overwrite val and return
if (_buckets[index] != null && _buckets[index] != _TOMBSTONE) {
_buckets[index]!.val = val;
return;
}
// If key-value pair does not exist, add the key-value pair
_buckets[index] = new Pair(key, val);
_size++;
}
/* Remove operation */
void remove(int key) {
// Search for bucket index corresponding to key
int index = findBucket(key);
// If key-value pair is found, overwrite it with removal marker
if (_buckets[index] != null && _buckets[index] != _TOMBSTONE) {
_buckets[index] = _TOMBSTONE;
_size--;
}
}
/* Expand hash table */
void extend() {
// Temporarily store the original hash table
List<Pair?> bucketsTmp = _buckets;
// Initialize expanded new hash table
_capacity *= _extendRatio;
_buckets = List.generate(_capacity, (index) => null);
_size = 0;
// Move key-value pairs from original hash table to new hash table
for (Pair? pair in bucketsTmp) {
if (pair != null && pair != _TOMBSTONE) {
put(pair.key, pair.val);
}
}
}
/* Print hash table */
void printHashMap() {
for (Pair? pair in _buckets) {
if (pair == null) {
print("null");
} else if (pair == _TOMBSTONE) {
print("TOMBSTONE");
} else {
print("${pair.key} -> ${pair.val}");
}
}
}
}
/* Hash table with open addressing */
struct HashMapOpenAddressing {
size: usize, // Number of key-value pairs
capacity: usize, // Hash table capacity
load_thres: f64, // Load factor threshold for triggering expansion
extend_ratio: usize, // Expansion multiplier
buckets: Vec<Option<Pair>>, // Bucket array
TOMBSTONE: Option<Pair>, // Removal marker
}
impl HashMapOpenAddressing {
/* Constructor */
fn new() -> Self {
Self {
size: 0,
capacity: 4,
load_thres: 2.0 / 3.0,
extend_ratio: 2,
buckets: vec![None; 4],
TOMBSTONE: Some(Pair {
key: -1,
val: "-1".to_string(),
}),
}
}
/* Hash function */
fn hash_func(&self, key: i32) -> usize {
(key % self.capacity as i32) as usize
}
/* Load factor */
fn load_factor(&self) -> f64 {
self.size as f64 / self.capacity as f64
}
/* Search for bucket index corresponding to key */
fn find_bucket(&mut self, key: i32) -> usize {
let mut index = self.hash_func(key);
let mut first_tombstone = -1;
// Linear probing, break when encountering an empty bucket
while self.buckets[index].is_some() {
// If key is found, return corresponding bucket index
if self.buckets[index].as_ref().unwrap().key == key {
// If deletion marker was encountered before, move key-value pair to that index
if first_tombstone != -1 {
self.buckets[first_tombstone as usize] = self.buckets[index].take();
self.buckets[index] = self.TOMBSTONE.clone();
return first_tombstone as usize; // Return the moved bucket index
}
return index; // Return bucket index
}
// Record the first removal marker encountered
if first_tombstone == -1 && self.buckets[index] == self.TOMBSTONE {
first_tombstone = index as i32;
}
// Calculate bucket index, wrap around to the head if past the tail
index = (index + 1) % self.capacity;
}
// If key does not exist, return the index for insertion
if first_tombstone == -1 {
index
} else {
first_tombstone as usize
}
}
/* Query operation */
fn get(&mut self, key: i32) -> Option<&str> {
// Search for bucket index corresponding to key
let index = self.find_bucket(key);
// If key-value pair is found, return corresponding val
if self.buckets[index].is_some() && self.buckets[index] != self.TOMBSTONE {
return self.buckets[index].as_ref().map(|pair| &pair.val as &str);
}
// If key-value pair does not exist, return null
None
}
/* Add operation */
fn put(&mut self, key: i32, val: String) {
// When load factor exceeds threshold, perform expansion
if self.load_factor() > self.load_thres {
self.extend();
}
// Search for bucket index corresponding to key
let index = self.find_bucket(key);
// If key-value pair is found, overwrite val and return
if self.buckets[index].is_some() && self.buckets[index] != self.TOMBSTONE {
self.buckets[index].as_mut().unwrap().val = val;
return;
}
// If key-value pair does not exist, add the key-value pair
self.buckets[index] = Some(Pair { key, val });
self.size += 1;
}
/* Remove operation */
fn remove(&mut self, key: i32) {
// Search for bucket index corresponding to key
let index = self.find_bucket(key);
// If key-value pair is found, overwrite it with removal marker
if self.buckets[index].is_some() && self.buckets[index] != self.TOMBSTONE {
self.buckets[index] = self.TOMBSTONE.clone();
self.size -= 1;
}
}
/* Expand hash table */
fn extend(&mut self) {
// Temporarily store the original hash table
let buckets_tmp = self.buckets.clone();
// Initialize expanded new hash table
self.capacity *= self.extend_ratio;
self.buckets = vec![None; self.capacity];
self.size = 0;
// Move key-value pairs from original hash table to new hash table
for pair in buckets_tmp {
if pair.is_none() || pair == self.TOMBSTONE {
continue;
}
let pair = pair.unwrap();
self.put(pair.key, pair.val);
}
}
/* Print hash table */
fn print(&self) {
for pair in &self.buckets {
if pair.is_none() {
println!("null");
} else if pair == &self.TOMBSTONE {
println!("TOMBSTONE");
} else {
let pair = pair.as_ref().unwrap();
println!("{} -> {}", pair.key, pair.val);
}
}
}
}
/* Hash table with open addressing */
typedef struct {
int size; // Number of key-value pairs
int capacity; // Hash table capacity
double loadThres; // Load factor threshold for triggering expansion
int extendRatio; // Expansion multiplier
Pair **buckets; // Bucket array
Pair *TOMBSTONE; // Removal marker
} HashMapOpenAddressing;
/* Constructor */
HashMapOpenAddressing *newHashMapOpenAddressing() {
HashMapOpenAddressing *hashMap = (HashMapOpenAddressing *)malloc(sizeof(HashMapOpenAddressing));
hashMap->size = 0;
hashMap->capacity = 4;
hashMap->loadThres = 2.0 / 3.0;
hashMap->extendRatio = 2;
hashMap->buckets = (Pair **)calloc(hashMap->capacity, sizeof(Pair *));
hashMap->TOMBSTONE = (Pair *)malloc(sizeof(Pair));
hashMap->TOMBSTONE->key = -1;
hashMap->TOMBSTONE->val = "-1";
return hashMap;
}
/* Destructor */
void delHashMapOpenAddressing(HashMapOpenAddressing *hashMap) {
for (int i = 0; i < hashMap->capacity; i++) {
Pair *pair = hashMap->buckets[i];
if (pair != NULL && pair != hashMap->TOMBSTONE) {
free(pair->val);
free(pair);
}
}
free(hashMap->buckets);
free(hashMap->TOMBSTONE);
free(hashMap);
}
/* Hash function */
int hashFunc(HashMapOpenAddressing *hashMap, int key) {
return key % hashMap->capacity;
}
/* Load factor */
double loadFactor(HashMapOpenAddressing *hashMap) {
return (double)hashMap->size / (double)hashMap->capacity;
}
/* Search for bucket index corresponding to key */
int findBucket(HashMapOpenAddressing *hashMap, int key) {
int index = hashFunc(hashMap, key);
int firstTombstone = -1;
// Linear probing, break when encountering an empty bucket
while (hashMap->buckets[index] != NULL) {
// If key is encountered, return the corresponding bucket index
if (hashMap->buckets[index]->key == key) {
// If a removal marker was encountered before, move the key-value pair to that index
if (firstTombstone != -1) {
hashMap->buckets[firstTombstone] = hashMap->buckets[index];
hashMap->buckets[index] = hashMap->TOMBSTONE;
return firstTombstone; // Return the moved bucket index
}
return index; // Return bucket index
}
// Record the first removal marker encountered
if (firstTombstone == -1 && hashMap->buckets[index] == hashMap->TOMBSTONE) {
firstTombstone = index;
}
// Calculate bucket index, wrap around to the head if past the tail
index = (index + 1) % hashMap->capacity;
}
// If key does not exist, return the index for insertion
return firstTombstone == -1 ? index : firstTombstone;
}
/* Query operation */
char *get(HashMapOpenAddressing *hashMap, int key) {
// Search for bucket index corresponding to key
int index = findBucket(hashMap, key);
// If key-value pair is found, return corresponding val
if (hashMap->buckets[index] != NULL && hashMap->buckets[index] != hashMap->TOMBSTONE) {
return hashMap->buckets[index]->val;
}
// Return empty string if key-value pair does not exist
return "";
}
/* Add operation */
void put(HashMapOpenAddressing *hashMap, int key, char *val) {
// When load factor exceeds threshold, perform expansion
if (loadFactor(hashMap) > hashMap->loadThres) {
extend(hashMap);
}
// Search for bucket index corresponding to key
int index = findBucket(hashMap, key);
// If key-value pair is found, overwrite val and return
if (hashMap->buckets[index] != NULL && hashMap->buckets[index] != hashMap->TOMBSTONE) {
free(hashMap->buckets[index]->val);
hashMap->buckets[index]->val = (char *)malloc(sizeof(strlen(val) + 1));
strcpy(hashMap->buckets[index]->val, val);
hashMap->buckets[index]->val[strlen(val)] = '\0';
return;
}
// If key-value pair does not exist, add the key-value pair
Pair *pair = (Pair *)malloc(sizeof(Pair));
pair->key = key;
pair->val = (char *)malloc(sizeof(strlen(val) + 1));
strcpy(pair->val, val);
pair->val[strlen(val)] = '\0';
hashMap->buckets[index] = pair;
hashMap->size++;
}
/* Remove operation */
void removeItem(HashMapOpenAddressing *hashMap, int key) {
// Search for bucket index corresponding to key
int index = findBucket(hashMap, key);
// If key-value pair is found, overwrite it with removal marker
if (hashMap->buckets[index] != NULL && hashMap->buckets[index] != hashMap->TOMBSTONE) {
Pair *pair = hashMap->buckets[index];
free(pair->val);
free(pair);
hashMap->buckets[index] = hashMap->TOMBSTONE;
hashMap->size--;
}
}
/* Expand hash table */
void extend(HashMapOpenAddressing *hashMap) {
// Temporarily store the original hash table
Pair **bucketsTmp = hashMap->buckets;
int oldCapacity = hashMap->capacity;
// Initialize expanded new hash table
hashMap->capacity *= hashMap->extendRatio;
hashMap->buckets = (Pair **)calloc(hashMap->capacity, sizeof(Pair *));
hashMap->size = 0;
// Move key-value pairs from original hash table to new hash table
for (int i = 0; i < oldCapacity; i++) {
Pair *pair = bucketsTmp[i];
if (pair != NULL && pair != hashMap->TOMBSTONE) {
put(hashMap, pair->key, pair->val);
free(pair->val);
free(pair);
}
}
free(bucketsTmp);
}
/* Print hash table */
void print(HashMapOpenAddressing *hashMap) {
for (int i = 0; i < hashMap->capacity; i++) {
Pair *pair = hashMap->buckets[i];
if (pair == NULL) {
printf("NULL\n");
} else if (pair == hashMap->TOMBSTONE) {
printf("TOMBSTONE\n");
} else {
printf("%d -> %s\n", pair->key, pair->val);
}
}
}
/* Hash table with open addressing */
class HashMapOpenAddressing {
private var size: Int // Number of key-value pairs
private var capacity: Int // Hash table capacity
private val loadThres: Double // Load factor threshold for triggering expansion
private val extendRatio: Int // Expansion multiplier
private var buckets: Array<Pair?> // Bucket array
private val TOMBSTONE: Pair // Removal marker
/* Constructor */
init {
size = 0
capacity = 4
loadThres = 2.0 / 3.0
extendRatio = 2
buckets = arrayOfNulls(capacity)
TOMBSTONE = Pair(-1, "-1")
}
/* Hash function */
fun hashFunc(key: Int): Int {
return key % capacity
}
/* Load factor */
fun loadFactor(): Double {
return (size / capacity).toDouble()
}
/* Search for bucket index corresponding to key */
fun findBucket(key: Int): Int {
var index = hashFunc(key)
var firstTombstone = -1
// Linear probing, break when encountering an empty bucket
while (buckets[index] != null) {
// If key is encountered, return the corresponding bucket index
if (buckets[index]?.key == key) {
// If a removal marker was encountered before, move the key-value pair to that index
if (firstTombstone != -1) {
buckets[firstTombstone] = buckets[index]
buckets[index] = TOMBSTONE
return firstTombstone // Return the moved bucket index
}
return index // Return bucket index
}
// Record the first removal marker encountered
if (firstTombstone == -1 && buckets[index] == TOMBSTONE) {
firstTombstone = index
}
// Calculate bucket index, wrap around to the head if past the tail
index = (index + 1) % capacity
}
// If key does not exist, return the index for insertion
return if (firstTombstone == -1) index else firstTombstone
}
/* Query operation */
fun get(key: Int): String? {
// Search for bucket index corresponding to key
val index = findBucket(key)
// If key-value pair is found, return corresponding val
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
return buckets[index]?._val
}
// If key-value pair does not exist, return null
return null
}
/* Add operation */
fun put(key: Int, _val: String) {
// When load factor exceeds threshold, perform expansion
if (loadFactor() > loadThres) {
extend()
}
// Search for bucket index corresponding to key
val index = findBucket(key)
// If key-value pair is found, overwrite val and return
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index]!!._val = _val
return
}
// If key-value pair does not exist, add the key-value pair
buckets[index] = Pair(key, _val)
size++
}
/* Remove operation */
fun remove(key: Int) {
// Search for bucket index corresponding to key
val index = findBucket(key)
// If key-value pair is found, overwrite it with removal marker
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index] = TOMBSTONE
size--
}
}
/* Expand hash table */
fun extend() {
// Temporarily store the original hash table
val bucketsTmp = buckets
// Initialize expanded new hash table
capacity *= extendRatio
buckets = arrayOfNulls(capacity)
size = 0
// Move key-value pairs from original hash table to new hash table
for (pair in bucketsTmp) {
if (pair != null && pair != TOMBSTONE) {
put(pair.key, pair._val)
}
}
}
/* Print hash table */
fun print() {
for (pair in buckets) {
if (pair == null) {
println("null")
} else if (pair == TOMBSTONE) {
println("TOMESTOME")
} else {
println("${pair.key} -> ${pair._val}")
}
}
}
}
### Hash map with open addressing ###
class HashMapOpenAddressing
TOMBSTONE = Pair.new(-1, '-1') # Removal marker
### Constructor ###
def initialize
@size = 0 # Number of key-value pairs
@capacity = 4 # Hash table capacity
@load_thres = 2.0 / 3.0 # Load factor threshold for triggering expansion
@extend_ratio = 2 # Expansion multiplier
@buckets = Array.new(@capacity) # Bucket array
end
### Hash function ###
def hash_func(key)
key % @capacity
end
### Load factor ###
def load_factor
@size / @capacity
end
### Search bucket index for key ###
def find_bucket(key)
index = hash_func(key)
first_tombstone = -1
# Linear probing, break when encountering an empty bucket
while !@buckets[index].nil?
# If key is encountered, return the corresponding bucket index
if @buckets[index].key == key
# If a removal marker was encountered before, move the key-value pair to that index
if first_tombstone != -1
@buckets[first_tombstone] = @buckets[index]
@buckets[index] = TOMBSTONE
return first_tombstone # Return the moved bucket index
end
return index # Return bucket index
end
# Record the first removal marker encountered
first_tombstone = index if first_tombstone == -1 && @buckets[index] == TOMBSTONE
# Calculate bucket index, wrap around to the head if past the tail
index = (index + 1) % @capacity
end
# If key does not exist, return the index for insertion
first_tombstone == -1 ? index : first_tombstone
end
### Query operation ###
def get(key)
# Search for bucket index corresponding to key
index = find_bucket(key)
# If key-value pair is found, return corresponding val
return @buckets[index].val unless [nil, TOMBSTONE].include?(@buckets[index])
# Return nil if key-value pair does not exist
nil
end
### Add operation ###
def put(key, val)
# When load factor exceeds threshold, perform expansion
extend if load_factor > @load_thres
# Search for bucket index corresponding to key
index = find_bucket(key)
# If key-value pair found, overwrite val and return
unless [nil, TOMBSTONE].include?(@buckets[index])
@buckets[index].val = val
return
end
# If key-value pair does not exist, add the key-value pair
@buckets[index] = Pair.new(key, val)
@size += 1
end
### Delete operation ###
def remove(key)
# Search for bucket index corresponding to key
index = find_bucket(key)
# If key-value pair is found, overwrite it with removal marker
unless [nil, TOMBSTONE].include?(@buckets[index])
@buckets[index] = TOMBSTONE
@size -= 1
end
end
### Expand hash table ###
def extend
# Temporarily store the original hash table
buckets_tmp = @buckets
# Initialize expanded new hash table
@capacity *= @extend_ratio
@buckets = Array.new(@capacity)
@size = 0
# Move key-value pairs from original hash table to new hash table
for pair in buckets_tmp
put(pair.key, pair.val) unless [nil, TOMBSTONE].include?(pair)
end
end
### Print hash table ###
def print
for pair in @buckets
if pair.nil?
puts "Nil"
elsif pair == TOMBSTONE
puts "TOMBSTONE"
else
puts "#{pair.key} -> #{pair.val}"
end
end
end
end
2. Quadratic Probing¶
Quadratic probing is similar to linear probing and is one of the common strategies for open addressing. When a collision occurs, quadratic probing does not simply skip a fixed number of steps but skips a number of steps equal to the "square of the number of probes", i.e., \(1, 4, 9, \dots\) steps.
Quadratic probing has the following advantages:
- Quadratic probing attempts to alleviate the clustering effect of linear probing by skipping distances equal to the square of the probe count.
- Quadratic probing skips larger distances to find empty positions, which helps to distribute data more evenly.
However, quadratic probing is not perfect:
- Clustering still exists, i.e., some positions are more likely to be occupied than others.
- Due to the growth of squares, quadratic probing may not probe the entire hash table, meaning that even if there are empty buckets in the hash table, quadratic probing may not be able to access them.
3. Multiple Hashing¶
As the name suggests, multiple hashing uses multiple hash functions \(f_1(x)\), \(f_2(x)\), \(f_3(x)\), \(\dots\) for probing.
- Inserting elements: If hash function \(f_1(x)\) encounters a conflict, try \(f_2(x)\), and so on, until an empty position is found and the element is inserted.
- Searching for elements: Search in the same order of hash functions until the target element is found and return it; if an empty position is encountered or all hash functions have been tried, it indicates the element is not in the hash table, then return
None.
Compared with linear probing, multiple hashing is less prone to clustering, but using multiple hash functions introduces additional computational overhead.
Tip
Please note that hash tables based on open addressing, including linear probing, quadratic probing, and multiple hashing, all have the problem that elements cannot be deleted directly.
6.2.3 Choice of Programming Languages¶
Different programming languages adopt different hash table implementation strategies. Here are a few examples:
- Python uses open addressing. The
dictdictionary uses pseudo-random numbers for probing. - Java uses separate chaining. Since JDK 1.8, when the array length in
HashMapreaches 64 and the length of a linked list reaches 8, the linked list is converted to a red-black tree to improve search performance. - Go uses separate chaining. Go stipulates that each bucket can store up to 8 key-value pairs, and if the capacity is exceeded, an overflow bucket is linked; when there are too many overflow buckets, a special equal-capacity expansion operation is performed to ensure performance.