6.1 Hash Table¶
A hash table, also known as a hash map, stores mappings from keys key to values value, enabling efficient lookups. Specifically, given a key key, we can retrieve the corresponding value value from a hash table in \(O(1)\) time.
As shown below, suppose we have \(n\) students, each with two pieces of information: a name and a student ID. If we want to support the query "given a student ID, return the corresponding name," we can use the hash table shown below.
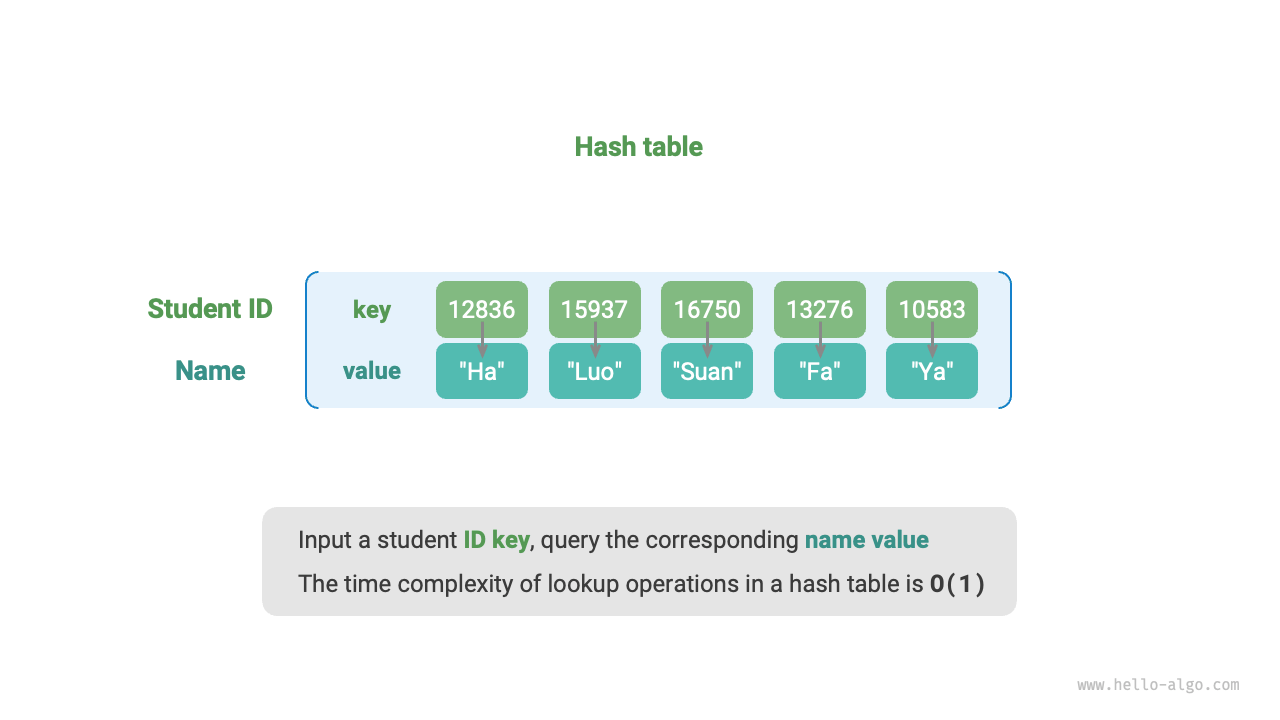
Figure 6-1 Abstract representation of a hash table
In addition to hash tables, arrays and linked lists can also implement query functionality. Their efficiency comparison is shown in the following table.
- Adding elements: Simply add elements to the end of the array (linked list), using \(O(1)\) time.
- Querying elements: Since the array (linked list) is unordered, all elements need to be traversed, using \(O(n)\) time.
- Deleting elements: The element must first be located, then deleted from the array (linked list), using \(O(n)\) time.
Table 6-1 Comparison of element query efficiency
| Array | Linked List | Hash Table | |
|---|---|---|---|
| Find element | \(O(n)\) | \(O(n)\) | \(O(1)\) |
| Add element | \(O(1)\) | \(O(1)\) | \(O(1)\) |
| Delete element | \(O(n)\) | \(O(n)\) | \(O(1)\) |
As we can see, insertion, deletion, lookup, and update operations in a hash table all have time complexity \(O(1)\), making hash tables highly efficient.
6.1.1 Common Hash Table Operations¶
Common operations on hash tables include: initialization, query operations, adding key-value pairs, and deleting key-value pairs. Example code is as follows:
# Initialize hash table
hmap: dict = {}
# Add operation
# Add key-value pair (key, value) to hash table
hmap[12836] = "XiaoHa"
hmap[15937] = "XiaoLuo"
hmap[16750] = "XiaoSuan"
hmap[13276] = "XiaoFa"
hmap[10583] = "XiaoYa"
# Query operation
# Input key into hash table to get value
name: str = hmap[15937]
# Delete operation
# Delete key-value pair (key, value) from hash table
hmap.pop(10583)
/* Initialize hash table */
unordered_map<int, string> map;
/* Add operation */
// Add key-value pair (key, value) to hash table
map[12836] = "XiaoHa";
map[15937] = "XiaoLuo";
map[16750] = "XiaoSuan";
map[13276] = "XiaoFa";
map[10583] = "XiaoYa";
/* Query operation */
// Input key into hash table to get value
string name = map[15937];
/* Delete operation */
// Delete key-value pair (key, value) from hash table
map.erase(10583);
/* Initialize hash table */
Map<Integer, String> map = new HashMap<>();
/* Add operation */
// Add key-value pair (key, value) to hash table
map.put(12836, "XiaoHa");
map.put(15937, "XiaoLuo");
map.put(16750, "XiaoSuan");
map.put(13276, "XiaoFa");
map.put(10583, "XiaoYa");
/* Query operation */
// Input key into hash table to get value
String name = map.get(15937);
/* Delete operation */
// Delete key-value pair (key, value) from hash table
map.remove(10583);
/* Initialize hash table */
Dictionary<int, string> map = new() {
/* Add operation */
// Add key-value pair (key, value) to hash table
{ 12836, "XiaoHa" },
{ 15937, "XiaoLuo" },
{ 16750, "XiaoSuan" },
{ 13276, "XiaoFa" },
{ 10583, "XiaoYa" }
};
/* Query operation */
// Input key into hash table to get value
string name = map[15937];
/* Delete operation */
// Delete key-value pair (key, value) from hash table
map.Remove(10583);
/* Initialize hash table */
hmap := make(map[int]string)
/* Add operation */
// Add key-value pair (key, value) to hash table
hmap[12836] = "XiaoHa"
hmap[15937] = "XiaoLuo"
hmap[16750] = "XiaoSuan"
hmap[13276] = "XiaoFa"
hmap[10583] = "XiaoYa"
/* Query operation */
// Input key into hash table to get value
name := hmap[15937]
/* Delete operation */
// Delete key-value pair (key, value) from hash table
delete(hmap, 10583)
/* Initialize hash table */
var map: [Int: String] = [:]
/* Add operation */
// Add key-value pair (key, value) to hash table
map[12836] = "XiaoHa"
map[15937] = "XiaoLuo"
map[16750] = "XiaoSuan"
map[13276] = "XiaoFa"
map[10583] = "XiaoYa"
/* Query operation */
// Input key into hash table to get value
let name = map[15937]!
/* Delete operation */
// Delete key-value pair (key, value) from hash table
map.removeValue(forKey: 10583)
/* Initialize hash table */
const map = new Map();
/* Add operation */
// Add key-value pair (key, value) to hash table
map.set(12836, 'XiaoHa');
map.set(15937, 'XiaoLuo');
map.set(16750, 'XiaoSuan');
map.set(13276, 'XiaoFa');
map.set(10583, 'XiaoYa');
/* Query operation */
// Input key into hash table to get value
let name = map.get(15937);
/* Delete operation */
// Delete key-value pair (key, value) from hash table
map.delete(10583);
/* Initialize hash table */
const map = new Map<number, string>();
/* Add operation */
// Add key-value pair (key, value) to hash table
map.set(12836, 'XiaoHa');
map.set(15937, 'XiaoLuo');
map.set(16750, 'XiaoSuan');
map.set(13276, 'XiaoFa');
map.set(10583, 'XiaoYa');
console.info('\nAfter adding, hash table is\nKey -> Value');
console.info(map);
/* Query operation */
// Input key into hash table to get value
let name = map.get(15937);
console.info('\nInput student ID 15937, queried name ' + name);
/* Delete operation */
// Delete key-value pair (key, value) from hash table
map.delete(10583);
console.info('\nAfter deleting 10583, hash table is\nKey -> Value');
console.info(map);
/* Initialize hash table */
Map<int, String> map = {};
/* Add operation */
// Add key-value pair (key, value) to hash table
map[12836] = "XiaoHa";
map[15937] = "XiaoLuo";
map[16750] = "XiaoSuan";
map[13276] = "XiaoFa";
map[10583] = "XiaoYa";
/* Query operation */
// Input key into hash table to get value
String name = map[15937];
/* Delete operation */
// Delete key-value pair (key, value) from hash table
map.remove(10583);
use std::collections::HashMap;
/* Initialize hash table */
let mut map: HashMap<i32, String> = HashMap::new();
/* Add operation */
// Add key-value pair (key, value) to hash table
map.insert(12836, "XiaoHa".to_string());
map.insert(15937, "XiaoLuo".to_string());
map.insert(16750, "XiaoSuan".to_string());
map.insert(13276, "XiaoFa".to_string());
map.insert(10583, "XiaoYa".to_string());
/* Query operation */
// Input key into hash table to get value
let _name: Option<&String> = map.get(&15937);
/* Delete operation */
// Delete key-value pair (key, value) from hash table
let _removed_value: Option<String> = map.remove(&10583);
/* Initialize hash table */
val map = HashMap<Int,String>()
/* Add operation */
// Add key-value pair (key, value) to hash table
map[12836] = "XiaoHa"
map[15937] = "XiaoLuo"
map[16750] = "XiaoSuan"
map[13276] = "XiaoFa"
map[10583] = "XiaoYa"
/* Query operation */
// Input key into hash table to get value
val name = map[15937]
/* Delete operation */
// Delete key-value pair (key, value) from hash table
map.remove(10583)
# Initialize hash table
hmap = {}
# Add operation
# Add key-value pair (key, value) to hash table
hmap[12836] = "XiaoHa"
hmap[15937] = "XiaoLuo"
hmap[16750] = "XiaoSuan"
hmap[13276] = "XiaoFa"
hmap[10583] = "XiaoYa"
# Query operation
# Input key into hash table to get value
name = hmap[15937]
# Delete operation
# Delete key-value pair (key, value) from hash table
hmap.delete(10583)
Visualized Execution
https://pythontutor.com/render.html#code=%22%22%22Driver%20Code%22%22%22%0Aif%20__name__%20%3D%3D%20%22__main__%22%3A%0A%20%20%20%20%23%20%E5%88%9D%E5%A7%8B%E5%8C%96%E5%93%88%E5%B8%8C%E8%A1%A8%0A%20%20%20%20hmap%20%3D%20%7B%7D%0A%20%20%20%20%0A%20%20%20%20%23%20%E6%B7%BB%E5%8A%A0%E6%93%8D%E4%BD%9C%0A%20%20%20%20%23%20%E5%9C%A8%E5%93%88%E5%B8%8C%E8%A1%A8%E4%B8%AD%E6%B7%BB%E5%8A%A0%E9%94%AE%E5%80%BC%E5%AF%B9%20%28key,%20value%29%0A%20%20%20%20hmap%5B12836%5D%20%3D%20%22%E5%B0%8F%E5%93%88%22%0A%20%20%20%20hmap%5B15937%5D%20%3D%20%22%E5%B0%8F%E5%95%B0%22%0A%20%20%20%20hmap%5B16750%5D%20%3D%20%22%E5%B0%8F%E7%AE%97%22%0A%20%20%20%20hmap%5B13276%5D%20%3D%20%22%E5%B0%8F%E6%B3%95%22%0A%20%20%20%20hmap%5B10583%5D%20%3D%20%22%E5%B0%8F%E9%B8%AD%22%0A%20%20%20%20%0A%20%20%20%20%23%20%E6%9F%A5%E8%AF%A2%E6%93%8D%E4%BD%9C%0A%20%20%20%20%23%20%E5%90%91%E5%93%88%E5%B8%8C%E8%A1%A8%E4%B8%AD%E8%BE%93%E5%85%A5%E9%94%AE%20key%20%EF%BC%8C%E5%BE%97%E5%88%B0%E5%80%BC%20value%0A%20%20%20%20name%20%3D%20hmap%5B15937%5D%0A%20%20%20%20%0A%20%20%20%20%23%20%E5%88%A0%E9%99%A4%E6%93%8D%E4%BD%9C%0A%20%20%20%20%23%20%E5%9C%A8%E5%93%88%E5%B8%8C%E8%A1%A8%E4%B8%AD%E5%88%A0%E9%99%A4%E9%94%AE%E5%80%BC%E5%AF%B9%20%28key,%20value%29%0A%20%20%20%20hmap.pop%2810583%29&cumulative=false&curInstr=2&heapPrimitives=nevernest&mode=display&origin=opt-frontend.js&py=311&rawInputLstJSON=%5B%5D&textReferences=false
There are three common ways to traverse a hash table: traversing key-value pairs, traversing keys, and traversing values. Example code is as follows:
/* Traverse hash table */
// Traverse key-value pairs key->value
for (auto kv: map) {
cout << kv.first << " -> " << kv.second << endl;
}
// Traverse using iterator key->value
for (auto iter = map.begin(); iter != map.end(); iter++) {
cout << iter->first << "->" << iter->second << endl;
}
/* Traverse hash table */
// Traverse key-value pairs key->value
for (Map.Entry<Integer, String> kv: map.entrySet()) {
System.out.println(kv.getKey() + " -> " + kv.getValue());
}
// Traverse keys only
for (int key: map.keySet()) {
System.out.println(key);
}
// Traverse values only
for (String val: map.values()) {
System.out.println(val);
}
/* Traverse hash table */
// Traverse key-value pairs Key->Value
foreach (var kv in map) {
Console.WriteLine(kv.Key + " -> " + kv.Value);
}
// Traverse keys only
foreach (int key in map.Keys) {
Console.WriteLine(key);
}
// Traverse values only
foreach (string val in map.Values) {
Console.WriteLine(val);
}
/* Traverse hash table */
console.info('\nTraverse key-value pairs Key->Value');
for (const [k, v] of map.entries()) {
console.info(k + ' -> ' + v);
}
console.info('\nTraverse keys only Key');
for (const k of map.keys()) {
console.info(k);
}
console.info('\nTraverse values only Value');
for (const v of map.values()) {
console.info(v);
}
/* Traverse hash table */
console.info('\nTraverse key-value pairs Key->Value');
for (const [k, v] of map.entries()) {
console.info(k + ' -> ' + v);
}
console.info('\nTraverse keys only Key');
for (const k of map.keys()) {
console.info(k);
}
console.info('\nTraverse values only Value');
for (const v of map.values()) {
console.info(v);
}
Visualized Execution
https://pythontutor.com/render.html#code=%22%22%22Driver%20Code%22%22%22%0Aif%20__name__%20%3D%3D%20%22__main__%22%3A%0A%20%20%20%20%23%20%E5%88%9D%E5%A7%8B%E5%8C%96%E5%93%88%E5%B8%8C%E8%A1%A8%0A%20%20%20%20hmap%20%3D%20%7B%7D%0A%20%20%20%20%0A%20%20%20%20%23%20%E6%B7%BB%E5%8A%A0%E6%93%8D%E4%BD%9C%0A%20%20%20%20%23%20%E5%9C%A8%E5%93%88%E5%B8%8C%E8%A1%A8%E4%B8%AD%E6%B7%BB%E5%8A%A0%E9%94%AE%E5%80%BC%E5%AF%B9%20%28key,%20value%29%0A%20%20%20%20hmap%5B12836%5D%20%3D%20%22%E5%B0%8F%E5%93%88%22%0A%20%20%20%20hmap%5B15937%5D%20%3D%20%22%E5%B0%8F%E5%95%B0%22%0A%20%20%20%20hmap%5B16750%5D%20%3D%20%22%E5%B0%8F%E7%AE%97%22%0A%20%20%20%20hmap%5B13276%5D%20%3D%20%22%E5%B0%8F%E6%B3%95%22%0A%20%20%20%20hmap%5B10583%5D%20%3D%20%22%E5%B0%8F%E9%B8%AD%22%0A%20%20%20%20%0A%20%20%20%20%23%20%E9%81%8D%E5%8E%86%E5%93%88%E5%B8%8C%E8%A1%A8%0A%20%20%20%20%23%20%E9%81%8D%E5%8E%86%E9%94%AE%E5%80%BC%E5%AF%B9%20key-%3Evalue%0A%20%20%20%20for%20key,%20value%20in%20hmap.items%28%29%3A%0A%20%20%20%20%20%20%20%20print%28key,%20%22-%3E%22,%20value%29%0A%20%20%20%20%23%20%E5%8D%95%E7%8B%AC%E9%81%8D%E5%8E%86%E9%94%AE%20key%0A%20%20%20%20for%20key%20in%20hmap.keys%28%29%3A%0A%20%20%20%20%20%20%20%20print%28key%29%0A%20%20%20%20%23%20%E5%8D%95%E7%8B%AC%E9%81%8D%E5%8E%86%E5%80%BC%20value%0A%20%20%20%20for%20value%20in%20hmap.values%28%29%3A%0A%20%20%20%20%20%20%20%20print%28value%29&cumulative=false&curInstr=8&heapPrimitives=nevernest&mode=display&origin=opt-frontend.js&py=311&rawInputLstJSON=%5B%5D&textReferences=false
6.1.2 Simple Hash Table Implementation¶
Let's start with the simplest case: implementing a hash table with just an array. In a hash table, each empty slot in the array is called a bucket, and each bucket can store one key-value pair. A lookup therefore consists of finding the bucket for key and reading the value stored there.
So how do we find the right bucket for a given key? We do this with a hash function. A hash function maps a larger input space to a smaller output space. In a hash table, the input space is the set of all keys, and the output space is the set of all buckets (array indices). In other words, given a key, the hash function tells us where the corresponding key-value pair should be stored in the array.
Given a key, computing the bucket index involves the following two steps:
- Use a hash algorithm
hash()to compute a hash value. - Take that hash value modulo the number of buckets (array length),
capacity, to obtain the bucket (array index)indexcorresponding to thekey.
We can then use index to access the corresponding bucket in the hash table and retrieve the value.
Suppose the array length is capacity = 100 and the hash algorithm is hash(key) = key. Then the hash function is key % 100. Figure 6-2 illustrates how this hash function works, using student ID as key and name as value.
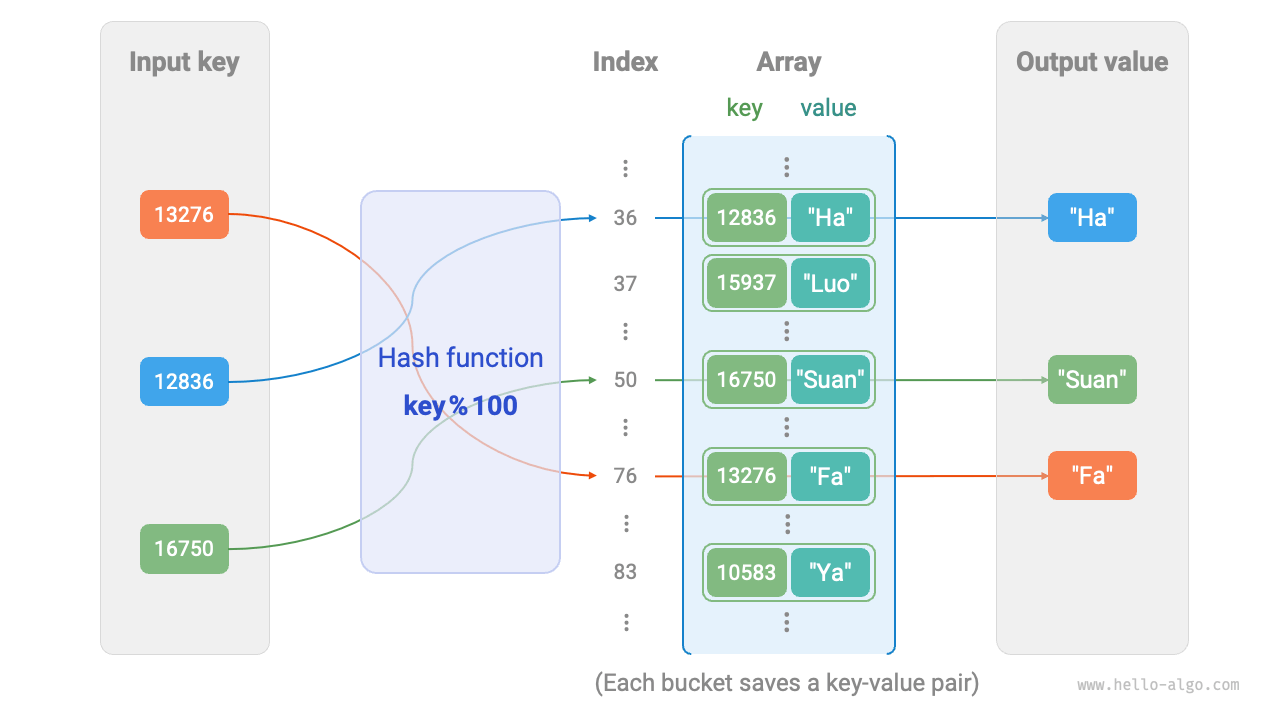
Figure 6-2 Working principle of hash function
The following code implements a simple hash table. Here, we encapsulate key and value into a class Pair to represent a key-value pair.
class Pair:
"""Key-value pair"""
def __init__(self, key: int, val: str):
self.key = key
self.val = val
class ArrayHashMap:
"""Hash table based on array implementation"""
def __init__(self):
"""Constructor"""
# Initialize array with 100 buckets
self.buckets: list[Pair | None] = [None] * 100
def hash_func(self, key: int) -> int:
"""Hash function"""
index = key % 100
return index
def get(self, key: int) -> str | None:
"""Query operation"""
index: int = self.hash_func(key)
pair: Pair = self.buckets[index]
if pair is None:
return None
return pair.val
def put(self, key: int, val: str):
"""Add and update operation"""
pair = Pair(key, val)
index: int = self.hash_func(key)
self.buckets[index] = pair
def remove(self, key: int):
"""Remove operation"""
index: int = self.hash_func(key)
# Set to None to represent removal
self.buckets[index] = None
def entry_set(self) -> list[Pair]:
"""Get all key-value pairs"""
result: list[Pair] = []
for pair in self.buckets:
if pair is not None:
result.append(pair)
return result
def key_set(self) -> list[int]:
"""Get all keys"""
result = []
for pair in self.buckets:
if pair is not None:
result.append(pair.key)
return result
def value_set(self) -> list[str]:
"""Get all values"""
result = []
for pair in self.buckets:
if pair is not None:
result.append(pair.val)
return result
def print(self):
"""Print hash table"""
for pair in self.buckets:
if pair is not None:
print(pair.key, "->", pair.val)
/* Key-value pair */
struct Pair {
public:
int key;
string val;
Pair(int key, string val) {
this->key = key;
this->val = val;
}
};
/* Hash table based on array implementation */
class ArrayHashMap {
private:
vector<Pair *> buckets;
public:
ArrayHashMap() {
// Initialize array with 100 buckets
buckets = vector<Pair *>(100);
}
~ArrayHashMap() {
// Free memory
for (const auto &bucket : buckets) {
delete bucket;
}
buckets.clear();
}
/* Hash function */
int hashFunc(int key) {
int index = key % 100;
return index;
}
/* Query operation */
string get(int key) {
int index = hashFunc(key);
Pair *pair = buckets[index];
if (pair == nullptr)
return "";
return pair->val;
}
/* Add operation */
void put(int key, string val) {
Pair *pair = new Pair(key, val);
int index = hashFunc(key);
buckets[index] = pair;
}
/* Remove operation */
void remove(int key) {
int index = hashFunc(key);
// Free memory and set to nullptr
delete buckets[index];
buckets[index] = nullptr;
}
/* Get all key-value pairs */
vector<Pair *> pairSet() {
vector<Pair *> pairSet;
for (Pair *pair : buckets) {
if (pair != nullptr) {
pairSet.push_back(pair);
}
}
return pairSet;
}
/* Get all keys */
vector<int> keySet() {
vector<int> keySet;
for (Pair *pair : buckets) {
if (pair != nullptr) {
keySet.push_back(pair->key);
}
}
return keySet;
}
/* Get all values */
vector<string> valueSet() {
vector<string> valueSet;
for (Pair *pair : buckets) {
if (pair != nullptr) {
valueSet.push_back(pair->val);
}
}
return valueSet;
}
/* Print hash table */
void print() {
for (Pair *kv : pairSet()) {
cout << kv->key << " -> " << kv->val << endl;
}
}
};
/* Key-value pair */
class Pair {
public int key;
public String val;
public Pair(int key, String val) {
this.key = key;
this.val = val;
}
}
/* Hash table based on array implementation */
class ArrayHashMap {
private List<Pair> buckets;
public ArrayHashMap() {
// Initialize array with 100 buckets
buckets = new ArrayList<>();
for (int i = 0; i < 100; i++) {
buckets.add(null);
}
}
/* Hash function */
private int hashFunc(int key) {
int index = key % 100;
return index;
}
/* Query operation */
public String get(int key) {
int index = hashFunc(key);
Pair pair = buckets.get(index);
if (pair == null)
return null;
return pair.val;
}
/* Add operation */
public void put(int key, String val) {
Pair pair = new Pair(key, val);
int index = hashFunc(key);
buckets.set(index, pair);
}
/* Remove operation */
public void remove(int key) {
int index = hashFunc(key);
// Set to null to represent deletion
buckets.set(index, null);
}
/* Get all key-value pairs */
public List<Pair> pairSet() {
List<Pair> pairSet = new ArrayList<>();
for (Pair pair : buckets) {
if (pair != null)
pairSet.add(pair);
}
return pairSet;
}
/* Get all keys */
public List<Integer> keySet() {
List<Integer> keySet = new ArrayList<>();
for (Pair pair : buckets) {
if (pair != null)
keySet.add(pair.key);
}
return keySet;
}
/* Get all values */
public List<String> valueSet() {
List<String> valueSet = new ArrayList<>();
for (Pair pair : buckets) {
if (pair != null)
valueSet.add(pair.val);
}
return valueSet;
}
/* Print hash table */
public void print() {
for (Pair kv : pairSet()) {
System.out.println(kv.key + " -> " + kv.val);
}
}
}
/* Key-value pair int->string */
class Pair(int key, string val) {
public int key = key;
public string val = val;
}
/* Hash table based on array implementation */
class ArrayHashMap {
List<Pair?> buckets;
public ArrayHashMap() {
// Initialize array with 100 buckets
buckets = [];
for (int i = 0; i < 100; i++) {
buckets.Add(null);
}
}
/* Hash function */
int HashFunc(int key) {
int index = key % 100;
return index;
}
/* Query operation */
public string? Get(int key) {
int index = HashFunc(key);
Pair? pair = buckets[index];
if (pair == null) return null;
return pair.val;
}
/* Add operation */
public void Put(int key, string val) {
Pair pair = new(key, val);
int index = HashFunc(key);
buckets[index] = pair;
}
/* Remove operation */
public void Remove(int key) {
int index = HashFunc(key);
// Set to null to represent deletion
buckets[index] = null;
}
/* Get all key-value pairs */
public List<Pair> PairSet() {
List<Pair> pairSet = [];
foreach (Pair? pair in buckets) {
if (pair != null)
pairSet.Add(pair);
}
return pairSet;
}
/* Get all keys */
public List<int> KeySet() {
List<int> keySet = [];
foreach (Pair? pair in buckets) {
if (pair != null)
keySet.Add(pair.key);
}
return keySet;
}
/* Get all values */
public List<string> ValueSet() {
List<string> valueSet = [];
foreach (Pair? pair in buckets) {
if (pair != null)
valueSet.Add(pair.val);
}
return valueSet;
}
/* Print hash table */
public void Print() {
foreach (Pair kv in PairSet()) {
Console.WriteLine(kv.key + " -> " + kv.val);
}
}
}
/* Key-value pair */
type pair struct {
key int
val string
}
/* Hash table based on array implementation */
type arrayHashMap struct {
buckets []*pair
}
/* Initialize hash table */
func newArrayHashMap() *arrayHashMap {
// Initialize array with 100 buckets
buckets := make([]*pair, 100)
return &arrayHashMap{buckets: buckets}
}
/* Hash function */
func (a *arrayHashMap) hashFunc(key int) int {
index := key % 100
return index
}
/* Query operation */
func (a *arrayHashMap) get(key int) string {
index := a.hashFunc(key)
pair := a.buckets[index]
if pair == nil {
return "Not Found"
}
return pair.val
}
/* Add operation */
func (a *arrayHashMap) put(key int, val string) {
pair := &pair{key: key, val: val}
index := a.hashFunc(key)
a.buckets[index] = pair
}
/* Remove operation */
func (a *arrayHashMap) remove(key int) {
index := a.hashFunc(key)
// Set to nil to delete
a.buckets[index] = nil
}
/* Get all key pairs */
func (a *arrayHashMap) pairSet() []*pair {
var pairs []*pair
for _, pair := range a.buckets {
if pair != nil {
pairs = append(pairs, pair)
}
}
return pairs
}
/* Get all keys */
func (a *arrayHashMap) keySet() []int {
var keys []int
for _, pair := range a.buckets {
if pair != nil {
keys = append(keys, pair.key)
}
}
return keys
}
/* Get all values */
func (a *arrayHashMap) valueSet() []string {
var values []string
for _, pair := range a.buckets {
if pair != nil {
values = append(values, pair.val)
}
}
return values
}
/* Print hash table */
func (a *arrayHashMap) print() {
for _, pair := range a.buckets {
if pair != nil {
fmt.Println(pair.key, "->", pair.val)
}
}
}
/* Key-value pair */
class Pair: Equatable {
public var key: Int
public var val: String
public init(key: Int, val: String) {
self.key = key
self.val = val
}
public static func == (lhs: Pair, rhs: Pair) -> Bool {
lhs.key == rhs.key && lhs.val == rhs.val
}
}
/* Hash table based on array implementation */
class ArrayHashMap {
private var buckets: [Pair?]
init() {
// Initialize array with 100 buckets
buckets = Array(repeating: nil, count: 100)
}
/* Hash function */
private func hashFunc(key: Int) -> Int {
let index = key % 100
return index
}
/* Query operation */
func get(key: Int) -> String? {
let index = hashFunc(key: key)
let pair = buckets[index]
return pair?.val
}
/* Add operation */
func put(key: Int, val: String) {
let pair = Pair(key: key, val: val)
let index = hashFunc(key: key)
buckets[index] = pair
}
/* Remove operation */
func remove(key: Int) {
let index = hashFunc(key: key)
// Set to nil to delete
buckets[index] = nil
}
/* Get all key-value pairs */
func pairSet() -> [Pair] {
buckets.compactMap { $0 }
}
/* Get all keys */
func keySet() -> [Int] {
buckets.compactMap { $0?.key }
}
/* Get all values */
func valueSet() -> [String] {
buckets.compactMap { $0?.val }
}
/* Print hash table */
func print() {
for pair in pairSet() {
Swift.print("\(pair.key) -> \(pair.val)")
}
}
}
/* Key-value pair Number -> String */
class Pair {
constructor(key, val) {
this.key = key;
this.val = val;
}
}
/* Hash table based on array implementation */
class ArrayHashMap {
#buckets;
constructor() {
// Initialize array with 100 buckets
this.#buckets = new Array(100).fill(null);
}
/* Hash function */
#hashFunc(key) {
return key % 100;
}
/* Query operation */
get(key) {
let index = this.#hashFunc(key);
let pair = this.#buckets[index];
if (pair === null) return null;
return pair.val;
}
/* Add operation */
set(key, val) {
let index = this.#hashFunc(key);
this.#buckets[index] = new Pair(key, val);
}
/* Remove operation */
delete(key) {
let index = this.#hashFunc(key);
// Set to null to represent deletion
this.#buckets[index] = null;
}
/* Get all key-value pairs */
entries() {
let arr = [];
for (let i = 0; i < this.#buckets.length; i++) {
if (this.#buckets[i]) {
arr.push(this.#buckets[i]);
}
}
return arr;
}
/* Get all keys */
keys() {
let arr = [];
for (let i = 0; i < this.#buckets.length; i++) {
if (this.#buckets[i]) {
arr.push(this.#buckets[i].key);
}
}
return arr;
}
/* Get all values */
values() {
let arr = [];
for (let i = 0; i < this.#buckets.length; i++) {
if (this.#buckets[i]) {
arr.push(this.#buckets[i].val);
}
}
return arr;
}
/* Print hash table */
print() {
let pairSet = this.entries();
for (const pair of pairSet) {
console.info(`${pair.key} -> ${pair.val}`);
}
}
}
/* Key-value pair Number -> String */
class Pair {
public key: number;
public val: string;
constructor(key: number, val: string) {
this.key = key;
this.val = val;
}
}
/* Hash table based on array implementation */
class ArrayHashMap {
private readonly buckets: (Pair | null)[];
constructor() {
// Initialize array with 100 buckets
this.buckets = new Array(100).fill(null);
}
/* Hash function */
private hashFunc(key: number): number {
return key % 100;
}
/* Query operation */
public get(key: number): string | null {
let index = this.hashFunc(key);
let pair = this.buckets[index];
if (pair === null) return null;
return pair.val;
}
/* Add operation */
public set(key: number, val: string) {
let index = this.hashFunc(key);
this.buckets[index] = new Pair(key, val);
}
/* Remove operation */
public delete(key: number) {
let index = this.hashFunc(key);
// Set to null to represent deletion
this.buckets[index] = null;
}
/* Get all key-value pairs */
public entries(): (Pair | null)[] {
let arr: (Pair | null)[] = [];
for (let i = 0; i < this.buckets.length; i++) {
if (this.buckets[i]) {
arr.push(this.buckets[i]);
}
}
return arr;
}
/* Get all keys */
public keys(): (number | undefined)[] {
let arr: (number | undefined)[] = [];
for (let i = 0; i < this.buckets.length; i++) {
if (this.buckets[i]) {
arr.push(this.buckets[i].key);
}
}
return arr;
}
/* Get all values */
public values(): (string | undefined)[] {
let arr: (string | undefined)[] = [];
for (let i = 0; i < this.buckets.length; i++) {
if (this.buckets[i]) {
arr.push(this.buckets[i].val);
}
}
return arr;
}
/* Print hash table */
public print() {
let pairSet = this.entries();
for (const pair of pairSet) {
console.info(`${pair.key} -> ${pair.val}`);
}
}
}
/* Key-value pair */
class Pair {
int key;
String val;
Pair(this.key, this.val);
}
/* Hash table based on array implementation */
class ArrayHashMap {
late List<Pair?> _buckets;
ArrayHashMap() {
// Initialize array with 100 buckets
_buckets = List.filled(100, null);
}
/* Hash function */
int _hashFunc(int key) {
final int index = key % 100;
return index;
}
/* Query operation */
String? get(int key) {
final int index = _hashFunc(key);
final Pair? pair = _buckets[index];
if (pair == null) {
return null;
}
return pair.val;
}
/* Add operation */
void put(int key, String val) {
final Pair pair = Pair(key, val);
final int index = _hashFunc(key);
_buckets[index] = pair;
}
/* Remove operation */
void remove(int key) {
final int index = _hashFunc(key);
_buckets[index] = null;
}
/* Get all key-value pairs */
List<Pair> pairSet() {
List<Pair> pairSet = [];
for (final Pair? pair in _buckets) {
if (pair != null) {
pairSet.add(pair);
}
}
return pairSet;
}
/* Get all keys */
List<int> keySet() {
List<int> keySet = [];
for (final Pair? pair in _buckets) {
if (pair != null) {
keySet.add(pair.key);
}
}
return keySet;
}
/* Get all values */
List<String> values() {
List<String> valueSet = [];
for (final Pair? pair in _buckets) {
if (pair != null) {
valueSet.add(pair.val);
}
}
return valueSet;
}
/* Print hash table */
void printHashMap() {
for (final Pair kv in pairSet()) {
print("${kv.key} -> ${kv.val}");
}
}
}
/* Key-value pair */
#[derive(Debug, Clone, PartialEq)]
pub struct Pair {
pub key: i32,
pub val: String,
}
/* Hash table based on array implementation */
pub struct ArrayHashMap {
buckets: Vec<Option<Pair>>,
}
impl ArrayHashMap {
pub fn new() -> ArrayHashMap {
// Initialize array with 100 buckets
Self {
buckets: vec![None; 100],
}
}
/* Hash function */
fn hash_func(&self, key: i32) -> usize {
key as usize % 100
}
/* Query operation */
pub fn get(&self, key: i32) -> Option<&String> {
let index = self.hash_func(key);
self.buckets[index].as_ref().map(|pair| &pair.val)
}
/* Add operation */
pub fn put(&mut self, key: i32, val: &str) {
let index = self.hash_func(key);
self.buckets[index] = Some(Pair {
key,
val: val.to_string(),
});
}
/* Remove operation */
pub fn remove(&mut self, key: i32) {
let index = self.hash_func(key);
// Set to None to represent removal
self.buckets[index] = None;
}
/* Get all key-value pairs */
pub fn entry_set(&self) -> Vec<&Pair> {
self.buckets
.iter()
.filter_map(|pair| pair.as_ref())
.collect()
}
/* Get all keys */
pub fn key_set(&self) -> Vec<&i32> {
self.buckets
.iter()
.filter_map(|pair| pair.as_ref().map(|pair| &pair.key))
.collect()
}
/* Get all values */
pub fn value_set(&self) -> Vec<&String> {
self.buckets
.iter()
.filter_map(|pair| pair.as_ref().map(|pair| &pair.val))
.collect()
}
/* Print hash table */
pub fn print(&self) {
for pair in self.entry_set() {
println!("{} -> {}", pair.key, pair.val);
}
}
}
/* Key-value pair int->string */
typedef struct {
int key;
char *val;
} Pair;
/* Hash table based on array implementation */
typedef struct {
Pair *buckets[MAX_SIZE];
} ArrayHashMap;
/* Constructor */
ArrayHashMap *newArrayHashMap() {
ArrayHashMap *hmap = malloc(sizeof(ArrayHashMap));
for (int i=0; i < MAX_SIZE; i++) {
hmap->buckets[i] = NULL;
}
return hmap;
}
/* Destructor */
void delArrayHashMap(ArrayHashMap *hmap) {
for (int i = 0; i < MAX_SIZE; i++) {
if (hmap->buckets[i] != NULL) {
free(hmap->buckets[i]->val);
free(hmap->buckets[i]);
}
}
free(hmap);
}
/* Add operation */
void put(ArrayHashMap *hmap, const int key, const char *val) {
Pair *Pair = malloc(sizeof(Pair));
Pair->key = key;
Pair->val = malloc(strlen(val) + 1);
strcpy(Pair->val, val);
int index = hashFunc(key);
hmap->buckets[index] = Pair;
}
/* Remove operation */
void removeItem(ArrayHashMap *hmap, const int key) {
int index = hashFunc(key);
free(hmap->buckets[index]->val);
free(hmap->buckets[index]);
hmap->buckets[index] = NULL;
}
/* Get all key-value pairs */
void pairSet(ArrayHashMap *hmap, MapSet *set) {
Pair *entries;
int i = 0, index = 0;
int total = 0;
/* Count valid key-value pairs */
for (i = 0; i < MAX_SIZE; i++) {
if (hmap->buckets[i] != NULL) {
total++;
}
}
entries = malloc(sizeof(Pair) * total);
for (i = 0; i < MAX_SIZE; i++) {
if (hmap->buckets[i] != NULL) {
entries[index].key = hmap->buckets[i]->key;
entries[index].val = malloc(strlen(hmap->buckets[i]->val) + 1);
strcpy(entries[index].val, hmap->buckets[i]->val);
index++;
}
}
set->set = entries;
set->len = total;
}
/* Get all keys */
void keySet(ArrayHashMap *hmap, MapSet *set) {
int *keys;
int i = 0, index = 0;
int total = 0;
/* Count valid key-value pairs */
for (i = 0; i < MAX_SIZE; i++) {
if (hmap->buckets[i] != NULL) {
total++;
}
}
keys = malloc(total * sizeof(int));
for (i = 0; i < MAX_SIZE; i++) {
if (hmap->buckets[i] != NULL) {
keys[index] = hmap->buckets[i]->key;
index++;
}
}
set->set = keys;
set->len = total;
}
/* Get all values */
void valueSet(ArrayHashMap *hmap, MapSet *set) {
char **vals;
int i = 0, index = 0;
int total = 0;
/* Count valid key-value pairs */
for (i = 0; i < MAX_SIZE; i++) {
if (hmap->buckets[i] != NULL) {
total++;
}
}
vals = malloc(total * sizeof(char *));
for (i = 0; i < MAX_SIZE; i++) {
if (hmap->buckets[i] != NULL) {
vals[index] = hmap->buckets[i]->val;
index++;
}
}
set->set = vals;
set->len = total;
}
/* Print hash table */
void print(ArrayHashMap *hmap) {
int i;
MapSet set;
pairSet(hmap, &set);
Pair *entries = (Pair *)set.set;
for (i = 0; i < set.len; i++) {
printf("%d -> %s\n", entries[i].key, entries[i].val);
}
free(set.set);
}
/* Key-value pair */
class Pair(
var key: Int,
var _val: String
)
/* Hash table based on array implementation */
class ArrayHashMap {
// Initialize array with 100 buckets
private val buckets = arrayOfNulls<Pair>(100)
/* Hash function */
fun hashFunc(key: Int): Int {
val index = key % 100
return index
}
/* Query operation */
fun get(key: Int): String? {
val index = hashFunc(key)
val pair = buckets[index] ?: return null
return pair._val
}
/* Add operation */
fun put(key: Int, _val: String) {
val pair = Pair(key, _val)
val index = hashFunc(key)
buckets[index] = pair
}
/* Remove operation */
fun remove(key: Int) {
val index = hashFunc(key)
// Set to null to represent deletion
buckets[index] = null
}
/* Get all key-value pairs */
fun pairSet(): MutableList<Pair> {
val pairSet = mutableListOf<Pair>()
for (pair in buckets) {
if (pair != null)
pairSet.add(pair)
}
return pairSet
}
/* Get all keys */
fun keySet(): MutableList<Int> {
val keySet = mutableListOf<Int>()
for (pair in buckets) {
if (pair != null)
keySet.add(pair.key)
}
return keySet
}
/* Get all values */
fun valueSet(): MutableList<String> {
val valueSet = mutableListOf<String>()
for (pair in buckets) {
if (pair != null)
valueSet.add(pair._val)
}
return valueSet
}
/* Print hash table */
fun print() {
for (kv in pairSet()) {
val key = kv.key
val _val = kv._val
println("$key -> $_val")
}
}
}
### Key-value pair ###
class Pair
attr_accessor :key, :val
def initialize(key, val)
@key = key
@val = val
end
end
### Hash map based on array ###
class ArrayHashMap
### Constructor ###
def initialize
# Initialize array with 100 buckets
@buckets = Array.new(100)
end
### Hash function ###
def hash_func(key)
index = key % 100
end
### Query operation ###
def get(key)
index = hash_func(key)
pair = @buckets[index]
return if pair.nil?
pair.val
end
### Add operation ###
def put(key, val)
pair = Pair.new(key, val)
index = hash_func(key)
@buckets[index] = pair
end
### Delete operation ###
def remove(key)
index = hash_func(key)
# Set to nil to delete
@buckets[index] = nil
end
### Get all key-value pairs ###
def entry_set
result = []
@buckets.each { |pair| result << pair unless pair.nil? }
result
end
### Get all keys ###
def key_set
result = []
@buckets.each { |pair| result << pair.key unless pair.nil? }
result
end
### Get all values ###
def value_set
result = []
@buckets.each { |pair| result << pair.val unless pair.nil? }
result
end
### Print hash table ###
def print
@buckets.each { |pair| puts "#{pair.key} -> #{pair.val}" unless pair.nil? }
end
end
6.1.3 Hash Collision and Resizing¶
Fundamentally, a hash function maps the input space consisting of all keys to the output space consisting of all array indices, and the input space is often much larger than the output space. Therefore, in theory, different inputs must sometimes map to the same output.
For the hash function in the above example, when the input keys have the same last two digits, the hash function produces the same output. For example, when querying two students with IDs 12836 and 20336, we get:
As shown below, two student IDs now point to the same name, which is clearly incorrect. We call this situation, where multiple inputs map to the same output, a hash collision.
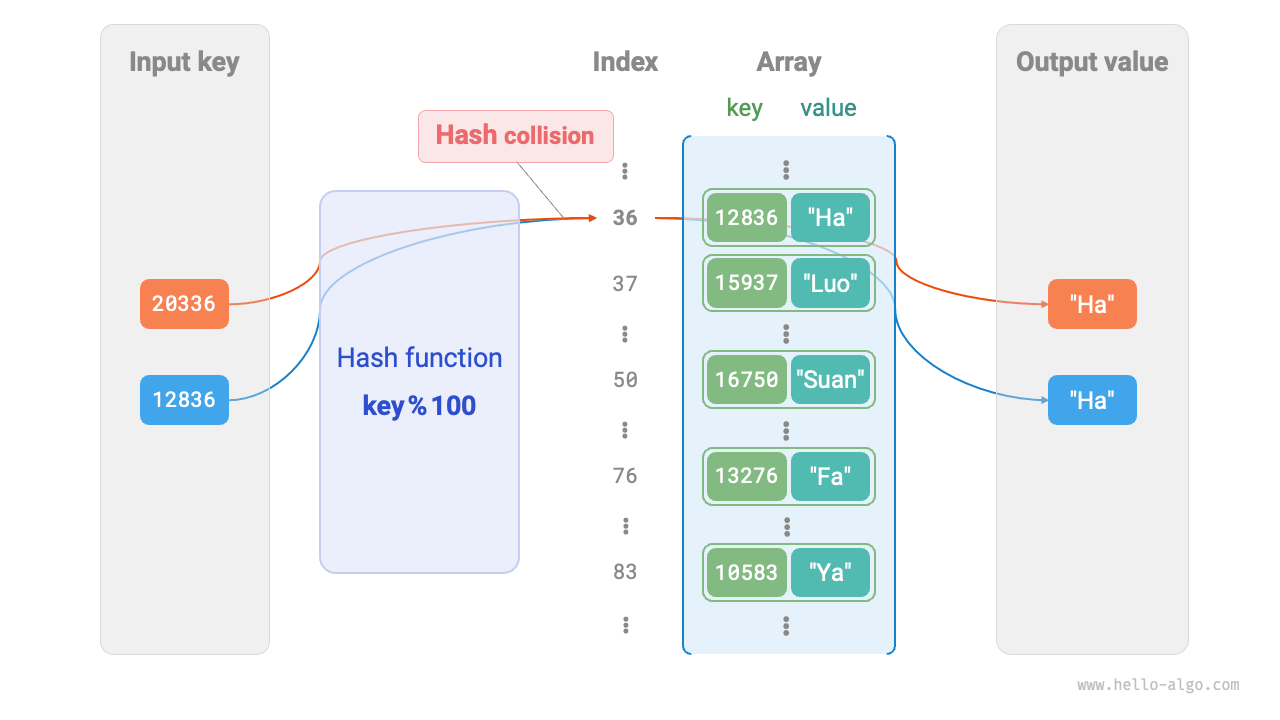
Figure 6-3 Hash collision example
It's easy to see that the larger the hash table capacity \(n\), the lower the probability that multiple keys will be assigned to the same bucket, and the fewer collisions. Therefore, we can reduce hash collisions by expanding the hash table.
As shown in Figure 6-4, before expansion, the key-value pairs (136, A) and (236, D) collided, but after expansion, the collision disappears.

Figure 6-4 Hash table resizing
Like resizing an array, resizing a hash table requires migrating all key-value pairs from the original table to the new table, which is expensive. In addition, because the hash table capacity capacity changes, we must recompute the storage location of every key-value pair using the hash function, which further increases the cost of resizing. For this reason, programming languages typically reserve a sufficiently large hash table capacity to avoid frequent resizing.
The load factor is an important concept in hash tables. It is defined as the number of elements in the hash table divided by the number of buckets and is used to measure the severity of hash collisions. It is also commonly used as a threshold for triggering hash table resizing. For example, in Java, when the load factor exceeds \(0.75\), the system expands the hash table to twice its original size.